 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Process Reward Models: From Outcome Signals to Process Supervisions for Large Language Models
Oct 09, 2025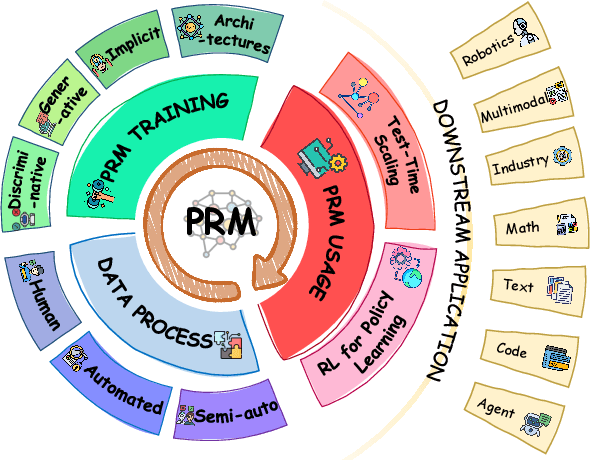

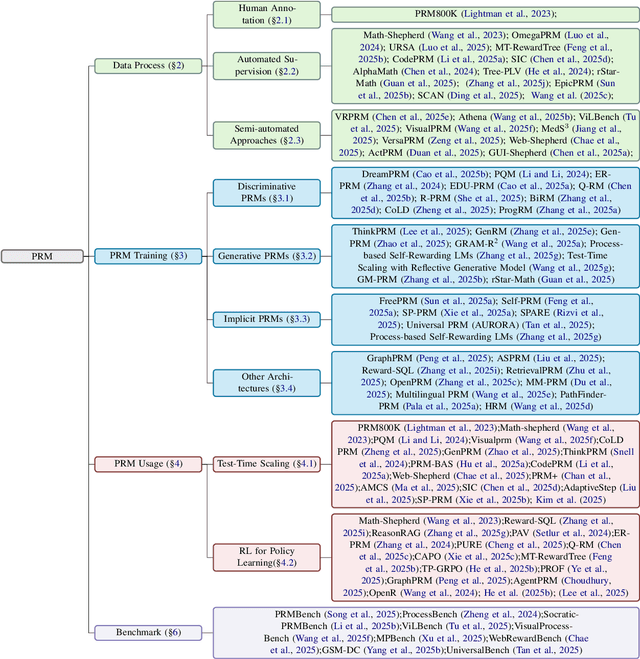
Although Large Language Models (LLMs) exhibit advanced reasoning ability, conventional alignment remains largely dominated by outcome reward models (ORMs) that judge only final answers. Process Reward Models(PRMs) address this gap by evaluating and guiding reasoning at the step or trajectory level. This survey provides a systematic overview of PRMs through the full loop: how to generate process data, build PRMs, and use PRMs for test-time scaling and reinforcement learning. We summarize applications across math, code, text, multimodal reasoning, robotics, and agents, and review emerging benchmarks. Our goal is to clarify design spaces, reveal open challenges, and guide future research toward fine-grained, robust reasoning alignment.
An Automatic Graph Construction Framework based on Large Language Models for Recommendation
Dec 24, 2024Graph neural networks (GNNs) have emerged as state-of-the-art methods to learn from graph-structured data for recommendation. However, most existing GNN-based recommendation methods focus on the optimization of model structures and learning strategies based on pre-defined graphs, neglecting the importance of the graph construction stage. Earlier works for graph construction usually rely on speciffic rules or crowdsourcing, which are either too simplistic or too labor-intensive. Recent works start to utilize large language models (LLMs) to automate the graph construction, in view of their abundant open-world knowledge and remarkable reasoning capabilities. Nevertheless, they generally suffer from two limitations: (1) invisibility of global view (e.g., overlooking contextual information) and (2) construction inefficiency. To this end, we introduce AutoGraph, an automatic graph construction framework based on LLMs for recommendation. Specifically, we first use LLMs to infer the user preference and item knowledge, which is encoded as semantic vectors. Next, we employ vector quantization to extract the latent factors from the semantic vectors. The latent factors are then incorporated as extra nodes to link the user/item nodes, resulting in a graph with in-depth global-view semantics. We further design metapath-based message aggregation to effectively aggregate the semantic and collaborative information. The framework is model-agnostic and compatible with different backbone models. Extensive experiments on three real-world datasets demonstrate the efficacy and efffciency of AutoGraph compared to existing baseline methods. We have deployed AutoGraph in Huawei advertising platform, and gain a 2.69% improvement on RPM and a 7.31% improvement on eCPM in the online A/B test. Currently AutoGraph has been used as the main trafffc model, serving hundreds of millions of people.
