 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemento-Skills: Let Agents Design Agents
Mar 19, 2026We introduce \emph{Memento-Skills}, a generalist, continually-learnable LLM agent system that functions as an \emph{agent-designing agent}: it autonomously constructs, adapts, and improves task-specific agents through experience. The system is built on a memory-based reinforcement learning framework with \emph{stateful prompts}, where reusable skills (stored as structured markdown files) serve as persistent, evolving memory. These skills encode both behaviour and context, enabling the agent to carry forward knowledge across interactions. Starting from simple elementary skills (like Web search and terminal operations), the agent continually improves via the \emph{Read--Write Reflective Learning} mechanism introduced in \emph{Memento~2}~\cite{wang2025memento2}. In the \emph{read} phase, a behaviour-trainable skill router selects the most relevant skill conditioned on the current stateful prompt; in the \emph{write} phase, the agent updates and expands its skill library based on new experience. This closed-loop design enables \emph{continual learning without updating LLM parameters}, as all adaptation is realised through the evolution of externalised skills and prompts. Unlike prior approaches that rely on human-designed agents, Memento-Skills enables a generalist agent to \emph{design agents end-to-end} for new tasks. Through iterative skill generation and refinement, the system progressively improves its own capabilities. Experiments on the \emph{General AI Assistants} benchmark and \emph{Humanity's Last Exam} demonstrate sustained gains, achieving 26.2\% and 116.2\% relative improvements in overall accuracy, respectively. Code is available at https://github.com/Memento-Teams/Memento-Skills.
Causal Sufficiency and Necessity Improves Chain-of-Thought Reasoning
Jun 11, 2025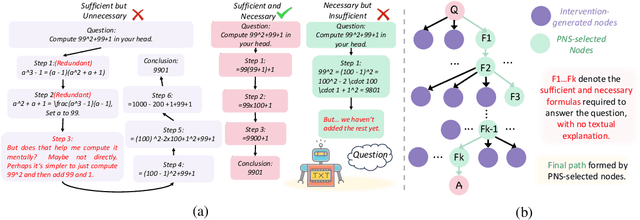
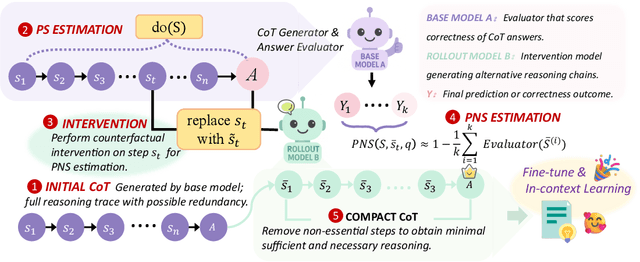
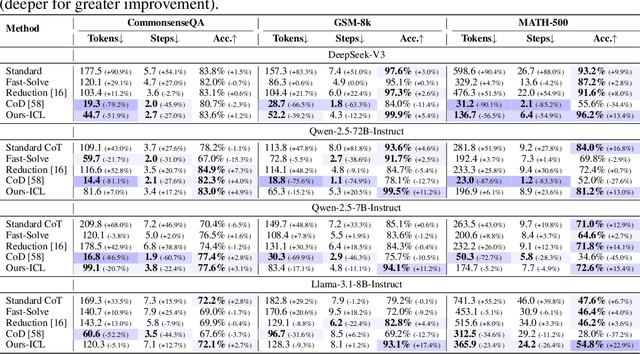
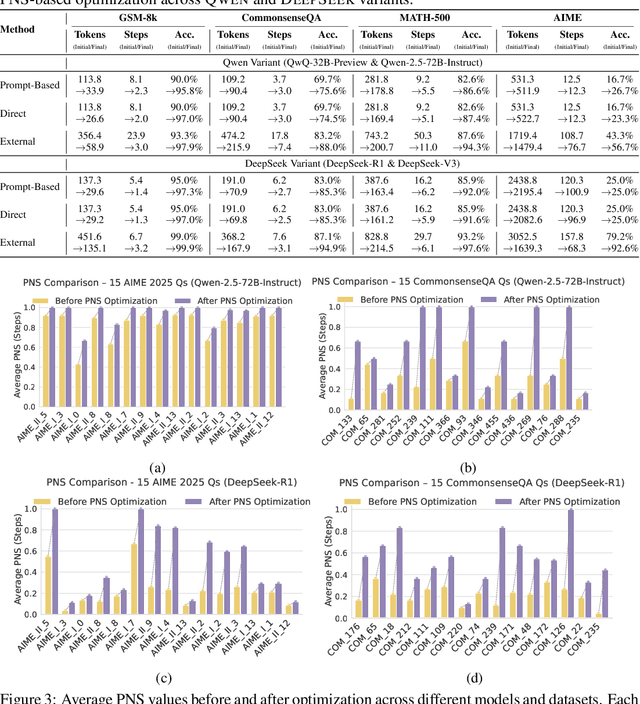
