 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSRec: Enhancing Repeat-Aware Recommendation from a Temporal-Sequential Perspective
Jun 10, 2025Repeat consumption, such as repurchasing items and relistening songs, is a common scenario in daily life. To model repeat consumption, the repeat-aware recommendation has been proposed to predict which item will be re-interacted based on the user-item interactions. In this paper, we investigate various inherent characteristics to enhance the repeat-aware recommendation. Specifically, we explore these characteristics from two aspects: one is from the temporal aspect where we consider the time interval relationship in the user behavior sequence; the other is from the sequential aspect where we consider the sequential-level relationship in the user behavior sequence. And our intuition is that both the temporal pattern and sequential pattern will reflect users' intentions of repeat consumption. By utilizing these two patterns, a novel model called Temporal and Sequential repeat-aware Recommendation(TSRec for short) is proposed to enhance repeat-aware recommendation. TSRec has three main components: 1) User-specific Temporal Representation Module (UTRM), which encodes and extracts user historical repeat temporal information. 2)Item-specific Temporal Representation Module (ITRM), which incorporates item time interval information as side information to alleviate the data sparsity problem of user repeat behavior sequence. 3) Sequential Repeat-Aware Module (SRAM), which represents the similarity between the user's current and the last repeat sequences. Extensive experimental results on three public benchmarks demonstrate the superiority of TSRec over state-of-the-art methods. The implementation code is available https://anonymous.4open.science/r/TSRec-2306/.
MERIT: A Merchant Incentive Ranking Model for Hotel Search & Ranking
Jun 10, 2025Online Travel Platforms (OTPs) have been working on improving their hotel Search & Ranking (S&R) systems that facilitate efficient matching between consumers and hotels. Existing OTPs focus almost exclusively on improving platform revenue. In this work, we take a first step in incorporating hotel merchants' objectives into the design of hotel S&R systems to achieve an incentive loop: the OTP tilts impressions and better-ranked positions to merchants with high quality, and in return, the merchants provide better service to consumers. Three critical design challenges need to be resolved to achieve this incentive loop: Matthew Effect in the consumer feedback-loop, unclear relation between hotel quality and performance, and conflicts between short-term and long-term revenue. To address these challenges, we propose MERIT, a MERchant IncenTive ranking model, which can simultaneously take the interests of merchants and consumers into account. We define a new Merchant Competitiveness Index (MCI) to represent hotel merchant quality and propose a new Merchant Tower to model the relation between MCI and ranking scores. Also, we design a monotonic structure for Merchant Tower to provide a clear relation between hotel quality and performance. Finally, we propose a Multi-objective Stratified Pairwise Loss, which can mitigate the conflicts between OTP's short-term and long-term revenue. The offline experiment results indicate that MERIT outperforms these methods in optimizing the demands of consumers and merchants. Furthermore, we conduct an online A/B test and obtain an improvement of 3.02% for the MCI score.
