 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKG-FRUS: a Novel Graph-based Dataset of 127 Years of US Diplomatic Relations
Oct 30, 2023

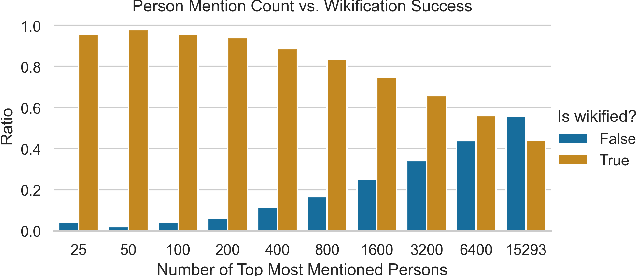

In the current paper, we present the KG-FRUS dataset, comprised of more than 300,000 US government diplomatic documents encoded in a Knowledge Graph (KG). We leverage the data of the Foreign Relations of the United States (FRUS) (available as XML files) to extract information about the documents and the individuals and countries mentioned within them. We use the extracted entities, and associated metadata, to create a graph-based dataset. Further, we supplement the created KG with additional entities and relations from Wikidata. The relations in the KG capture the synergies and dynamics required to study and understand the complex fields of diplomacy, foreign relations, and politics. This goes well beyond a simple collection of documents which neglects the relations between entities in the text. We showcase a range of possibilities of the current dataset by illustrating different approaches to probe the KG. In the paper, we exemplify how to use a query language to answer simple research questions and how to use graph algorithms such as Node2Vec and PageRank, that benefit from the complete graph structure. More importantly, the chosen structure provides total flexibility for continuously expanding and enriching the graph. Our solution is general, so the proposed pipeline for building the KG can encode other original corpora of time-dependent and complex phenomena. Overall, we present a mechanism to create KG databases providing a more versatile representation of time-dependent related text data and a particular application to the all-important FRUS database.
Using Artificial Intelligence to Identify State Secrets
Nov 01, 2016

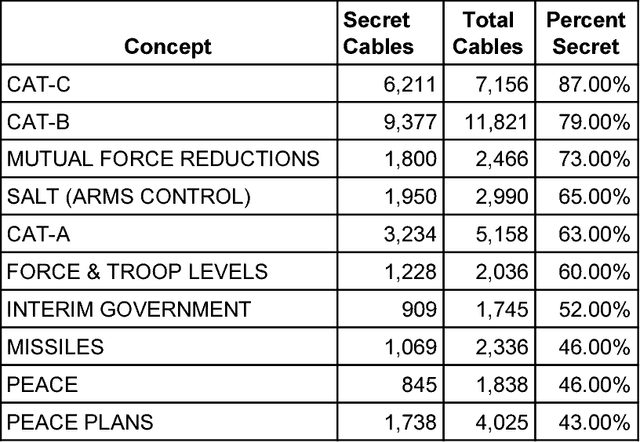
Whether officials can be trusted to protect national security information has become a matter of great public controversy, reigniting a long-standing debate about the scope and nature of official secrecy. The declassification of millions of electronic records has made it possible to analyze these issues with greater rigor and precision. Using machine-learning methods, we examined nearly a million State Department cables from the 1970s to identify features of records that are more likely to be classified, such as international negotiations, military operations, and high-level communications. Even with incomplete data, algorithms can use such features to identify 90% of classified cables with <11% false positives. But our results also show that there are longstanding problems in the identification of sensitive information. Error analysis reveals many examples of both overclassification and underclassification. This indicates both the need for research on inter-coder reliability among officials as to what constitutes classified material and the opportunity to develop recommender systems to better manage both classification and declassification.