 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Emptiness: De-biasing Listwise Rerankers with Content-Agnostic Probability Calibration
Apr 11, 2026Generative listwise reranking leverages global context for superior retrieval but is plagued by intrinsic position bias, where models exhibit structural sensitivity to input order independent of relevance. Existing mitigations present a dilemma: inference-time aggregation incurs prohibitive latency, while training-based methods often fail to eradicate ingrained priors, particularly in compact models. To resolve this dilemma, we propose CapCal (Content-Agnostic Probability Calibration), a training-free framework that mechanically decouples positional bias from ranking decisions. By estimating the bias distribution via content-free placeholders, CapCal rectifies output logits through an entropy-adaptive contrastive mechanism. Evaluations across 10 benchmarks confirm that CapCal achieves superior performance among training-free methods while preserving single-pass efficiency. Notably, it unlocks the latent potential of lightweight models (e.g., 0.6B), delivering absolute NDCG gains exceeding 10 points and outperforming both permutation-based aggregation and data-augmentation baselines.
SSKG Hub: An Expert-Guided Platform for LLM-Empowered Sustainability Standards Knowledge Graphs
Feb 28, 2026Sustainability disclosure standards (e.g., GRI, SASB, TCFD, IFRS S2) are comprehensive yet lengthy, terminology-dense, and highly cross-referential, hindering structured analysis and downstream use. We present SSKG Hub (Sustainability Standards Knowledge Graph Hub), a research prototype and interactive web platform that transforms standards into auditable knowledge graphs (KGs) through an LLM-centered, expert-guided pipeline. The system integrates automatic standard identification, configurable chunking, standard-specific prompting, robust triple parsing, and provenance-aware Neo4j storage with fine-grained audit metadata. LLM extraction produces a provenance-linked Draft KG, which is reviewed, curated, and formally promoted to a Certified KG through meta-expert adjudication. A role-based governance framework covering read-only guest access, expert review and CRUD operations, meta-expert certification, and administrative oversight ensures traceability and accountability across draft and certified states. Beyond graph exploration and triple-level evidence tracing, SSKG Hub supports cross-KG fusion, KG-driven tasks, and dedicated modules for insights and curated resources. We validate the platform through a comprehensive expert-led KG review case study that demonstrates end-to-end curation and quality assurance. The web application is publicly available at www.sskg-hub.com.
Why Thinking Hurts? Diagnosing and Rectifying the Reasoning Shift in Foundation Recommender Models
Feb 18, 2026Integrating Chain-of-Thought (CoT) reasoning into Semantic ID-based recommendation foundation models (such as OpenOneRec) often paradoxically degrades recommendation performance. We identify the root cause as textual inertia from the General Subspace, where verbose reasoning dominates inference and causes the model to neglect critical Semantic ID. To address this, we propose a training-free Inference-Time Subspace Alignment framework. By compressing reasoning chains and applying bias-subtracted contrastive decoding, our approach mitigates ungrounded textual drift. Experiments show this effectively calibrates inference, allowing foundation models to leverage reasoning without sacrificing ID-grounded accuracy.
MERIT: A Merchant Incentive Ranking Model for Hotel Search & Ranking
Jun 10, 2025Online Travel Platforms (OTPs) have been working on improving their hotel Search & Ranking (S&R) systems that facilitate efficient matching between consumers and hotels. Existing OTPs focus almost exclusively on improving platform revenue. In this work, we take a first step in incorporating hotel merchants' objectives into the design of hotel S&R systems to achieve an incentive loop: the OTP tilts impressions and better-ranked positions to merchants with high quality, and in return, the merchants provide better service to consumers. Three critical design challenges need to be resolved to achieve this incentive loop: Matthew Effect in the consumer feedback-loop, unclear relation between hotel quality and performance, and conflicts between short-term and long-term revenue. To address these challenges, we propose MERIT, a MERchant IncenTive ranking model, which can simultaneously take the interests of merchants and consumers into account. We define a new Merchant Competitiveness Index (MCI) to represent hotel merchant quality and propose a new Merchant Tower to model the relation between MCI and ranking scores. Also, we design a monotonic structure for Merchant Tower to provide a clear relation between hotel quality and performance. Finally, we propose a Multi-objective Stratified Pairwise Loss, which can mitigate the conflicts between OTP's short-term and long-term revenue. The offline experiment results indicate that MERIT outperforms these methods in optimizing the demands of consumers and merchants. Furthermore, we conduct an online A/B test and obtain an improvement of 3.02% for the MCI score.
