 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Augmented LLMs for Swiss MP Ideology Prediction
May 06, 2026Approximating the ideological position of Members of Parliament (MPs) is a fundamental task in political science, helping researchers understand legislative behavior, party alignment, and policy preferences. While Large Language Models (LLMs) have shown promising results in estimating MPs' ideological stances, there are more actors and elements in the parliamentary system, and relations between them, that could provide a wider and more informative picture. However, due to the complexity of integrating them in the prediction task, these additional elements are generally ignored. In this work, we propose an LLM framework, PG-RAG, that implements a retrieval-augmented generation pipeline: it first queries a political knowledge graph (KG) and then integrates the resulting graph-structured information into the context. This allows for capturing both textual semantics and inter-MP relationships, another relevant information source in any parliamentary system. We evaluate the approach on the task of ideology prediction, using data from a Swiss parliamentary dataset. When comparing graph-augmented models against several state-of-the-art baselines, the results demonstrate that incorporating this enriched information, which encodes information about different entities and relations, improves prediction performance. These results help to highlight the value of domain-specific relational information in modeling political behavior.
Learning to Build: Autonomous Robotic Assembly of Stable Structures Without Predefined Plans
Feb 27, 2026This paper presents a novel autonomous robotic assembly framework for constructing stable structures without relying on predefined architectural blueprints. Instead of following fixed plans, construction tasks are defined through targets and obstacles, allowing the system to adapt more flexibly to environmental uncertainty and variations during the building process. A reinforcement learning (RL) policy, trained using deep Q-learning with successor features, serves as the decision-making component. As a proof of concept, we evaluate the approach on a benchmark of 15 2D robotic assembly tasks of discrete block construction. Experiments using a real-world closed-loop robotic setup demonstrate the feasibility of the method and its ability to handle construction noise. The results suggest that our framework offers a promising direction for more adaptable and robust robotic construction in real-world environments.
Graph Neural Network-Based Predictive Modeling for Robotic Plaster Printing
Mar 31, 2025
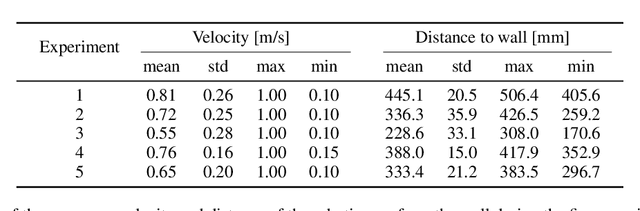

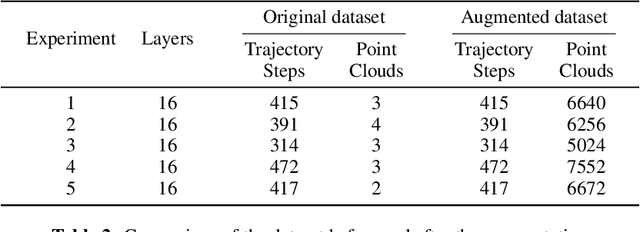
This work proposes a Graph Neural Network (GNN) modeling approach to predict the resulting surface from a particle based fabrication process. The latter consists of spray-based printing of cementitious plaster on a wall and is facilitated with the use of a robotic arm. The predictions are computed using the robotic arm trajectory features, such as position, velocity and direction, as well as the printing process parameters. The proposed approach, based on a particle representation of the wall domain and the end effector, allows for the adoption of a graph-based solution. The GNN model consists of an encoder-processor-decoder architecture and is trained using data from laboratory tests, while the hyperparameters are optimized by means of a Bayesian scheme. The aim of this model is to act as a simulator of the printing process, and ultimately used for the generation of the robotic arm trajectory and the optimization of the printing parameters, towards the materialization of an autonomous plastering process. The performance of the proposed model is assessed in terms of the prediction error against unseen ground truth data, which shows its generality in varied scenarios, as well as in comparison with the performance of an existing benchmark model. The results demonstrate a significant improvement over the benchmark model, with notably better performance and enhanced error scaling across prediction steps.
