 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall LLMs: Pruning vs. Training from Scratch
Jun 12, 2026Pruning promises a shortcut to strong small language models. In this work, we examine this promise by pruning Llama-3.1-8B at pruning ratios of 0.5--0.8 with six methods spanning depth, width, and sparse granularities, under two controlled token-matched settings. (1) With the same training token budget, pruned initialization consistently outperforms random initialization. This shows that the parent model provides a strong starting point, although the advantage narrows as the training token budget grows and as the pruning ratio rises, nearly vanishing at the highest pruning ratio we study. (2) When training from scratch is instead given the full token budget consumed by the whole pipeline, pruning at finer granularities still retains an advantage, while coarser structured pruning can be matched or surpassed. This suggests that the parent model transfers knowledge that additional training tokens alone cannot fully recover, but only at fine granularity. Taken together, our results yield a clear recommendation: with a large pretrained model in hand and a limited training token budget, pruning is better than training from scratch; when the training budget is not limited, training from scratch can be competitive for coarser pruning, so a large pretrained parent is not always necessary.
Hölder Policy Optimisation
May 12, 2026Group Relative Policy Optimisation (GRPO) enhances large language models by estimating advantages across a group of sampled trajectories. However, mapping these trajectory-level advantages to policy updates requires aggregating token-level probabilities within each sequence. Relying on a fixed aggregation mechanism for this step fundamentally limits the algorithm's adaptability. Empirically, we observe a critical trade-off: certain fixed aggregations frequently suffer from training collapse, while others fail to yield satisfactory performance. To resolve this, we propose \textbf{HölderPO}, a generalised policy optimisation framework unifying token-level probability aggregation via the Hölder mean. By explicitly modulating the parameter $p$, our framework provides continuous control over the trade-off between gradient concentration and variance bounds. Theoretically, we prove that a larger $p$ concentrates the gradient to amplify sparse learning signals, whereas a smaller $p$ strictly bounds gradient variance. Because no static configuration can universally resolve this concentration-stability trade-off, we instantiate the framework with a dynamic annealing algorithm that progressively schedules $p$ across the training lifecycle. Extensive evaluations demonstrate superior stability and convergence over existing baselines. Specifically, our approach achieves a state-of-the-art average accuracy of $54.9\%$ across multiple mathematical benchmarks, yielding a substantial $7.2\%$ relative gain over standard GRPO and secures an exceptional $93.8\%$ success rate on ALFWorld.
Position: Academic Conferences are Potentially Facing Denominator Gaming Caused by Fully Automated Scientific Agents
May 11, 2026The implicit policy of maintaining relatively stable acceptance rates at top AI conferences, despite exponentially growing submissions, introduces a critical structural vulnerability. This position paper characterizes a new systemic threat we term Agentic Denominator Gaming, in which a malicious actor deploys AI agents to generate and submit a large volume of superficially plausible but low-quality papers. Crucially, their objective is not the acceptance of low-quality papers, but rather to inflate the submission denominator and overwhelm reviewing capacity. Under a relatively stable acceptance rate, this dilution can systematically increase the publication probability of a small, targeted set of legitimate papers. We analyze the practical feasibility of this threat and its broader consequences, including intensified reviewer burnout, degraded review quality, and the emergence of industrialized automated agent mills. Finally, we propose and evaluate a range of mitigation strategies, and argue that durable protection will require system-level policy and incentive reforms, rather than relying primarily on technical detection alone.
The Spike, the Sparse and the Sink: Anatomy of Massive Activations and Attention Sinks
Mar 05, 2026We study two recurring phenomena in Transformer language models: massive activations, in which a small number of tokens exhibit extreme outliers in a few channels, and attention sinks, in which certain tokens attract disproportionate attention mass regardless of semantic relevance. Prior work observes that these phenomena frequently co-occur and often involve the same tokens, but their functional roles and causal relationship remain unclear. Through systematic experiments, we show that the co-occurrence is largely an architectural artifact of modern Transformer design, and that the two phenomena serve related but distinct functions. Massive activations operate globally: they induce near-constant hidden representations that persist across layers, effectively functioning as implicit parameters of the model. Attention sinks operate locally: they modulate attention outputs across heads and bias individual heads toward short-range dependencies. We identify the pre-norm configuration as the key choice that enables the co-occurrence, and show that ablating it causes the two phenomena to decouple.