Think Thrice Before You Act: Progressive Thought Refinement in Large Language Models
Oct 17, 2024



Recent advancements in large language models (LLMs) have demonstrated that progressive refinement, rather than providing a single answer, results in more accurate and thoughtful outputs. However, existing methods often rely heavily on supervision signals to evaluate previous responses, making it difficult to assess output quality in more open-ended scenarios effectively. Additionally, these methods are typically designed for specific tasks, which limits their generalization to new domains. To address these limitations, we propose Progressive Thought Refinement (PTR), a framework that enables LLMs to refine their responses progressively. PTR operates in two phases: (1) Thought data construction stage: We propose a weak and strong model collaborative selection strategy to build a high-quality progressive refinement dataset to ensure logical consistency from thought to answers, and the answers are gradually refined in each round. (2) Thought-Mask Fine-Tuning Phase: We design a training structure to mask the "thought" and adjust loss weights to encourage LLMs to refine prior thought, teaching them to implicitly understand "how to improve" rather than "what is correct." Experimental results show that PTR significantly enhances LLM performance across ten diverse tasks (avg. from 49.6% to 53.5%) without task-specific fine-tuning. Notably, in more open-ended tasks, LLMs also demonstrate substantial improvements in the quality of responses beyond mere accuracy, suggesting that PTR truly teaches LLMs to self-improve over time.
Retrieval-style In-Context Learning for Few-shot Hierarchical Text Classification
Jun 25, 2024Hierarchical text classification (HTC) is an important task with broad applications, while few-shot HTC has gained increasing interest recently. While in-context learning (ICL) with large language models (LLMs) has achieved significant success in few-shot learning, it is not as effective for HTC because of the expansive hierarchical label sets and extremely-ambiguous labels. In this work, we introduce the first ICL-based framework with LLM for few-shot HTC. We exploit a retrieval database to identify relevant demonstrations, and an iterative policy to manage multi-layer hierarchical labels. Particularly, we equip the retrieval database with HTC label-aware representations for the input texts, which is achieved by continual training on a pretrained language model with masked language modeling (MLM), layer-wise classification (CLS, specifically for HTC), and a novel divergent contrastive learning (DCL, mainly for adjacent semantically-similar labels) objective. Experimental results on three benchmark datasets demonstrate superior performance of our method, and we can achieve state-of-the-art results in few-shot HTC.
