 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling transformer neural networks for skillful and reliable medium-range weather forecasting
Dec 06, 2023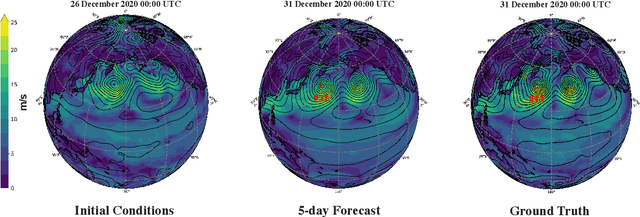
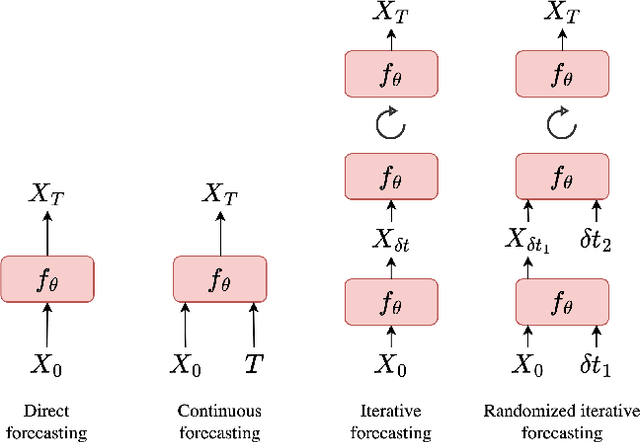
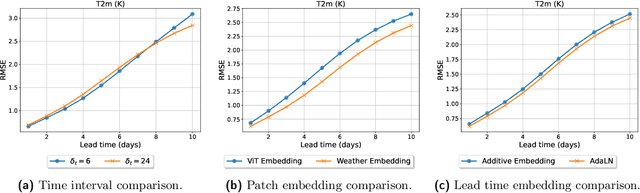
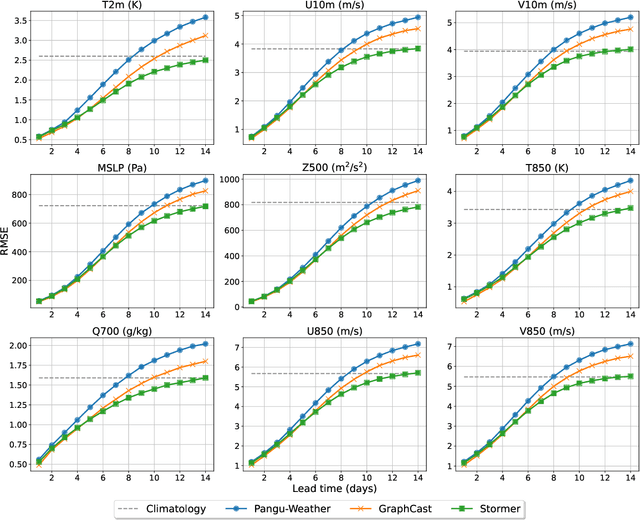
Weather forecasting is a fundamental problem for anticipating and mitigating the impacts of climate change. Recently, data-driven approaches for weather forecasting based on deep learning have shown great promise, achieving accuracies that are competitive with operational systems. However, those methods often employ complex, customized architectures without sufficient ablation analysis, making it difficult to understand what truly contributes to their success. Here we introduce Stormer, a simple transformer model that achieves state-of-the-art performance on weather forecasting with minimal changes to the standard transformer backbone. We identify the key components of Stormer through careful empirical analyses, including weather-specific embedding, randomized dynamics forecast, and pressure-weighted loss. At the core of Stormer is a randomized forecasting objective that trains the model to forecast the weather dynamics over varying time intervals. During inference, this allows us to produce multiple forecasts for a target lead time and combine them to obtain better forecast accuracy. On WeatherBench 2, Stormer performs competitively at short to medium-range forecasts and outperforms current methods beyond 7 days, while requiring orders-of-magnitude less training data and compute. Additionally, we demonstrate Stormer's favorable scaling properties, showing consistent improvements in forecast accuracy with increases in model size and training tokens. Code and checkpoints will be made publicly available.
Turn Down the Noise: Leveraging Diffusion Models for Test-time Adaptation via Pseudo-label Ensembling
Nov 29, 2023



The goal of test-time adaptation is to adapt a source-pretrained model to a continuously changing target domain without relying on any source data. Typically, this is either done by updating the parameters of the model (model adaptation) using inputs from the target domain or by modifying the inputs themselves (input adaptation). However, methods that modify the model suffer from the issue of compounding noisy updates whereas methods that modify the input need to adapt to every new data point from scratch while also struggling with certain domain shifts. We introduce an approach that leverages a pre-trained diffusion model to project the target domain images closer to the source domain and iteratively updates the model via pseudo-label ensembling. Our method combines the advantages of model and input adaptations while mitigating their shortcomings. Our experiments on CIFAR-10C demonstrate the superiority of our approach, outperforming the strongest baseline by an average of 1.7% across 15 diverse corruptions and surpassing the strongest input adaptation baseline by an average of 18%.