PhotoBench: Beyond Visual Matching Towards Personalized Intent-Driven Photo Retrieval
Mar 02, 2026Personal photo albums are not merely collections of static images but living, ecological archives defined by temporal continuity, social entanglement, and rich metadata, which makes the personalized photo retrieval non-trivial. However, existing retrieval benchmarks rely heavily on context-isolated web snapshots, failing to capture the multi-source reasoning required to resolve authentic, intent-driven user queries. To bridge this gap, we introduce PhotoBench, the first benchmark constructed from authentic, personal albums. It is designed to shift the paradigm from visual matching to personalized multi-source intent-driven reasoning. Based on a rigorous multi-source profiling framework, which integrates visual semantics, spatial-temporal metadata, social identity, and temporal events for each image, we synthesize complex intent-driven queries rooted in users' life trajectories. Extensive evaluation on PhotoBench exposes two critical limitations: the modality gap, where unified embedding models collapse on non-visual constraints, and the source fusion paradox, where agentic systems perform poor tool orchestration. These findings indicate that the next frontier in personal multimodal retrieval lies beyond unified embeddings, necessitating robust agentic reasoning systems capable of precise constraint satisfaction and multi-source fusion. Our PhotoBench is available.
Adaptive Milestone Reward for GUI Agents
Feb 12, 2026Reinforcement Learning (RL) has emerged as a mainstream paradigm for training Mobile GUI Agents, yet it struggles with the temporal credit assignment problem inherent in long-horizon tasks. A primary challenge lies in the trade-off between reward fidelity and density: outcome reward offers high fidelity but suffers from signal sparsity, while process reward provides dense supervision but remains prone to bias and reward hacking. To resolve this conflict, we propose the Adaptive Milestone Reward (ADMIRE) mechanism. ADMIRE constructs a verifiable, adaptive reward system by anchoring trajectory to milestones, which are dynamically distilled from successful explorations. Crucially, ADMIRE integrates an asymmetric credit assignment strategy that denoises successful trajectories and scaffolds failed trajectories. Extensive experiments demonstrate that ADMIRE consistently yields over 10% absolute improvement in success rate across different base models on AndroidWorld. Moreover, the method exhibits robust generalizability, achieving strong performance across diverse RL algorithms and heterogeneous environments such as web navigation and embodied tasks.
CuMA: Aligning LLMs with Sparse Cultural Values via Demographic-Aware Mixture of Adapters
Jan 08, 2026As Large Language Models (LLMs) serve a global audience, alignment must transition from enforcing universal consensus to respecting cultural pluralism. We demonstrate that dense models, when forced to fit conflicting value distributions, suffer from \textbf{Mean Collapse}, converging to a generic average that fails to represent diverse groups. We attribute this to \textbf{Cultural Sparsity}, where gradient interference prevents dense parameters from spanning distinct cultural modes. To resolve this, we propose \textbf{\textsc{CuMA}} (\textbf{Cu}ltural \textbf{M}ixture of \textbf{A}dapters), a framework that frames alignment as a \textbf{conditional capacity separation} problem. By incorporating demographic-aware routing, \textsc{CuMA} internalizes a \textit{Latent Cultural Topology} to explicitly disentangle conflicting gradients into specialized expert subspaces. Extensive evaluations on WorldValuesBench, Community Alignment, and PRISM demonstrate that \textsc{CuMA} achieves state-of-the-art performance, significantly outperforming both dense baselines and semantic-only MoEs. Crucially, our analysis confirms that \textsc{CuMA} effectively mitigates mean collapse, preserving cultural diversity. Our code is available at https://github.com/Throll/CuMA.
Stronger Normalization-Free Transformers
Dec 11, 2025Although normalization layers have long been viewed as indispensable components of deep learning architectures, the recent introduction of Dynamic Tanh (DyT) has demonstrated that alternatives are possible. The point-wise function DyT constrains extreme values for stable convergence and reaches normalization-level performance; this work seeks further for function designs that can surpass it. We first study how the intrinsic properties of point-wise functions influence training and performance. Building on these findings, we conduct a large-scale search for a more effective function design. Through this exploration, we introduce $\mathrm{Derf}(x) = \mathrm{erf}(αx + s)$, where $\mathrm{erf}(x)$ is the rescaled Gaussian cumulative distribution function, and identify it as the most performant design. Derf outperforms LayerNorm, RMSNorm, and DyT across a wide range of domains, including vision (image recognition and generation), speech representation, and DNA sequence modeling. Our findings suggest that the performance gains of Derf largely stem from its improved generalization rather than stronger fitting capacity. Its simplicity and stronger performance make Derf a practical choice for normalization-free Transformer architectures.
