 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisasterBench: Benchmarking LLM Planning under Typed Tool Interface Constraints
May 27, 2026Disasters cause severe societal impacts, demanding rapid coordination of heterogeneous AI tools, from satellite analysis to flood prediction and damage assessment, into coherent multi-step workflows. As LLMs increasingly serve as orchestrators of such pipelines, effective coordination requires more than selecting semantically plausible tools: LLMs must generate executable workflows with correct parameter binding and dependency propagation. We introduce DisasterBench, a benchmark for evaluating structured multi-agent planning over semantically similar but operationally distinct disaster-response tools. To enable step-level failure attribution, we further propose First-Point-of-Failure (FPoF), which localizes the earliest root cause in a predicted workflow, separating primary errors from downstream cascading effects. Our evaluation reveals three findings: planning method effectiveness depends strongly on model capacity; tool mismatch and parameter-binding errors dominate first failures, revealing semantic grounding and execution consistency as distinct bottlenecks; and verbose intermediate reasoning can create instruction clash with structured output requirements, disrupting plan generation. Together, these findings highlight a fundamental gap between semantic reasoning and execution-grounded coordination, underscoring the need for planning frameworks that jointly model semantic intent, execution constraints, and workflow consistency. Code, data, and evaluation resources are available at: https://github.com/TamuChen18/DisasterBench_Open
DisastQA: A Comprehensive Benchmark for Evaluating Question Answering in Disaster Management
Jan 07, 2026Accurate question answering (QA) in disaster management requires reasoning over uncertain and conflicting information, a setting poorly captured by existing benchmarks built on clean evidence. We introduce DisastQA, a large-scale benchmark of 3,000 rigorously verified questions (2,000 multiple-choice and 1,000 open-ended) spanning eight disaster types. The benchmark is constructed via a human-LLM collaboration pipeline with stratified sampling to ensure balanced coverage. Models are evaluated under varying evidence conditions, from closed-book to noisy evidence integration, enabling separation of internal knowledge from reasoning under imperfect information. For open-ended QA, we propose a human-verified keypoint-based evaluation protocol emphasizing factual completeness over verbosity. Experiments with 20 models reveal substantial divergences from general-purpose leaderboards such as MMLU-Pro. While recent open-weight models approach proprietary systems in clean settings, performance degrades sharply under realistic noise, exposing critical reliability gaps for disaster response. All code, data, and evaluation resources are available at https://github.com/TamuChen18/DisastQA_open.
DiNAT-IR: Exploring Dilated Neighborhood Attention for High-Quality Image Restoration
Jul 23, 2025Transformers, with their self-attention mechanisms for modeling long-range dependencies, have become a dominant paradigm in image restoration tasks. However, the high computational cost of self-attention limits scalability to high-resolution images, making efficiency-quality trade-offs a key research focus. To address this, Restormer employs channel-wise self-attention, which computes attention across channels instead of spatial dimensions. While effective, this approach may overlook localized artifacts that are crucial for high-quality image restoration. To bridge this gap, we explore Dilated Neighborhood Attention (DiNA) as a promising alternative, inspired by its success in high-level vision tasks. DiNA balances global context and local precision by integrating sliding-window attention with mixed dilation factors, effectively expanding the receptive field without excessive overhead. However, our preliminary experiments indicate that directly applying this global-local design to the classic deblurring task hinders accurate visual restoration, primarily due to the constrained global context understanding within local attention. To address this, we introduce a channel-aware module that complements local attention, effectively integrating global context without sacrificing pixel-level precision. The proposed DiNAT-IR, a Transformer-based architecture specifically designed for image restoration, achieves competitive results across multiple benchmarks, offering a high-quality solution for diverse low-level computer vision problems.