PAC Mode Estimation using PPR Martingale Confidence Sequences
Sep 10, 2021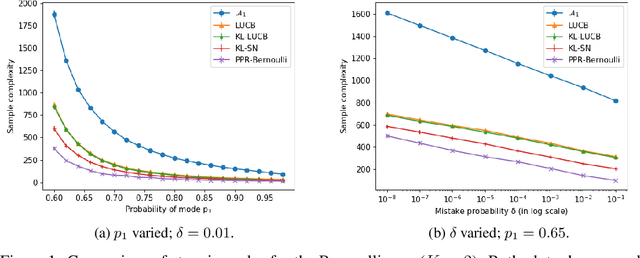
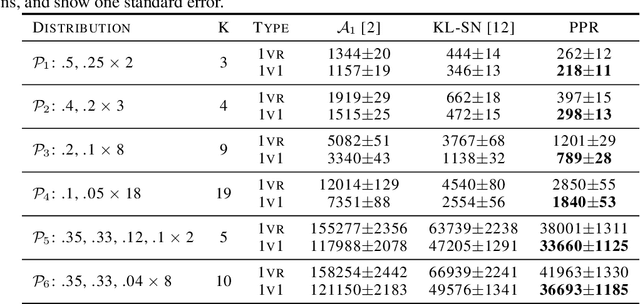
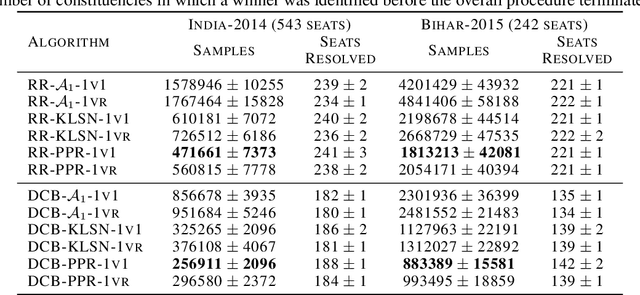
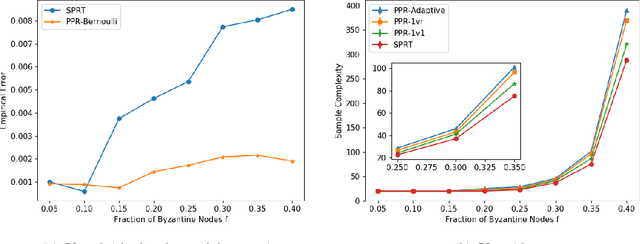
We consider the problem of correctly identifying the mode of a discrete distribution $\mathcal{P}$ with sufficiently high probability by observing a sequence of i.i.d. samples drawn according to $\mathcal{P}$. This problem reduces to the estimation of a single parameter when $\mathcal{P}$ has a support set of size $K = 2$. Noting the efficiency of prior-posterior-ratio (PPR) martingale confidence sequences for handling this special case, we propose a generalisation to mode estimation, in which $\mathcal{P}$ may take $K \geq 2$ values. We observe that the "one-versus-one" principle yields a more efficient generalisation than the "one-versus-rest" alternative. Our resulting stopping rule, denoted PPR-ME, is optimal in its sample complexity up to a logarithmic factor. Moreover, PPR-ME empirically outperforms several other competing approaches for mode estimation. We demonstrate the gains offered by PPR-ME in two practical applications: (1) sample-based forecasting of the winner in indirect election systems, and (2) efficient verification of smart contracts in permissionless blockchains.
Using Artificial Intelligence to Identify State Secrets
Nov 01, 2016

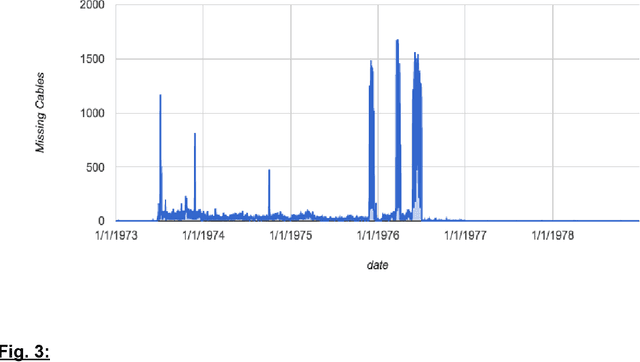
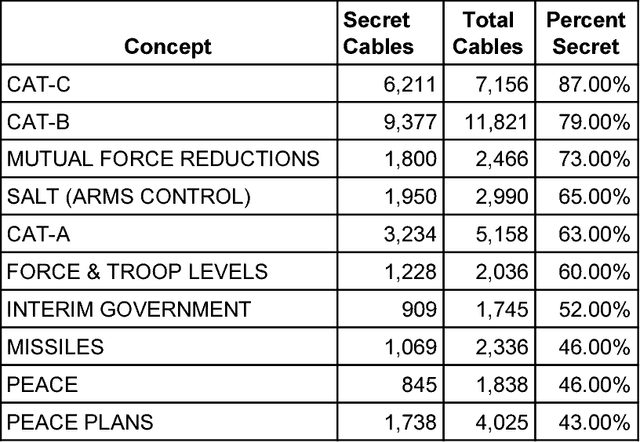
Whether officials can be trusted to protect national security information has become a matter of great public controversy, reigniting a long-standing debate about the scope and nature of official secrecy. The declassification of millions of electronic records has made it possible to analyze these issues with greater rigor and precision. Using machine-learning methods, we examined nearly a million State Department cables from the 1970s to identify features of records that are more likely to be classified, such as international negotiations, military operations, and high-level communications. Even with incomplete data, algorithms can use such features to identify 90% of classified cables with <11% false positives. But our results also show that there are longstanding problems in the identification of sensitive information. Error analysis reveals many examples of both overclassification and underclassification. This indicates both the need for research on inter-coder reliability among officials as to what constitutes classified material and the opportunity to develop recommender systems to better manage both classification and declassification.