Chain-of-Thought (CoT) prompting plays an indispensable role in endowing large language models (LLMs) with complex reasoning capabilities. However, CoT currently faces two fundamental challenges: (1) Sufficiency, which ensures that the generated intermediate inference steps comprehensively cover and substantiate the final conclusion; and (2) Necessity, which identifies the inference steps that are truly indispensable for the soundness of the resulting answer. We propose a causal framework that characterizes CoT reasoning through the dual lenses of sufficiency and necessity. Incorporating causal Probability of Sufficiency and Necessity allows us not only to determine which steps are logically sufficient or necessary to the prediction outcome, but also to quantify their actual influence on the final reasoning outcome under different intervention scenarios, thereby enabling the automated addition of missing steps and the pruning of redundant ones. Extensive experimental results on various mathematical and commonsense reasoning benchmarks confirm substantial improvements in reasoning efficiency and reduced token usage without sacrificing accuracy. Our work provides a promising direction for improving LLM reasoning performance and cost-effectiveness.
OpenR: An Open Source Framework for Advanced Reasoning with Large Language Models
Oct 12, 2024



In this technical report, we introduce OpenR, an open-source framework designed to integrate key components for enhancing the reasoning capabilities of large language models (LLMs). OpenR unifies data acquisition, reinforcement learning training (both online and offline), and non-autoregressive decoding into a cohesive software platform. Our goal is to establish an open-source platform and community to accelerate the development of LLM reasoning. Inspired by the success of OpenAI's o1 model, which demonstrated improved reasoning abilities through step-by-step reasoning and reinforcement learning, OpenR integrates test-time compute, reinforcement learning, and process supervision to improve reasoning in LLMs. Our work is the first to provide an open-source framework that explores the core techniques of OpenAI's o1 model with reinforcement learning, achieving advanced reasoning capabilities beyond traditional autoregressive methods. We demonstrate the efficacy of OpenR by evaluating it on the MATH dataset, utilising publicly available data and search methods. Our initial experiments confirm substantial gains, with relative improvements in reasoning and performance driven by test-time computation and reinforcement learning through process reward models. The OpenR framework, including code, models, and datasets, is accessible at https://openreasoner.github.io.