DisastIR: A Comprehensive Information Retrieval Benchmark for Disaster Management
May 20, 2025
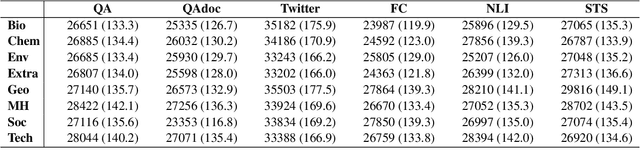


Effective disaster management requires timely access to accurate and contextually relevant information. Existing Information Retrieval (IR) benchmarks, however, focus primarily on general or specialized domains, such as medicine or finance, neglecting the unique linguistic complexity and diverse information needs encountered in disaster management scenarios. To bridge this gap, we introduce DisastIR, the first comprehensive IR evaluation benchmark specifically tailored for disaster management. DisastIR comprises 9,600 diverse user queries and more than 1.3 million labeled query-passage pairs, covering 48 distinct retrieval tasks derived from six search intents and eight general disaster categories that include 301 specific event types. Our evaluations of 30 state-of-the-art retrieval models demonstrate significant performance variances across tasks, with no single model excelling universally. Furthermore, comparative analyses reveal significant performance gaps between general-domain and disaster management-specific tasks, highlighting the necessity of disaster management-specific benchmarks for guiding IR model selection to support effective decision-making in disaster management scenarios. All source codes and DisastIR are available at https://github.com/KaiYin97/Disaster_IR.
Flow Matching for Collaborative Filtering
Feb 11, 2025Generative models have shown great promise in collaborative filtering by capturing the underlying distribution of user interests and preferences. However, existing approaches struggle with inaccurate posterior approximations and misalignment with the discrete nature of recommendation data, limiting their expressiveness and real-world performance. To address these limitations, we propose FlowCF, a novel flow-based recommendation system leveraging flow matching for collaborative filtering. We tailor flow matching to the unique challenges in recommendation through two key innovations: (1) a behavior-guided prior that aligns with user behavior patterns to handle the sparse and heterogeneous user-item interactions, and (2) a discrete flow framework to preserve the binary nature of implicit feedback while maintaining the benefits of flow matching, such as stable training and efficient inference. Extensive experiments demonstrate that FlowCF achieves state-of-the-art recommendation accuracy across various datasets with the fastest inference speed, making it a compelling approach for real-world recommender systems.
XYScanNet: An Interpretable State Space Model for Perceptual Image Deblurring
Dec 13, 2024



Deep state-space models (SSMs), like recent Mamba architectures, are emerging as a promising alternative to CNN and Transformer networks. Existing Mamba-based restoration methods process the visual data by leveraging a flatten-and-scan strategy that converts image patches into a 1D sequence before scanning. However, this scanning paradigm ignores local pixel dependencies and introduces spatial misalignment by positioning distant pixels incorrectly adjacent, which reduces local noise-awareness and degrades image sharpness in low-level vision tasks. To overcome these issues, we propose a novel slice-and-scan strategy that alternates scanning along intra- and inter-slices. We further design a new Vision State Space Module (VSSM) for image deblurring, and tackle the inefficiency challenges of the current Mamba-based vision module. Building upon this, we develop XYScanNet, an SSM architecture integrated with a lightweight feature fusion module for enhanced image deblurring. XYScanNet, maintains competitive distortion metrics and significantly improves perceptual performance. Experimental results show that XYScanNet enhances KID by $17\%$ compared to the nearest competitor. Our code will be released soon.
