 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Artificial Intelligence to Identify State Secrets
Nov 01, 2016

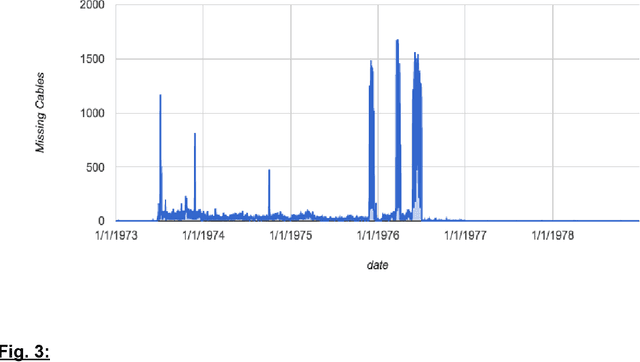
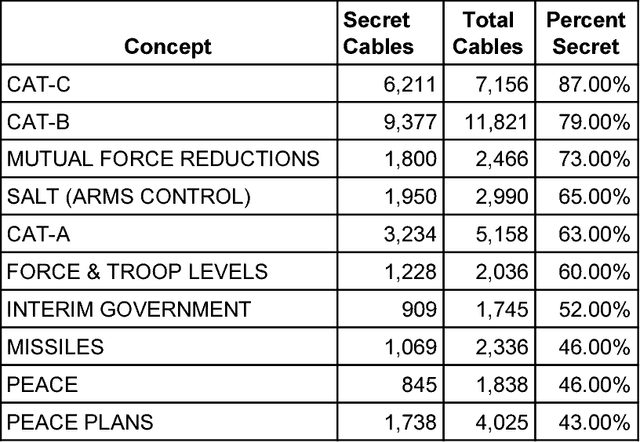
Whether officials can be trusted to protect national security information has become a matter of great public controversy, reigniting a long-standing debate about the scope and nature of official secrecy. The declassification of millions of electronic records has made it possible to analyze these issues with greater rigor and precision. Using machine-learning methods, we examined nearly a million State Department cables from the 1970s to identify features of records that are more likely to be classified, such as international negotiations, military operations, and high-level communications. Even with incomplete data, algorithms can use such features to identify 90% of classified cables with <11% false positives. But our results also show that there are longstanding problems in the identification of sensitive information. Error analysis reveals many examples of both overclassification and underclassification. This indicates both the need for research on inter-coder reliability among officials as to what constitutes classified material and the opportunity to develop recommender systems to better manage both classification and declassification.
PyPLN: a Distributed Platform for Natural Language Processing
Feb 19, 2013

This paper presents a distributed platform for Natural Language Processing called PyPLN. PyPLN leverages a vast array of NLP and text processing open source tools, managing the distribution of the workload on a variety of configurations: from a single server to a cluster of linux servers. PyPLN is developed using Python 2.7.3 but makes it very easy to incorporate other softwares for specific tasks as long as a linux version is available. PyPLN facilitates analyses both at document and corpus level, simplifying management and publication of corpora and analytical results through an easy to use web interface. In the current (beta) release, it supports English and Portuguese languages with support to other languages planned for future releases. To support the Portuguese language PyPLN uses the PALAVRAS parser\citep{Bick2000}. Currently PyPLN offers the following features: Text extraction with encoding normalization (to UTF-8), part-of-speech tagging, token frequency, semantic annotation, n-gram extraction, word and sentence repertoire, and full-text search across corpora. The platform is licensed as GPL-v3.