Exploring User Retrieval Integration towards Large Language Models for Cross-Domain Sequential Recommendation
Jun 05, 2024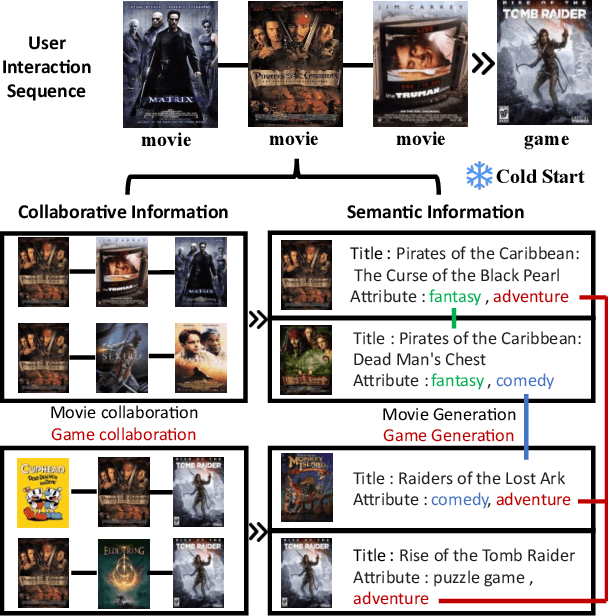
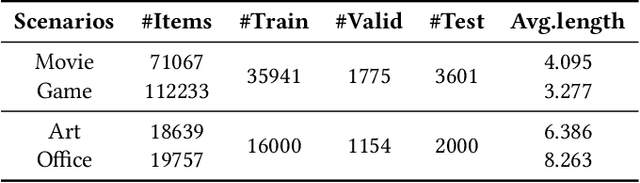
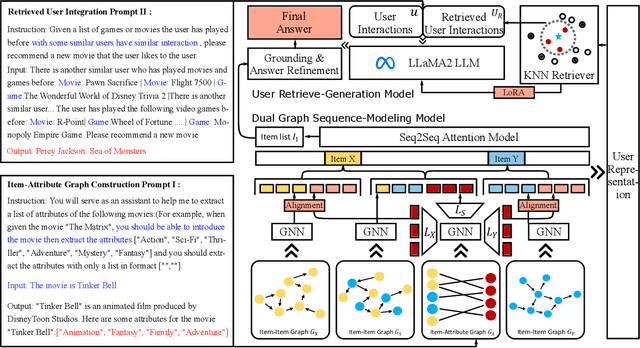
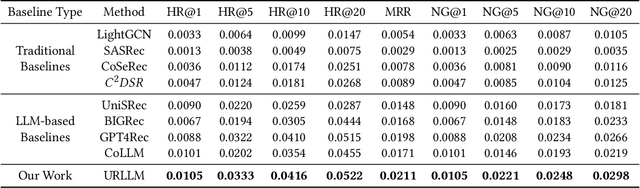
Cross-Domain Sequential Recommendation (CDSR) aims to mine and transfer users' sequential preferences across different domains to alleviate the long-standing cold-start issue. Traditional CDSR models capture collaborative information through user and item modeling while overlooking valuable semantic information. Recently, Large Language Model (LLM) has demonstrated powerful semantic reasoning capabilities, motivating us to introduce them to better capture semantic information. However, introducing LLMs to CDSR is non-trivial due to two crucial issues: seamless information integration and domain-specific generation. To this end, we propose a novel framework named URLLM, which aims to improve the CDSR performance by exploring the User Retrieval approach and domain grounding on LLM simultaneously. Specifically, we first present a novel dual-graph sequential model to capture the diverse information, along with an alignment and contrastive learning method to facilitate domain knowledge transfer. Subsequently, a user retrieve-generation model is adopted to seamlessly integrate the structural information into LLM, fully harnessing its emergent inferencing ability. Furthermore, we propose a domain-specific strategy and a refinement module to prevent out-of-domain generation. Extensive experiments on Amazon demonstrated the information integration and domain-specific generation ability of URLLM in comparison to state-of-the-art baselines. Our code is available at https://github.com/TingJShen/URLLM
Side Information-Driven Session-based Recommendation: A Survey
Feb 27, 2024


The session-based recommendation (SBR) garners increasing attention due to its ability to predict anonymous user intents within limited interactions. Emerging efforts incorporate various kinds of side information into their methods for enhancing task performance. In this survey, we thoroughly review the side information-driven session-based recommendation from a data-centric perspective. Our survey commences with an illustration of the motivation and necessity behind this research topic. This is followed by a detailed exploration of various benchmarks rich in side information, pivotal for advancing research in this field. Moreover, we delve into how these diverse types of side information enhance SBR, underscoring their characteristics and utility. A systematic review of research progress is then presented, offering an analysis of the most recent and representative developments within this topic. Finally, we present the future prospects of this vibrant topic.