Attaining Human`s Desirable Outcomes in Human-AI Interaction via Structural Causal Games
May 26, 2024

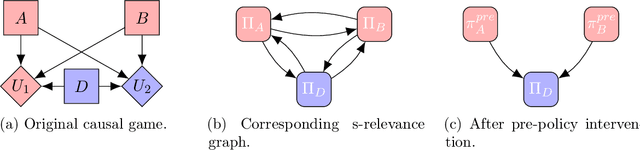
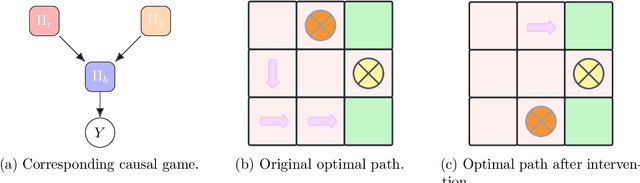
In human-AI interaction, a prominent goal is to attain human`s desirable outcome with the assistance of AI agents, which can be ideally delineated as a problem of seeking the optimal Nash Equilibrium that matches the human`s desirable outcome. However, reaching the outcome is usually challenging due to the existence of multiple Nash Equilibria that are related to the assisting task but do not correspond to the human`s desirable outcome. To tackle this issue, we employ a theoretical framework called structural causal game (SCG) to formalize the human-AI interactive process. Furthermore, we introduce a strategy referred to as pre-policy intervention on the SCG to steer AI agents towards attaining the human`s desirable outcome. In more detail, a pre-policy is learned as a generalized intervention to guide the agents` policy selection, under a transparent and interpretable procedure determined by the SCG. To make the framework practical, we propose a reinforcement learning-like algorithm to search out this pre-policy. The proposed algorithm is tested in both gridworld environments and realistic dialogue scenarios with large language models, demonstrating its adaptability in a broader class of problems and potential effectiveness in real-world situations.
Machine Learning-Based Completions Sequencing for Well Performance Optimization
Feb 23, 2024

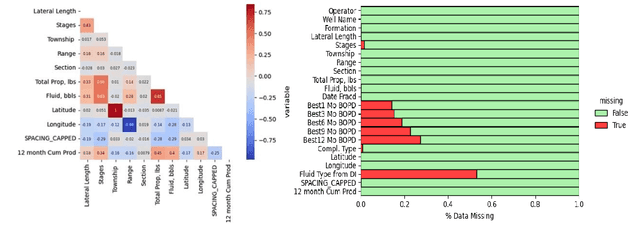
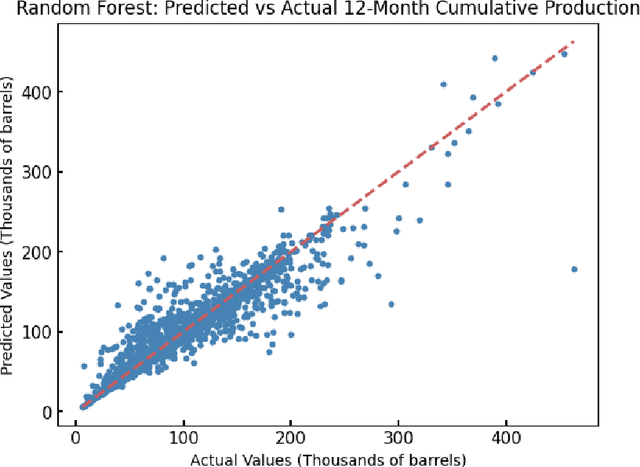
Establishing accurate field development parameters to optimize long-term oil production takes time and effort due to the complexity of oil well development, and the uncertainty in estimating long-term well production. Traditionally, oil and gas companies use simulation software that are inherently computationally expensive to forecast production. Thus, machine learning approaches are recently utilized in literature as an efficient alternative to optimize well developments by enhancing completion conditions. The primary goal of this project is to develop effective machine-learning models that can integrate the effects of multidimensional predictive variables (i.e., completion conditions) to predict 12-Month Cumulative Production accurately. Three predictive regression machine learning models are implemented for predicting 12-month cumulative oil production: Random Forest, Gradient Boosting, and Long Short-Term Memory Models. All three models yielded cumulative production predictions with root mean squared error (RMSE ) values ranging from 7.35 to 20.01 thousand barrels of oil. Although we hypothesized that all models would yield accurate predictions, the results indicated a crucial need for further refinement to create reliable and rational predictive tools in the subsurface. While this study did not produce optimal models for completion sequencing to maximize long-term production, we established that machine learning models alone are not self-sufficient for problems of this nature. Hence, there is potential for significant improvement, including comprehensive feature engineering, and a recommendation of exploring the use of hybrid or surrogate models (i.e., coupling physics reduced models and machine learning models), to ascertain significant contribution to the progress of completion sequencing workflows.