 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking with Adaptive Neighbors
Mar 14, 2018
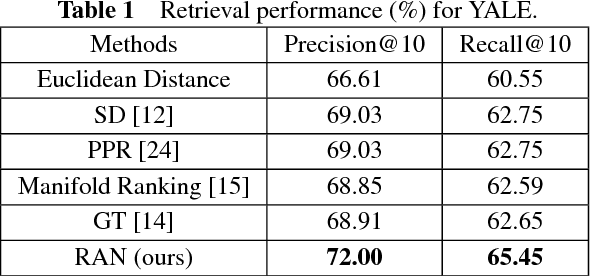


Retrieving the most similar objects in a large-scale database for a given query is a fundamental building block in many application domains, ranging from web searches, visual, cross media, and document retrievals. State-of-the-art approaches have mainly focused on capturing the underlying geometry of the data manifolds. Graph-based approaches, in particular, define various diffusion processes on weighted data graphs. Despite success, these approaches rely on fixed-weight graphs, making ranking sensitive to the input affinity matrix. In this study, we propose a new ranking algorithm that simultaneously learns the data affinity matrix and the ranking scores. The proposed optimization formulation assigns adaptive neighbors to each point in the data based on the local connectivity, and the smoothness constraint assigns similar ranking scores to similar data points. We develop a novel and efficient algorithm to solve the optimization problem. Evaluations using synthetic and real datasets suggest that the proposed algorithm can outperform the existing methods.