 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-JEPA : Soft Clustering Anchors for Self-Supervised Speech Representation Learning
Jun 17, 2026Self-supervised speech encoders are predominantly trained by predicting discrete hard cluster IDs at masked positions, a recipe that collapses acoustic ambiguity at category boundaries and requires interrupting training to re-cluster the entire corpus between iterations. We introduce S-JEPA, a JEPA-style encoder-predictor pair trained to match the soft posteriors of a Gaussian Mixture Model at masked positions via KL divergence. Training runs as one continuous optimization trajectory in two phases: a fixed GMM over MFCC features, then an online GMM over encoder features, with the input layer selected adaptively from a label-free signal, removing both the offline re-cluster step and the hand-tuned choice of which transformer layer to cluster on. Under the SUPERB protocol, S-JEPA achieves the lowest WER among evaluated SSL methods below 90M parameters and matches HuBERT-Base on emotion recognition at roughly half its parameter count, establishing a new Pareto frontier without offline re-clustering or teacher distillation. An analysis of the predictor's per-frame entropy on held-out speech reveals a bimodal distribution with a substantial minority of frames near the entropy of a perfect two-cluster tie, providing direct empirical evidence that the soft-target objective preserves the acoustic ambiguity that hard targets would collapse. Code is available at https://github.com/gioannides/s-jepa.
Mirage Probes: How Vision Models Fake Visual Understanding
Jun 11, 2026Vision-language models (VLMs) can answer image-based questions confidently, and often correctly, even when no image is provided. This mirage behavior inflates benchmark scores without reflecting visual grounding. Prior work treats this as a single failure mode. We argue it is two. Using Mirage Probes, a contrastive probing framework that pairs paraphrased question variants with matched mirage and non-mirage labels on the same image, we show that mirage behavior is linearly decodable from internal activations across residual stream, MLP, post-attention, and attention-head sites in two open-source VLMs. We demonstrate that a Naive Bayes text baseline cannot recover this signal, ruling out surface lexical confounds. Cross-benchmark separability patterns, together with a novel Prior Harnessing Index (PHI) measuring how much a model can answer from text alone, expose two distinct regimes: textual biases, where the model answers from language priors without engaging visual representations, and spurious images, where it constructs false visual content in latent space and answers as if grounded. The distinction has direct mitigation consequences: text-distribution cleaning can address the first regime but cannot reach the second, since spurious-image mirages live in the model's visual representations rather than its text. Faithful visual grounding will require interventions at the representational level.
Do Multi-Agents Dream of Electric Screens? Achieving Perfect Accuracy on AndroidWorld Through Task Decomposition
Feb 08, 2026We present Minitap, a multi-agent system that achieves 100% success on the AndroidWorld benchmark, the first to fully solve all 116 tasks and surpassing human performance (80%). We first analyze why single-agent architectures fail: context pollution from mixed reasoning traces, silent text input failures undetected by the agent, and repetitive action loops without escape. Minitap addresses each failure through targeted mechanisms: cognitive separation across six specialized agents, deterministic post-validation of text input against device state, and meta-cognitive reasoning that detects cycles and triggers strategy changes. Ablations show multi-agent decomposition contributes +21 points over single-agent baselines; verified execution adds +7 points; meta-cognition adds +9 points. We release Minitap as open-source software. https://github.com/minitap-ai/mobile-use
UAT-LITE: Inference-Time Uncertainty-Aware Attention for Pretrained Transformers
Feb 03, 2026Neural NLP models are often miscalibrated, assigning high confidence to incorrect predictions, which undermines selective prediction and high-stakes deployment. Post-hoc calibration methods adjust output probabilities but leave internal computation unchanged, while ensemble and Bayesian approaches improve uncertainty at substantial training or storage cost. We propose UAT-LITE, an inference-time framework that makes self-attention uncertainty-aware using approximate Bayesian inference via Monte Carlo dropout in pretrained transformer classifiers. Token-level epistemic uncertainty is estimated from stochastic forward passes and used to modulate self-attention during contextualization, without modifying pretrained weights or training objectives. We additionally introduce a layerwise variance decomposition to diagnose how predictive uncertainty accumulates across transformer depth. Across the SQuAD 2.0 answerability, MNLI, and SST-2, UAT-LITE reduces Expected Calibration Error by approximately 20% on average relative to a fine-tuned BERT-base baseline while preserving task accuracy, and improves selective prediction and robustness under distribution shift.
