 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurn Down the Noise: Leveraging Diffusion Models for Test-time Adaptation via Pseudo-label Ensembling
Nov 29, 2023



The goal of test-time adaptation is to adapt a source-pretrained model to a continuously changing target domain without relying on any source data. Typically, this is either done by updating the parameters of the model (model adaptation) using inputs from the target domain or by modifying the inputs themselves (input adaptation). However, methods that modify the model suffer from the issue of compounding noisy updates whereas methods that modify the input need to adapt to every new data point from scratch while also struggling with certain domain shifts. We introduce an approach that leverages a pre-trained diffusion model to project the target domain images closer to the source domain and iteratively updates the model via pseudo-label ensembling. Our method combines the advantages of model and input adaptations while mitigating their shortcomings. Our experiments on CIFAR-10C demonstrate the superiority of our approach, outperforming the strongest baseline by an average of 1.7% across 15 diverse corruptions and surpassing the strongest input adaptation baseline by an average of 18%.
Bridging the Gap: Exploring the Capabilities of Bridge-Architectures for Complex Visual Reasoning Tasks
Jul 31, 2023In recent times there has been a surge of multi-modal architectures based on Large Language Models, which leverage the zero shot generation capabilities of LLMs and project image embeddings into the text space and then use the auto-regressive capacity to solve tasks such as VQA, captioning, and image retrieval. We name these architectures as "bridge-architectures" as they project from the image space to the text space. These models deviate from the traditional recipe of training transformer based multi-modal models, which involve using large-scale pre-training and complex multi-modal interactions through co or cross attention. However, the capabilities of bridge architectures have not been tested on complex visual reasoning tasks which require fine grained analysis about the image. In this project, we investigate the performance of these bridge-architectures on the NLVR2 dataset, and compare it to state-of-the-art transformer based architectures. We first extend the traditional bridge architectures for the NLVR2 dataset, by adding object level features to faciliate fine-grained object reasoning. Our analysis shows that adding object level features to bridge architectures does not help, and that pre-training on multi-modal data is key for good performance on complex reasoning tasks such as NLVR2. We also demonstrate some initial results on a recently bridge-architecture, LLaVA, in the zero shot setting and analyze its performance.
HateProof: Are Hateful Meme Detection Systems really Robust?
Feb 11, 2023Exploiting social media to spread hate has tremendously increased over the years. Lately, multi-modal hateful content such as memes has drawn relatively more traction than uni-modal content. Moreover, the availability of implicit content payloads makes them fairly challenging to be detected by existing hateful meme detection systems. In this paper, we present a use case study to analyze such systems' vulnerabilities against external adversarial attacks. We find that even very simple perturbations in uni-modal and multi-modal settings performed by humans with little knowledge about the model can make the existing detection models highly vulnerable. Empirically, we find a noticeable performance drop of as high as 10% in the macro-F1 score for certain attacks. As a remedy, we attempt to boost the model's robustness using contrastive learning as well as an adversarial training-based method - VILLA. Using an ensemble of the above two approaches, in two of our high resolution datasets, we are able to (re)gain back the performance to a large extent for certain attacks. We believe that ours is a first step toward addressing this crucial problem in an adversarial setting and would inspire more such investigations in the future.
TRACE: Transform Aggregate and Compose Visiolinguistic Representations for Image Search with Text Feedback
Sep 03, 2020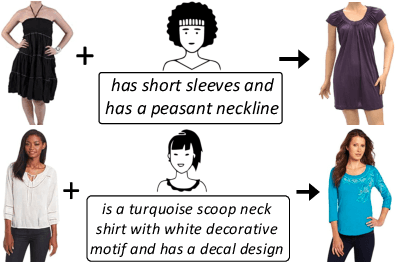
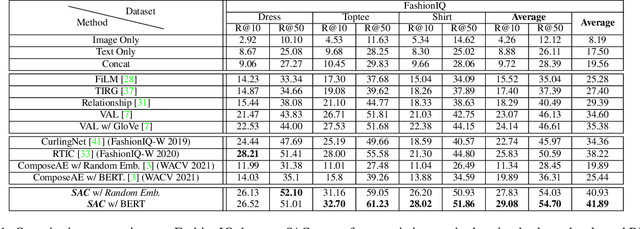
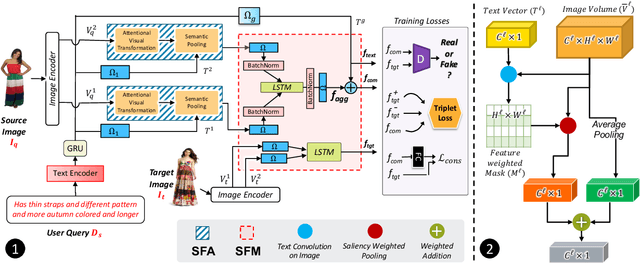
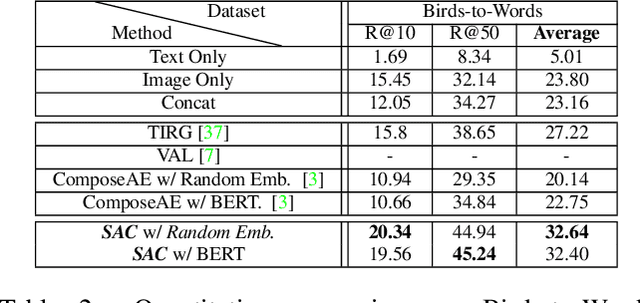
The ability to efficiently search for images over an indexed database is the cornerstone for several user experiences. Incorporating user feedback, through multi-modal inputs provide flexible and interaction to serve fine-grained specificity in requirements. We specifically focus on text feedback, through descriptive natural language queries. Given a reference image and textual user feedback, our goal is to retrieve images that satisfy constraints specified by both of these input modalities. The task is challenging as it requires understanding the textual semantics from the text feedback and then applying these changes to the visual representation. To address these challenges, we propose a novel architecture TRACE which contains a hierarchical feature aggregation module to learn the composite visio-linguistic representations. TRACE achieves the SOTA performance on 3 benchmark datasets: FashionIQ, Shoes, and Birds-to-Words, with an average improvement of at least ~5.7%, ~3%, and ~5% respectively in R@K metric. Our extensive experiments and ablation studies show that TRACE consistently outperforms the existing techniques by significant margins both quantitatively and qualitatively.