 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Child is Father of the Man: Foresee the Success at the Early Stage
Paper and Code
Aug 01, 2015
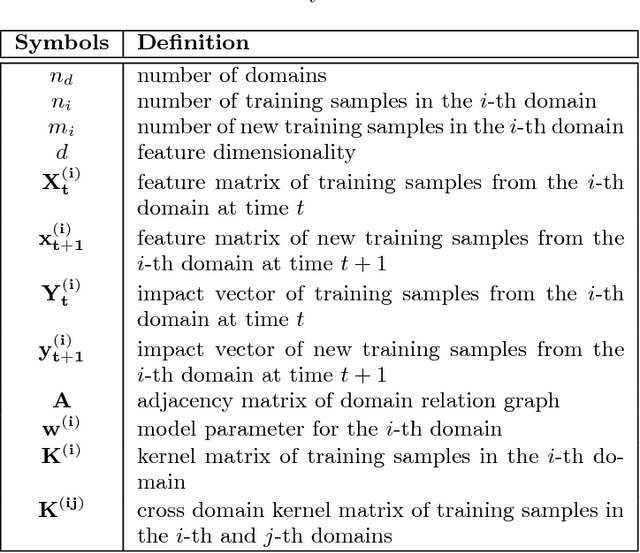
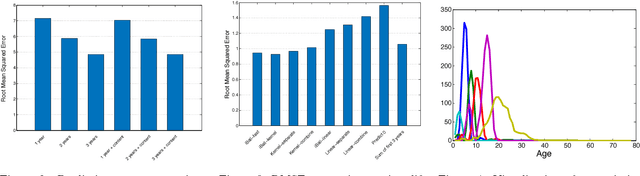
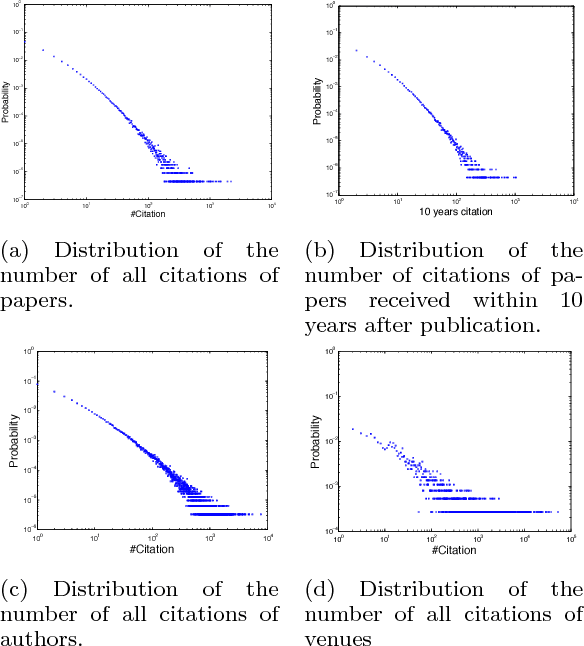
Understanding the dynamic mechanisms that drive the high-impact scientific work (e.g., research papers, patents) is a long-debated research topic and has many important implications, ranging from personal career development and recruitment search, to the jurisdiction of research resources. Recent advances in characterizing and modeling scientific success have made it possible to forecast the long-term impact of scientific work, where data mining techniques, supervised learning in particular, play an essential role. Despite much progress, several key algorithmic challenges in relation to predicting long-term scientific impact have largely remained open. In this paper, we propose a joint predictive model to forecast the long-term scientific impact at the early stage, which simultaneously addresses a number of these open challenges, including the scholarly feature design, the non-linearity, the domain-heterogeneity and dynamics. In particular, we formulate it as a regularized optimization problem and propose effective and scalable algorithms to solve it. We perform extensive empirical evaluations on large, real scholarly data sets to validate the effectiveness and the efficiency of our method.