Lifelong Personalized Low-Rank Adaptation of Large Language Models for Recommendation
Aug 07, 2024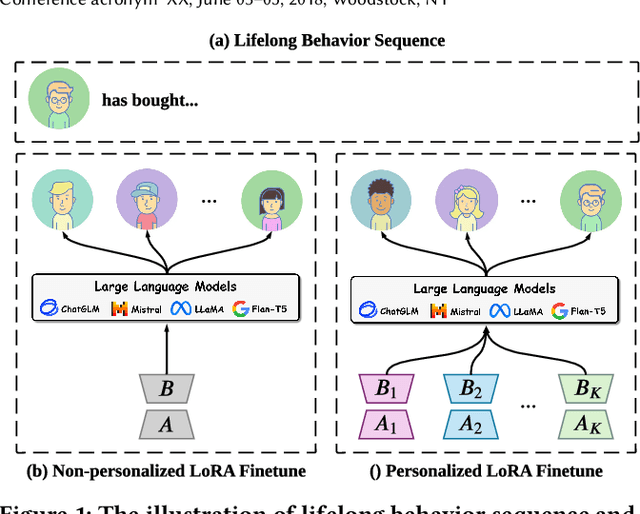
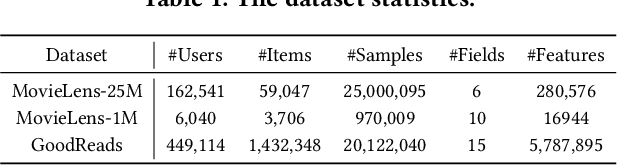

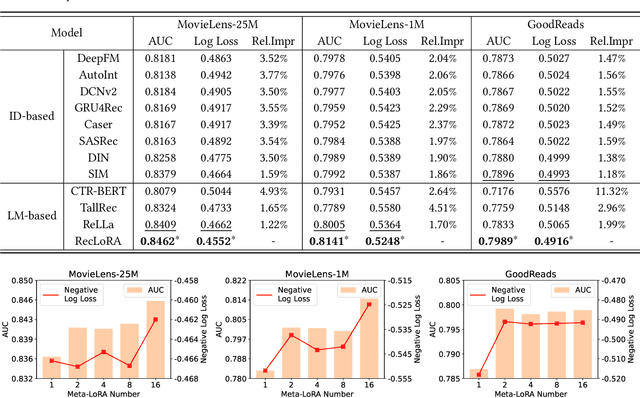
We primarily focus on the field of large language models (LLMs) for recommendation, which has been actively explored recently and poses a significant challenge in effectively enhancing recommender systems with logical reasoning abilities and open-world knowledge. Current mainstream efforts mainly center around injecting personalized information from recommendation models into LLMs by customizing input templates or aligning representations between semantic and recommendation spaces at the prediction layer. However, they face three significant limitations: (1) LoRA is mostly used as a core component in existing works, but personalization is not well established in LoRA parameters as the LoRA matrix shared by every user may not cater to different users' characteristics, leading to suboptimal performance. (2) Although lifelong personalized behavior sequences are ideal for personalization, their use raises effectiveness and efficiency issues since LLMs require escalating training and inference time to extend text lengths. (3) Existing approaches aren't scalable for large datasets due to training efficiency constraints. Thus, LLMs only see a small fraction of the datasets (e.g., less than 10%) instead of the whole datasets, limiting their exposure to the full training space. To address these problems, we propose RecLoRA. This model incorporates a Personalized LoRA module that maintains independent LoRAs for different users and a Long-Short Modality Retriever that retrieves different history lengths for different modalities, significantly improving performance while adding minimal time cost. Furthermore, we design a Few2Many Learning Strategy, using a conventional recommendation model as a lens to magnify small training spaces to full spaces. Extensive experiments on public datasets demonstrate the efficacy of our RecLoRA compared to existing baseline models.