TwinCL: A Twin Graph Contrastive Learning Model for Collaborative Filtering
Sep 27, 2024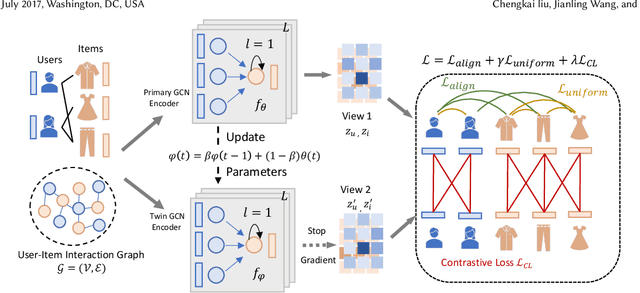
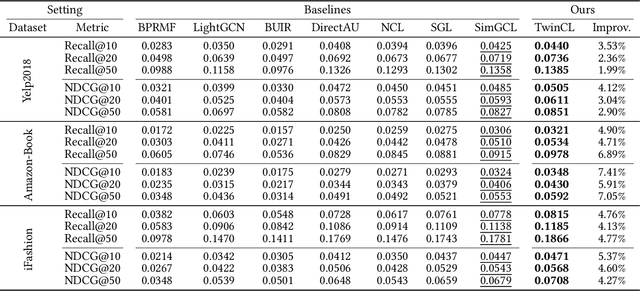
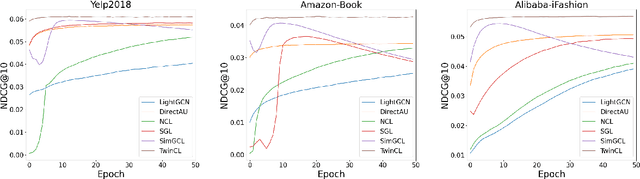
In the domain of recommendation and collaborative filtering, Graph Contrastive Learning (GCL) has become an influential approach. Nevertheless, the reasons for the effectiveness of contrastive learning are still not well understood. In this paper, we challenge the conventional use of random augmentations on graph structure or embedding space in GCL, which may disrupt the structural and semantic information inherent in Graph Neural Networks. Moreover, fixed-rate data augmentation proves to be less effective compared to augmentation with an adaptive rate. In the initial training phases, significant perturbations are more suitable, while as the training approaches convergence, milder perturbations yield better results. We introduce a twin encoder in place of random augmentations, demonstrating the redundancy of traditional augmentation techniques. The twin encoder updating mechanism ensures the generation of more diverse contrastive views in the early stages, transitioning to views with greater similarity as training progresses. In addition, we investigate the learned representations from the perspective of alignment and uniformity on a hypersphere to optimize more efficiently. Our proposed Twin Graph Contrastive Learning model -- TwinCL -- aligns positive pairs of user and item embeddings and the representations from the twin encoder while maintaining the uniformity of the embeddings on the hypersphere. Our theoretical analysis and experimental results show that the proposed model optimizing alignment and uniformity with the twin encoder contributes to better recommendation accuracy and training efficiency performance. In comprehensive experiments on three public datasets, our proposed TwinCL achieves an average improvement of 5.6% (NDCG@10) in recommendation accuracy with faster training speed, while effectively mitigating popularity bias.
A Survey on Diffusion Models for Recommender Systems
Sep 08, 2024



While traditional recommendation techniques have made significant strides in the past decades, they still suffer from limited generalization performance caused by factors like inadequate collaborative signals, weak latent representations, and noisy data. In response, diffusion models (DMs) have emerged as promising solutions for recommender systems due to their robust generative capabilities, solid theoretical foundations, and improved training stability. To this end, in this paper, we present the first comprehensive survey on diffusion models for recommendation, and draw a bird's-eye view from the perspective of the whole pipeline in real-world recommender systems. We systematically categorize existing research works into three primary domains: (1) diffusion for data engineering & encoding, focusing on data augmentation and representation enhancement; (2) diffusion as recommender models, employing diffusion models to directly estimate user preferences and rank items; and (3) diffusion for content presentation, utilizing diffusion models to generate personalized content such as fashion and advertisement creatives. Our taxonomy highlights the unique strengths of diffusion models in capturing complex data distributions and generating high-quality, diverse samples that closely align with user preferences. We also summarize the core characteristics of the adapting diffusion models for recommendation, and further identify key areas for future exploration, which helps establish a roadmap for researchers and practitioners seeking to advance recommender systems through the innovative application of diffusion models. To further facilitate the research community of recommender systems based on diffusion models, we actively maintain a GitHub repository for papers and other related resources in this rising direction https://github.com/CHIANGEL/Awesome-Diffusion-for-RecSys.