Bridging the Gap: Addressing Discrepancies in Diffusion Model Training for Classifier-Free Guidance
Nov 02, 2023Diffusion models have emerged as a pivotal advancement in generative models, setting new standards to the quality of the generated instances. In the current paper we aim to underscore a discrepancy between conventional training methods and the desired conditional sampling behavior of these models. While the prevalent classifier-free guidance technique works well, it's not without flaws. At higher values for the guidance scale parameter $w$, we often get out of distribution samples and mode collapse, whereas at lower values for $w$ we may not get the desired specificity. To address these challenges, we introduce an updated loss function that better aligns training objectives with sampling behaviors. Experimental validation with FID scores on CIFAR-10 elucidates our method's ability to produce higher quality samples with fewer sampling timesteps, and be more robust to the choice of guidance scale $w$. We also experiment with fine-tuning Stable Diffusion on the proposed loss, to provide early evidence that large diffusion models may also benefit from this refined loss function.
KG-FRUS: a Novel Graph-based Dataset of 127 Years of US Diplomatic Relations
Oct 30, 2023

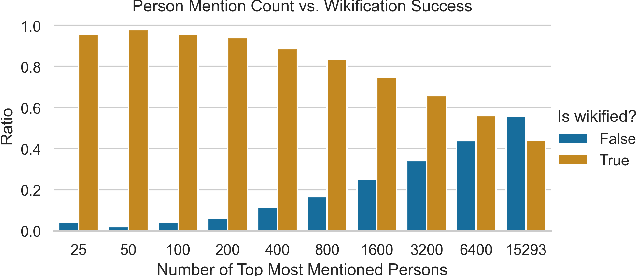

In the current paper, we present the KG-FRUS dataset, comprised of more than 300,000 US government diplomatic documents encoded in a Knowledge Graph (KG). We leverage the data of the Foreign Relations of the United States (FRUS) (available as XML files) to extract information about the documents and the individuals and countries mentioned within them. We use the extracted entities, and associated metadata, to create a graph-based dataset. Further, we supplement the created KG with additional entities and relations from Wikidata. The relations in the KG capture the synergies and dynamics required to study and understand the complex fields of diplomacy, foreign relations, and politics. This goes well beyond a simple collection of documents which neglects the relations between entities in the text. We showcase a range of possibilities of the current dataset by illustrating different approaches to probe the KG. In the paper, we exemplify how to use a query language to answer simple research questions and how to use graph algorithms such as Node2Vec and PageRank, that benefit from the complete graph structure. More importantly, the chosen structure provides total flexibility for continuously expanding and enriching the graph. Our solution is general, so the proposed pipeline for building the KG can encode other original corpora of time-dependent and complex phenomena. Overall, we present a mechanism to create KG databases providing a more versatile representation of time-dependent related text data and a particular application to the all-important FRUS database.
Design Space Exploration and Explanation via Conditional Variational Autoencoders in Meta-model-based Conceptual Design of Pedestrian Bridges
Nov 29, 2022For conceptual design, engineers rely on conventional iterative (often manual) techniques. Emerging parametric models facilitate design space exploration based on quantifiable performance metrics, yet remain time-consuming and computationally expensive. Pure optimisation methods, however, ignore qualitative aspects (e.g. aesthetics or construction methods). This paper provides a performance-driven design exploration framework to augment the human designer through a Conditional Variational Autoencoder (CVAE), which serves as forward performance predictor for given design features as well as an inverse design feature predictor conditioned on a set of performance requests. The CVAE is trained on 18'000 synthetically generated instances of a pedestrian bridge in Switzerland. Sensitivity analysis is employed for explainability and informing designers about (i) relations of the model between features and/or performances and (ii) structural improvements under user-defined objectives. A case study proved our framework's potential to serve as a future co-pilot for conceptual design studies of pedestrian bridges and beyond.