Beyond the Loss Curve: Scaling Laws, Active Learning, and the Limits of Learning from Exact Posteriors
Jan 30, 2026How close are neural networks to the best they could possibly do? Standard benchmarks cannot answer this because they lack access to the true posterior p(y|x). We use class-conditional normalizing flows as oracles that make exact posteriors tractable on realistic images (AFHQ, ImageNet). This enables five lines of investigation. Scaling laws: Prediction error decomposes into irreducible aleatoric uncertainty and reducible epistemic error; the epistemic component follows a power law in dataset size, continuing to shrink even when total loss plateaus. Limits of learning: The aleatoric floor is exactly measurable, and architectures differ markedly in how they approach it: ResNets exhibit clean power-law scaling while Vision Transformers stall in low-data regimes. Soft labels: Oracle posteriors contain learnable structure beyond class labels: training with exact posteriors outperforms hard labels and yields near-perfect calibration. Distribution shift: The oracle computes exact KL divergence of controlled perturbations, revealing that shift type matters more than shift magnitude: class imbalance barely affects accuracy at divergence values where input noise causes catastrophic degradation. Active learning: Exact epistemic uncertainty distinguishes genuinely informative samples from inherently ambiguous ones, improving sample efficiency. Our framework reveals that standard metrics hide ongoing learning, mask architectural differences, and cannot diagnose the nature of distribution shift.
Thinking Beyond Tokens: From Brain-Inspired Intelligence to Cognitive Foundations for Artificial General Intelligence and its Societal Impact
Jul 01, 2025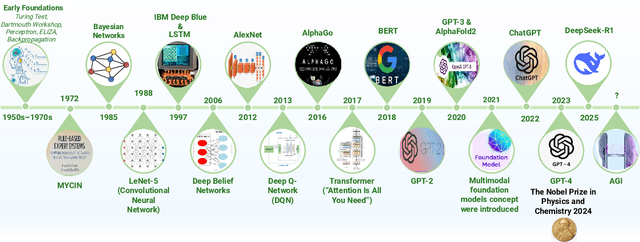
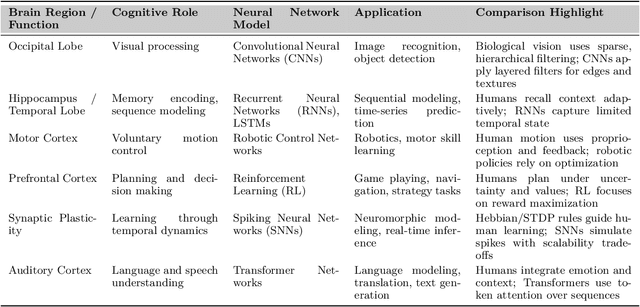
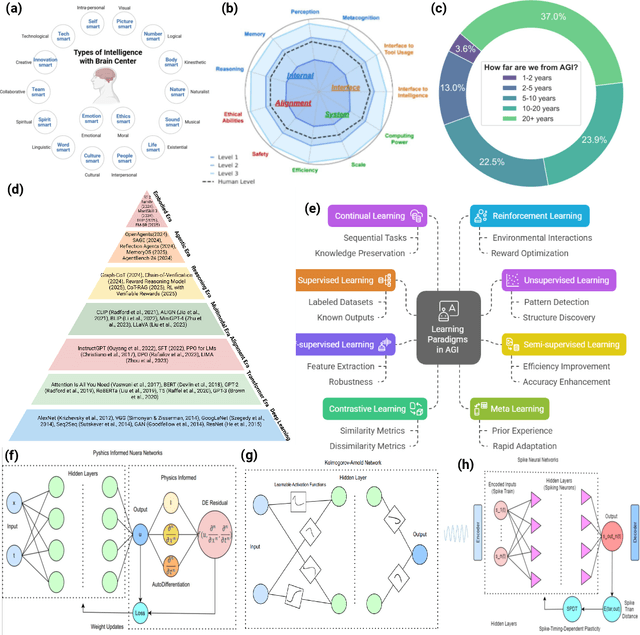
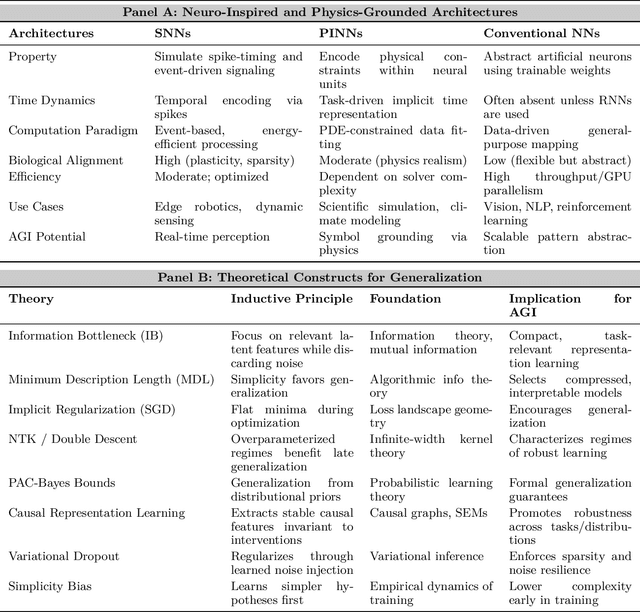
Can machines truly think, reason and act in domains like humans? This enduring question continues to shape the pursuit of Artificial General Intelligence (AGI). Despite the growing capabilities of models such as GPT-4.5, DeepSeek, Claude 3.5 Sonnet, Phi-4, and Grok 3, which exhibit multimodal fluency and partial reasoning, these systems remain fundamentally limited by their reliance on token-level prediction and lack of grounded agency. This paper offers a cross-disciplinary synthesis of AGI development, spanning artificial intelligence, cognitive neuroscience, psychology, generative models, and agent-based systems. We analyze the architectural and cognitive foundations of general intelligence, highlighting the role of modular reasoning, persistent memory, and multi-agent coordination. In particular, we emphasize the rise of Agentic RAG frameworks that combine retrieval, planning, and dynamic tool use to enable more adaptive behavior. We discuss generalization strategies, including information