A Survey of Process Reward Models: From Outcome Signals to Process Supervisions for Large Language Models
Oct 09, 2025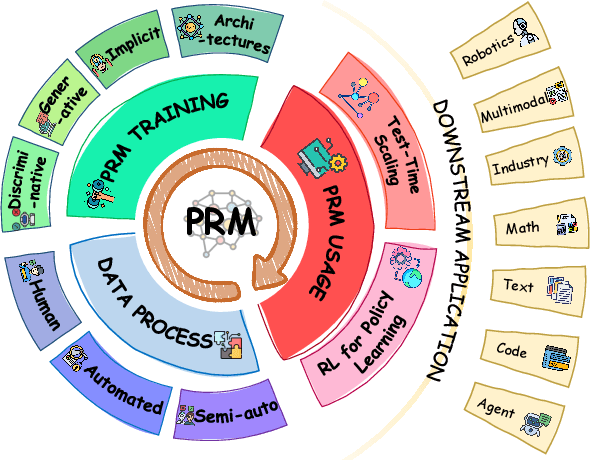

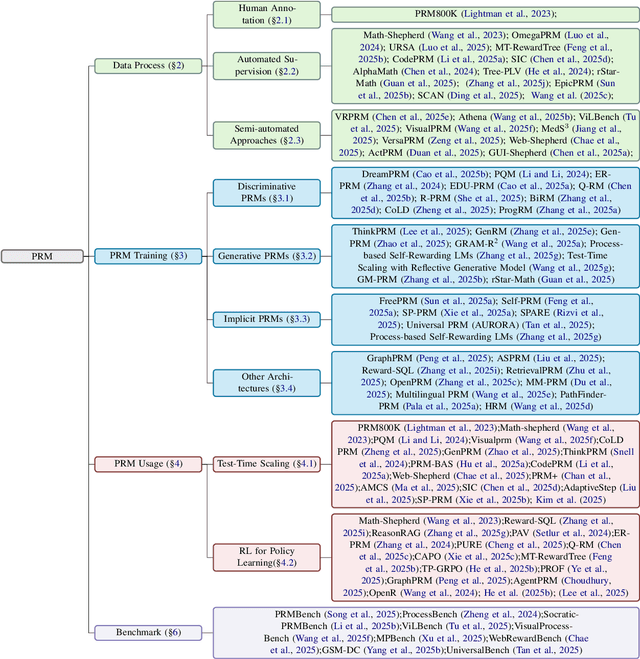
Although Large Language Models (LLMs) exhibit advanced reasoning ability, conventional alignment remains largely dominated by outcome reward models (ORMs) that judge only final answers. Process Reward Models(PRMs) address this gap by evaluating and guiding reasoning at the step or trajectory level. This survey provides a systematic overview of PRMs through the full loop: how to generate process data, build PRMs, and use PRMs for test-time scaling and reinforcement learning. We summarize applications across math, code, text, multimodal reasoning, robotics, and agents, and review emerging benchmarks. Our goal is to clarify design spaces, reveal open challenges, and guide future research toward fine-grained, robust reasoning alignment.
Superplatforms Have to Attack AI Agents
May 23, 2025Over the past decades, superplatforms, digital companies that integrate a vast range of third-party services and applications into a single, unified ecosystem, have built their fortunes on monopolizing user attention through targeted advertising and algorithmic content curation. Yet the emergence of AI agents driven by large language models (LLMs) threatens to upend this business model. Agents can not only free user attention with autonomy across diverse platforms and therefore bypass the user-attention-based monetization, but might also become the new entrance for digital traffic. Hence, we argue that superplatforms have to attack AI agents to defend their centralized control of digital traffic entrance. Specifically, we analyze the fundamental conflict between user-attention-based monetization and agent-driven autonomy through the lens of our gatekeeping theory. We show how AI agents can disintermediate superplatforms and potentially become the next dominant gatekeepers, thereby forming the urgent necessity for superplatforms to proactively constrain and attack AI agents. Moreover, we go through the potential technologies for superplatform-initiated attacks, covering a brand-new, unexplored technical area with unique challenges. We have to emphasize that, despite our position, this paper does not advocate for adversarial attacks by superplatforms on AI agents, but rather offers an envisioned trend to highlight the emerging tensions between superplatforms and AI agents. Our aim is to raise awareness and encourage critical discussion for collaborative solutions, prioritizing user interests and perserving the openness of digital ecosystems in the age of AI agents.