LIBER: Lifelong User Behavior Modeling Based on Large Language Models
Nov 22, 2024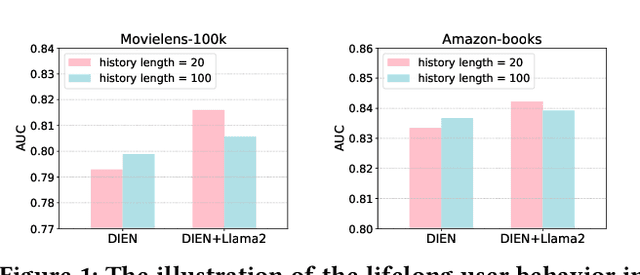
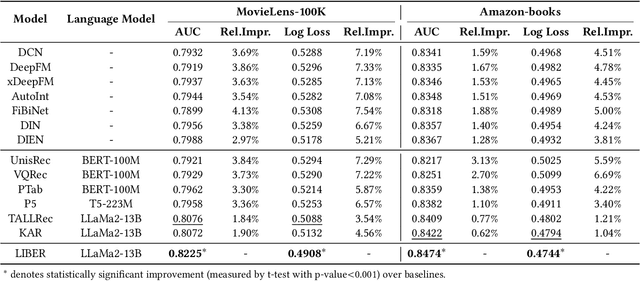
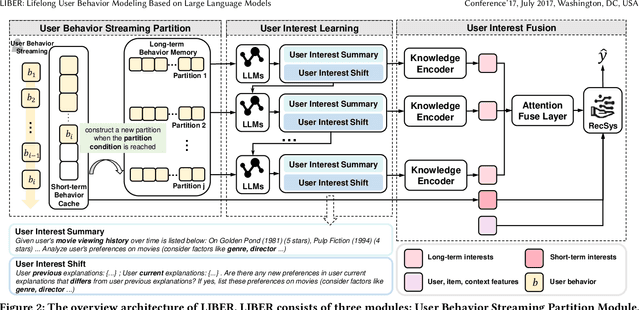
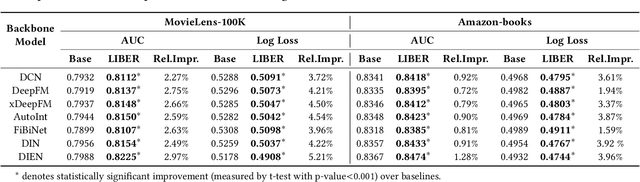
CTR prediction plays a vital role in recommender systems. Recently, large language models (LLMs) have been applied in recommender systems due to their emergence abilities. While leveraging semantic information from LLMs has shown some improvements in the performance of recommender systems, two notable limitations persist in these studies. First, LLM-enhanced recommender systems encounter challenges in extracting valuable information from lifelong user behavior sequences within textual contexts for recommendation tasks. Second, the inherent variability in human behaviors leads to a constant stream of new behaviors and irregularly fluctuating user interests. This characteristic imposes two significant challenges on existing models. On the one hand, it presents difficulties for LLMs in effectively capturing the dynamic shifts in user interests within these sequences, and on the other hand, there exists the issue of substantial computational overhead if the LLMs necessitate recurrent calls upon each update to the user sequences. In this work, we propose Lifelong User Behavior Modeling (LIBER) based on large language models, which includes three modules: (1) User Behavior Streaming Partition (UBSP), (2) User Interest Learning (UIL), and (3) User Interest Fusion (UIF). Initially, UBSP is employed to condense lengthy user behavior sequences into shorter partitions in an incremental paradigm, facilitating more efficient processing. Subsequently, UIL leverages LLMs in a cascading way to infer insights from these partitions. Finally, UIF integrates the textual outputs generated by the aforementioned processes to construct a comprehensive representation, which can be incorporated by any recommendation model to enhance performance. LIBER has been deployed on Huawei's music recommendation service and achieved substantial improvements in users' play count and play time by 3.01% and 7.69%.
ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation
Aug 22, 2023



With large language models (LLMs) achieving remarkable breakthroughs in natural language processing (NLP) domains, LLM-enhanced recommender systems have received much attention and have been actively explored currently. In this paper, we focus on adapting and empowering a pure large language model for zero-shot and few-shot recommendation tasks. First and foremost, we identify and formulate the lifelong sequential behavior incomprehension problem for LLMs in recommendation domains, i.e., LLMs fail to extract useful information from a textual context of long user behavior sequence, even if the length of context is far from reaching the context limitation of LLMs. To address such an issue and improve the recommendation performance of LLMs, we propose a novel framework, namely Retrieval-enhanced Large Language models (ReLLa) for recommendation tasks in both zero-shot and few-shot settings. For zero-shot recommendation, we perform semantic user behavior retrieval (SUBR) to improve the data quality of testing samples, which greatly reduces the difficulty for LLMs to extract the essential knowledge from user behavior sequences. As for few-shot recommendation, we further design retrieval-enhanced instruction tuning (ReiT) by adopting SUBR as a data augmentation technique for training samples. Specifically, we develop a mixed training dataset consisting of both the original data samples and their retrieval-enhanced counterparts. We conduct extensive experiments on a real-world public dataset (i.e., MovieLens-1M) to demonstrate the superiority of ReLLa compared with existing baseline models, as well as its capability for lifelong sequential behavior comprehension.