compression, test-time adaptation, and training-free methods, as critical pathways toward flexible, domain-agnostic intelligence. Vision-Language Models (VLMs) are reexamined not just as perception modules but as evolving interfaces for embodied understanding and collaborative task completion. We also argue that true intelligence arises not from scale alone but from the integration of memory and reasoning: an orchestration of modular, interactive, and self-improving components where compression enables adaptive behavior. Drawing on advances in neurosymbolic systems, reinforcement learning, and cognitive scaffolding, we explore how recent architectures begin to bridge the gap between statistical learning and goal-directed cognition. Finally, we identify key scientific, technical, and ethical challenges on the path to AGI.
From Tokens to Thoughts: How LLMs and Humans Trade Compression for Meaning
May 21, 2025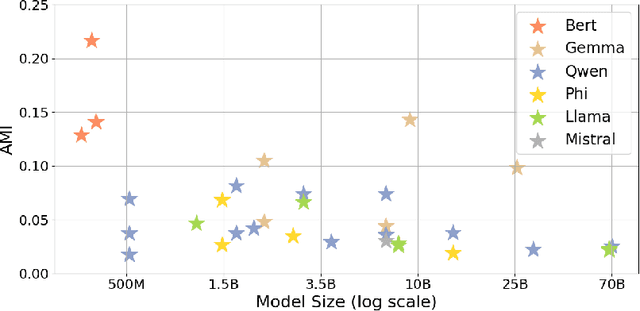
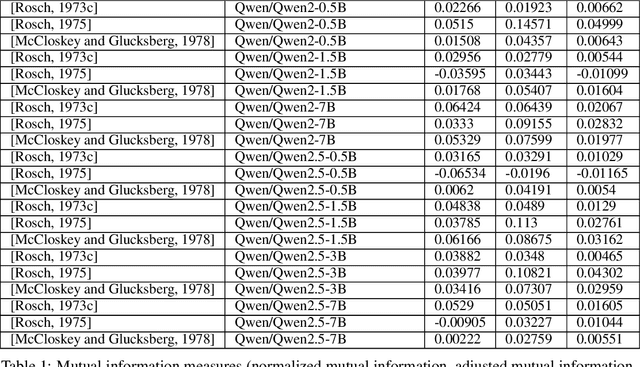
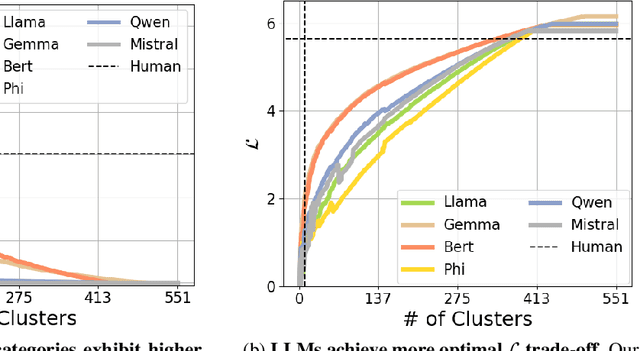
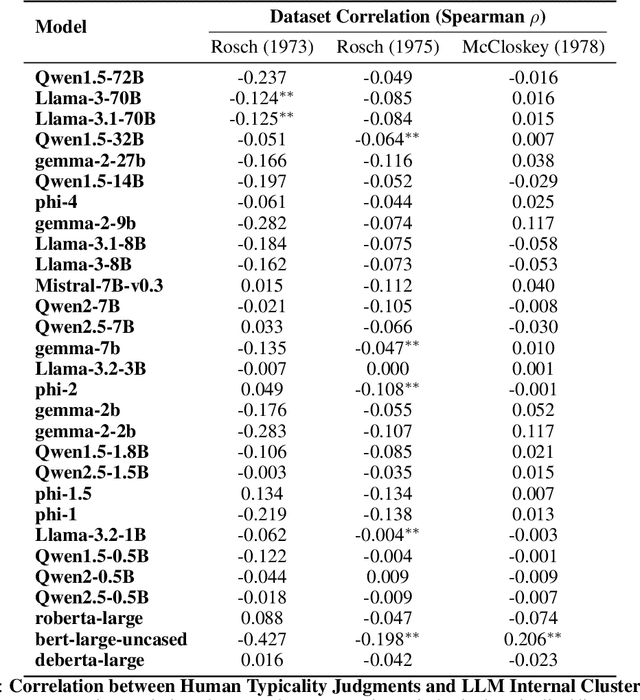
Humans organize knowledge into compact categories through semantic compression by mapping diverse instances to abstract representations while preserving meaning (e.g., robin and blue jay are both birds; most birds can fly). These concepts reflect a trade-off between expressive fidelity and representational simplicity. Large Language Models (LLMs) demonstrate remarkable linguistic abilities, yet whether their internal representations strike a human-like trade-off between compression and semantic fidelity is unclear. We introduce a novel information-theoretic framework, drawing from Rate-Distortion Theory and the Information Bottleneck principle, to quantitatively compare these strategies. Analyzing token embeddings from a diverse suite of LLMs against seminal human categorization benchmarks, we uncover key divergences. While LLMs form broad conceptual categories that align with human judgment, they struggle to capture the fine-grained semantic distinctions crucial for human understanding. More fundamentally, LLMs demonstrate a strong bias towards aggressive statistical compression, whereas human conceptual systems appear to prioritize adaptive nuance and contextual richness, even if this results in lower compressional efficiency by our measures. These findings illuminate critical differences between current AI and human cognitive architectures, guiding pathways toward LLMs with more human-aligned conceptual representations.
Layer by Layer: Uncovering Hidden Representations in Language Models
Feb 04, 2025