Large Language Models Make Sample-Efficient Recommender Systems
Jun 04, 2024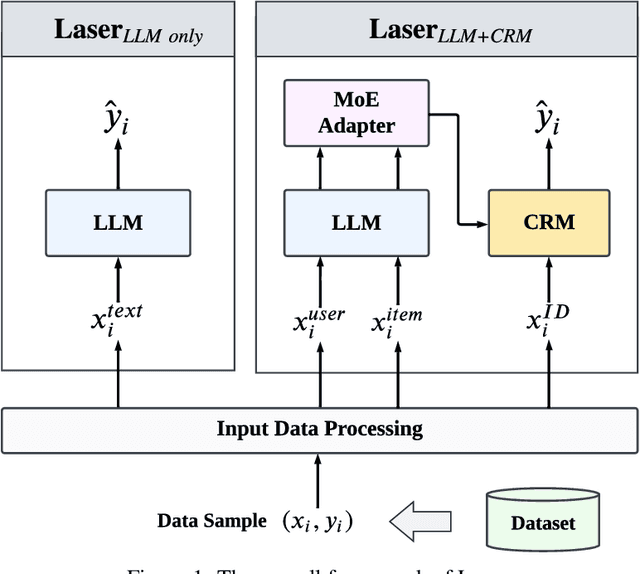


Large language models (LLMs) have achieved remarkable progress in the field of natural language processing (NLP), demonstrating remarkable abilities in producing text that resembles human language for various tasks. This opens up new opportunities for employing them in recommender systems (RSs). In this paper, we specifically examine the sample efficiency of LLM-enhanced recommender systems, which pertains to the model's capacity to attain superior performance with a limited quantity of training data. Conventional recommendation models (CRMs) often need a large amount of training data because of the sparsity of features and interactions. Hence, we propose and verify our core viewpoint: Large Language Models Make Sample-Efficient Recommender Systems. We propose a simple yet effective framework (i.e., Laser) to validate the viewpoint from two aspects: (1) LLMs themselves are sample-efficient recommenders; and (2) LLMs, as feature generators and encoders, make CRMs more sample-efficient. Extensive experiments on two public datasets show that Laser requires only a small fraction of training samples to match or even surpass CRMs that are trained on the entire training set, demonstrating superior sample efficiency.
ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation
Aug 22, 2023



With large language models (LLMs) achieving remarkable breakthroughs in natural language processing (NLP) domains, LLM-enhanced recommender systems have received much attention and have been actively explored currently. In this paper, we focus on adapting and empowering a pure large language model for zero-shot and few-shot recommendation tasks. First and foremost, we identify and formulate the lifelong sequential behavior incomprehension problem for LLMs in recommendation domains, i.e., LLMs fail to extract useful information from a textual context of long user behavior sequence, even if the length of context is far from reaching the context limitation of LLMs. To address such an issue and improve the recommendation performance of LLMs, we propose a novel framework, namely Retrieval-enhanced Large Language models (ReLLa) for recommendation tasks in both zero-shot and few-shot settings. For zero-shot recommendation, we perform semantic user behavior retrieval (SUBR) to improve the data quality of testing samples, which greatly reduces the difficulty for LLMs to extract the essential knowledge from user behavior sequences. As for few-shot recommendation, we further design retrieval-enhanced instruction tuning (ReiT) by adopting SUBR as a data augmentation technique for training samples. Specifically, we develop a mixed training dataset consisting of both the original data samples and their retrieval-enhanced counterparts. We conduct extensive experiments on a real-world public dataset (i.e., MovieLens-1M) to demonstrate the superiority of ReLLa compared with existing baseline models, as well as its capability for lifelong sequential behavior comprehension.