Behavior-Dependent Linear Recurrent Units for Efficient Sequential Recommendation
Jun 18, 2024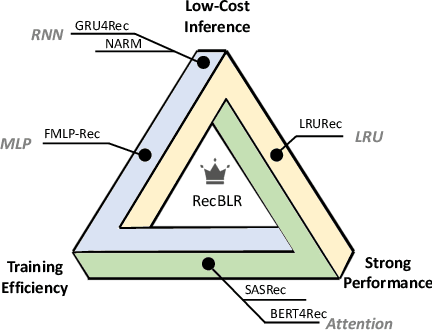
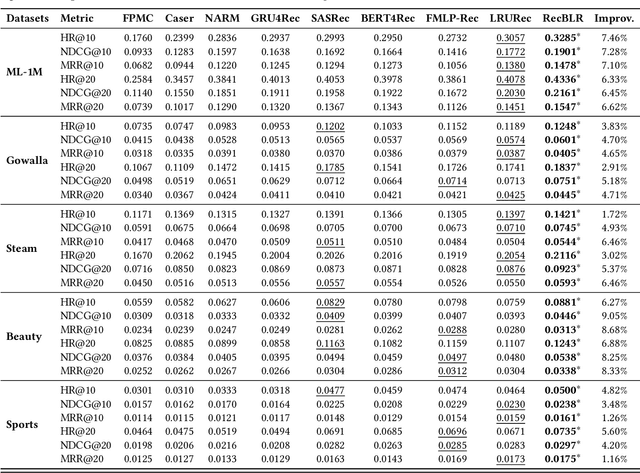
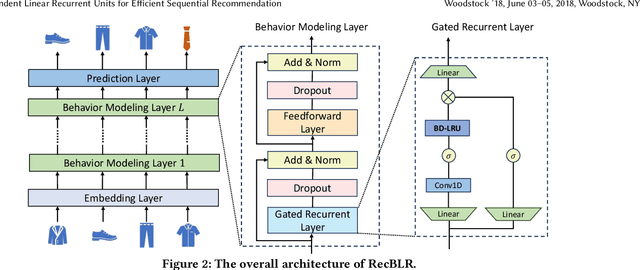
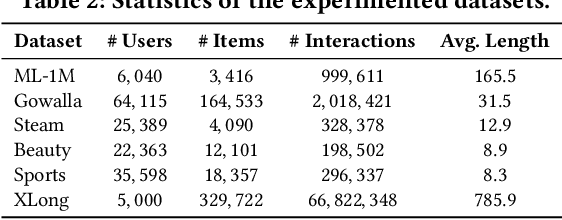
Sequential recommender systems aims to predict the users' next interaction through user behavior modeling with various operators like RNNs and attentions. However, existing models generally fail to achieve the three golden principles for sequential recommendation simultaneously, i.e., training efficiency, low-cost inference, and strong performance. To this end, we propose RecBLR, an Efficient Sequential Recommendation Model based on Behavior-Dependent Linear Recurrent Units to accomplish the impossible triangle of the three principles. By incorporating gating mechanisms and behavior-dependent designs into linear recurrent units, our model significantly enhances user behavior modeling and recommendation performance. Furthermore, we unlock the parallelizable training as well as inference efficiency for our model by designing a hardware-aware scanning acceleration algorithm with a customized CUDA kernel. Extensive experiments on real-world datasets with varying lengths of user behavior sequences demonstrate RecBLR's remarkable effectiveness in simultaneously achieving all three golden principles - strong recommendation performance, training efficiency, and low-cost inference, while exhibiting excellent scalability to datasets with long user interaction histories.
CrisisSense-LLM: Instruction Fine-Tuned Large Language Model for Multi-label Social Media Text Classification in Disaster Informatics
Jun 16, 2024



In the field of crisis/disaster informatics, social media is increasingly being used for improving situational awareness to inform response and relief efforts. Efficient and accurate text classification tools have been a focal area of investigation in crisis informatics. However, current methods mostly rely on single-label text classification models, which fails to capture different insights embedded in dynamic and multifaceted disaster-related social media data. This study introduces a novel approach to disaster text classification by enhancing a pre-trained Large Language Model (LLM) through instruction fine-tuning targeted for multi-label classification of disaster-related tweets. Our methodology involves creating a comprehensive instruction dataset from disaster-related tweets, which is then used to fine-tune an open-source LLM, thereby embedding it with disaster-specific knowledge. This fine-tuned model can classify multiple aspects of disaster-related information simultaneously, such as the type of event, informativeness, and involvement of human aid, significantly improving the utility of social media data for situational awareness in disasters. The results demonstrate that this approach enhances the categorization of critical information from social media posts, thereby facilitating a more effective deployment for situational awareness during emergencies. This research paves the way for more advanced, adaptable, and robust disaster management tools, leveraging the capabilities of LLMs to improve real-time situational awareness and response strategies in disaster scenarios.