 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Make Sample-Efficient Recommender Systems
Paper and Code
Jun 04, 2024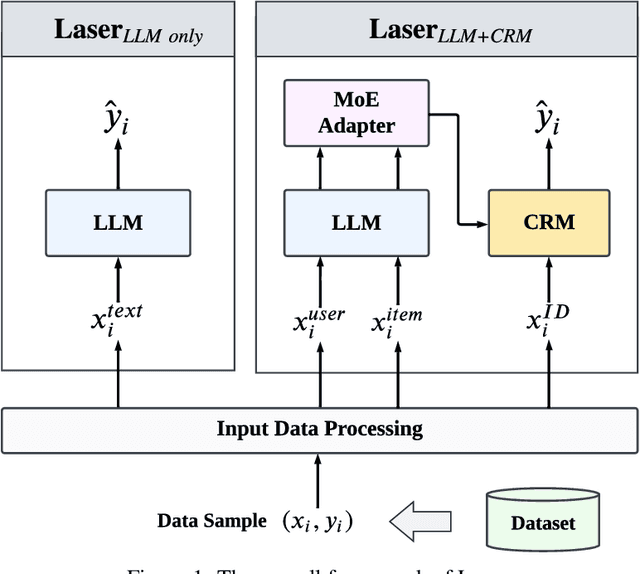


Large language models (LLMs) have achieved remarkable progress in the field of natural language processing (NLP), demonstrating remarkable abilities in producing text that resembles human language for various tasks. This opens up new opportunities for employing them in recommender systems (RSs). In this paper, we specifically examine the sample efficiency of LLM-enhanced recommender systems, which pertains to the model's capacity to attain superior performance with a limited quantity of training data. Conventional recommendation models (CRMs) often need a large amount of training data because of the sparsity of features and interactions. Hence, we propose and verify our core viewpoint: Large Language Models Make Sample-Efficient Recommender Systems. We propose a simple yet effective framework (i.e., Laser) to validate the viewpoint from two aspects: (1) LLMs themselves are sample-efficient recommenders; and (2) LLMs, as feature generators and encoders, make CRMs more sample-efficient. Extensive experiments on two public datasets show that Laser requires only a small fraction of training samples to match or even surpass CRMs that are trained on the entire training set, demonstrating superior sample efficiency.