Shape-aware Surface Reconstruction from Sparse 3D Point-Clouds
Feb 15, 2017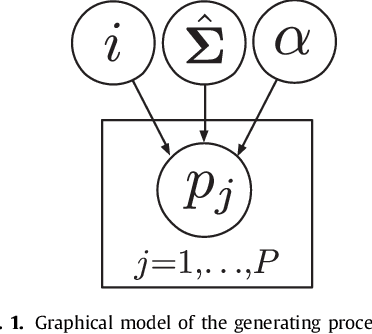
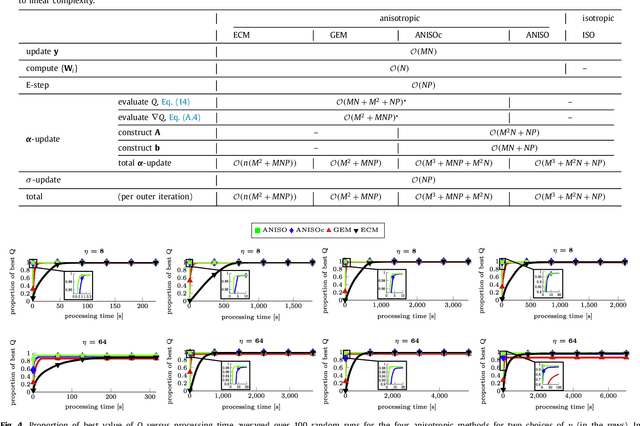
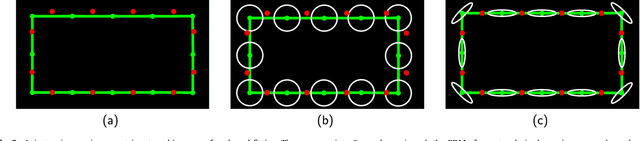
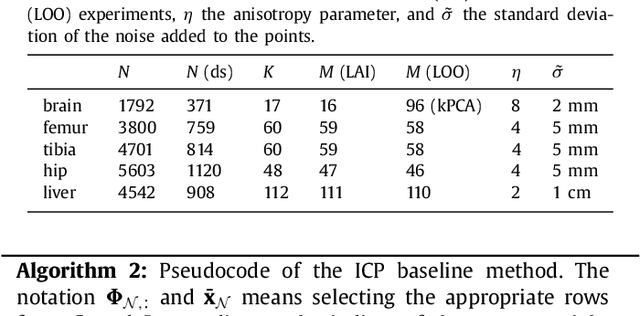
The reconstruction of an object's shape or surface from a set of 3D points plays an important role in medical image analysis, e.g. in anatomy reconstruction from tomographic measurements or in the process of aligning intra-operative navigation and preoperative planning data. In such scenarios, one usually has to deal with sparse data, which significantly aggravates the problem of reconstruction. However, medical applications often provide contextual information about the 3D point data that allow to incorporate prior knowledge about the shape that is to be reconstructed. To this end, we propose the use of a statistical shape model (SSM) as a prior for surface reconstruction. The SSM is represented by a point distribution model (PDM), which is associated with a surface mesh. Using the shape distribution that is modelled by the PDM, we formulate the problem of surface reconstruction from a probabilistic perspective based on a Gaussian Mixture Model (GMM). In order to do so, the given points are interpreted as samples of the GMM. By using mixture components with anisotropic covariances that are "oriented" according to the surface normals at the PDM points, a surface-based fitting is accomplished. Estimating the parameters of the GMM in a maximum a posteriori manner yields the reconstruction of the surface from the given data points. We compare our method to the extensively used Iterative Closest Points method on several different anatomical datasets/SSMs (brain, femur, tibia, hip, liver) and demonstrate superior accuracy and robustness on sparse data.