Modeling User Viewing Flow using Large Language Models for Article Recommendation
Nov 12, 2023



This paper proposes the User Viewing Flow Modeling (SINGLE) method for the article recommendation task, which models the user constant preference and instant interest from user-clicked articles. Specifically, we employ a user constant viewing flow modeling method to summarize the user's general interest to recommend articles. We utilize Large Language Models (LLMs) to capture constant user preferences from previously clicked articles, such as skills and positions. Then we design the user instant viewing flow modeling method to build interactions between user-clicked article history and candidate articles. It attentively reads the representations of user-clicked articles and aims to learn the user's different interest views to match the candidate article. Our experimental results on the Alibaba Technology Association (ATA) website show the advantage of SINGLE, which achieves 2.4% improvements over previous baseline models in the online A/B test. Our further analyses illustrate that SINGLE has the ability to build a more tailored recommendation system by mimicking different article viewing behaviors of users and recommending more appropriate and diverse articles to match user interests.
Learning Optimal Propagation for Graph Neural Networks
May 06, 2022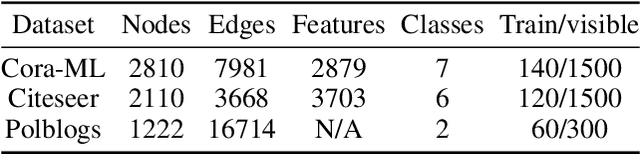
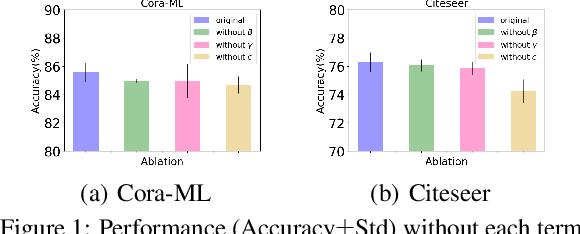
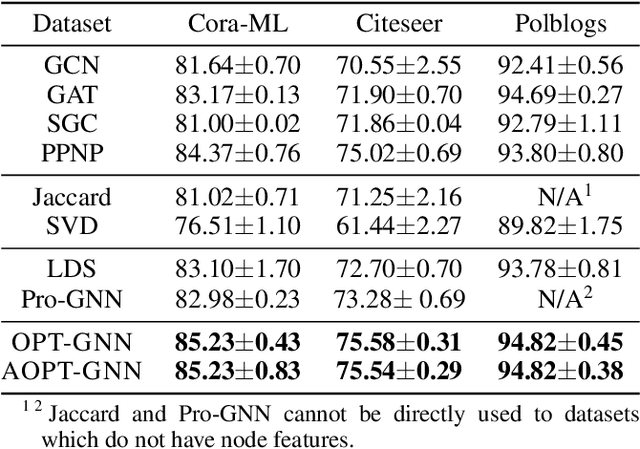
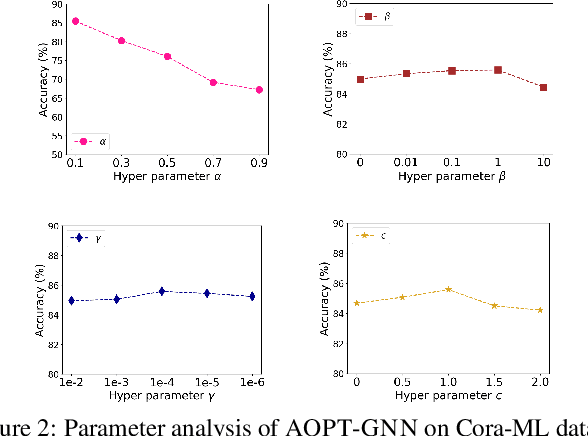
Graph Neural Networks (GNNs) have achieved tremendous success in a variety of real-world applications by relying on the fixed graph data as input. However, the initial input graph might not be optimal in terms of specific downstream tasks, because of information scarcity, noise, adversarial attacks, or discrepancies between the distribution in graph topology, features, and groundtruth labels. In this paper, we propose a bi-level optimization-based approach for learning the optimal graph structure via directly learning the Personalized PageRank propagation matrix as well as the downstream semi-supervised node classification simultaneously. We also explore a low-rank approximation model for further reducing the time complexity. Empirical evaluations show the superior efficacy and robustness of the proposed model over all baseline methods.