 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormalizing Mathematics at Scale
May 28, 2026We present AutoformBot, a multi-agent system for building an Autoformalized Textbook Library At Scale (Atlas) in Lean 4. AutoformBot orchestrates thousands of LLM agents, equipped with formal verification tools, dependency-aware task scheduling, and collaborative version control, to translate informal textbook prose into machine-checked definitions and proofs. We apply our methods to a corpus of 26 open-access textbooks spanning analysis, algebra, topology, combinatorics, and probability, producing Atlas: a verified library of over 45,000 Lean 4 declarations and 500 thousand lines of code. We release two artifacts: (i) AutoformBot, the open-source multi-agent framework; and (ii) Atlas, the resulting formal library. Our results suggest that autoformalizing the core content of graduate-level mathematics at scale is now economically and technically feasible. This opens the door to the automated verification of both human- and machine-generated mathematics at a research level.
Layer by Layer: Uncovering Hidden Representations in Language Models
Feb 04, 2025



From extracting features to generating text, the outputs of large language models (LLMs) typically rely on their final layers, following the conventional wisdom that earlier layers capture only low-level cues. However, our analysis shows that intermediate layers can encode even richer representations, often improving performance on a wide range of downstream tasks. To explain and quantify these hidden-layer properties, we propose a unified framework of representation quality metrics based on information theory, geometry, and invariance to input perturbations. Our framework highlights how each model layer balances information compression and signal preservation, revealing why mid-depth embeddings can exceed the last layer's performance. Through extensive experiments on 32 text-embedding tasks and comparisons across model architectures (transformers, state-space models) and domains (language, vision), we demonstrate that intermediate layers consistently provide stronger features. These findings challenge the standard focus on final-layer embeddings and open new directions for model analysis and optimization, including strategic use of mid-layer representations for more robust and accurate AI systems.
On the Local Complexity of Linear Regions in Deep ReLU Networks
Dec 24, 2024
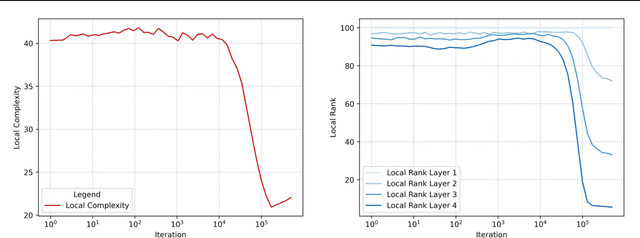
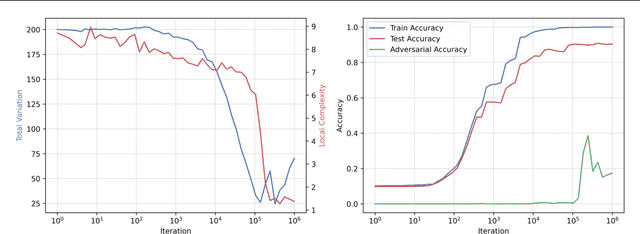

We define the local complexity of a neural network with continuous piecewise linear activations as a measure of the density of linear regions over an input data distribution. We show theoretically that ReLU networks that learn low-dimensional feature representations have a lower local complexity. This allows us to connect recent empirical observations on feature learning at the level of the weight matrices with concrete properties of the learned functions. In particular, we show that the local complexity serves as an upper bound on the total variation of the function over the input data distribution and thus that feature learning can be related to adversarial robustness. Lastly, we consider how optimization drives ReLU networks towards solutions with lower local complexity. Overall, this work contributes a theoretical framework towards relating geometric properties of ReLU networks to different aspects of learning such as feature learning and representation cost.
Learning to Compress: Local Rank and Information Compression in Deep Neural Networks
Oct 10, 2024Deep neural networks tend to exhibit a bias toward low-rank solutions during training, implicitly learning low-dimensional feature representations. This paper investigates how deep multilayer perceptrons (MLPs) encode these feature manifolds and connects this behavior to the Information Bottleneck (IB) theory. We introduce the concept of local rank as a measure of feature manifold dimensionality and demonstrate, both theoretically and empirically, that this rank decreases during the final phase of training. We argue that networks that reduce the rank of their learned representations also compress mutual information between inputs and intermediate layers. This work bridges the gap between feature manifold rank and information compression, offering new insights into the interplay between information bottlenecks and representation learning.
Bridging the Gap: Addressing Discrepancies in Diffusion Model Training for Classifier-Free Guidance
Nov 02, 2023Diffusion models have emerged as a pivotal advancement in generative models, setting new standards to the quality of the generated instances. In the current paper we aim to underscore a discrepancy between conventional training methods and the desired conditional sampling behavior of these models. While the prevalent classifier-free guidance technique works well, it's not without flaws. At higher values for the guidance scale parameter $w$, we often get out of distribution samples and mode collapse, whereas at lower values for $w$ we may not get the desired specificity. To address these challenges, we introduce an updated loss function that better aligns training objectives with sampling behaviors. Experimental validation with FID scores on CIFAR-10 elucidates our method's ability to produce higher quality samples with fewer sampling timesteps, and be more robust to the choice of guidance scale $w$. We also experiment with fine-tuning Stable Diffusion on the proposed loss, to provide early evidence that large diffusion models may also benefit from this refined loss function.