From extracting features to generating text, the outputs of large language models (LLMs) typically rely on their final layers, following the conventional wisdom that earlier layers capture only low-level cues. However, our analysis shows that intermediate layers can encode even richer representations, often improving performance on a wide range of downstream tasks. To explain and quantify these hidden-layer properties, we propose a unified framework of representation quality metrics based on information theory, geometry, and invariance to input perturbations. Our framework highlights how each model layer balances information compression and signal preservation, revealing why mid-depth embeddings can exceed the last layer's performance. Through extensive experiments on 32 text-embedding tasks and comparisons across model architectures (transformers, state-space models) and domains (language, vision), we demonstrate that intermediate layers consistently provide stronger features. These findings challenge the standard focus on final-layer embeddings and open new directions for model analysis and optimization, including strategic use of mid-layer representations for more robust and accurate AI systems.
Video Representation Learning with Joint-Embedding Predictive Architectures
Dec 14, 2024Video representation learning is an increasingly important topic in machine learning research. We present Video JEPA with Variance-Covariance Regularization (VJ-VCR): a joint-embedding predictive architecture for self-supervised video representation learning that employs variance and covariance regularization to avoid representation collapse. We show that hidden representations from our VJ-VCR contain abstract, high-level information about the input data. Specifically, they outperform representations obtained from a generative baseline on downstream tasks that require understanding of the underlying dynamics of moving objects in the videos. Additionally, we explore different ways to incorporate latent variables into the VJ-VCR framework that capture information about uncertainty in the future in non-deterministic settings.
Does Representation Matter? Exploring Intermediate Layers in Large Language Models
Dec 12, 2024Understanding what defines a good representation in large language models (LLMs) is fundamental to both theoretical understanding and practical applications. In this paper, we investigate the quality of intermediate representations in various LLM architectures, including Transformers and State Space Models (SSMs). We find that intermediate layers often yield more informative representations for downstream tasks than the final layers. To measure the representation quality, we adapt and apply a suite of metrics - such as prompt entropy, curvature, and augmentation-invariance - originally proposed in other contexts. Our empirical study reveals significant architectural differences, how representations evolve throughout training, and how factors like input randomness and prompt length affect each layer. Notably, we observe a bimodal pattern in the entropy of some intermediate layers and consider potential explanations tied to training data. Overall, our results illuminate the internal mechanics of LLMs and guide strategies for architectural optimization and training.