 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow, don't tell -- Providing Visual Error Feedback for Handwritten Documents
Jan 14, 2026Handwriting remains an essential skill, particularly in education. Therefore, providing visual feedback on handwritten documents is an important but understudied area. We outline the many challenges when going from an image of handwritten input to correctly placed informative error feedback. We empirically compare modular and end-to-end systems and find that both approaches currently do not achieve acceptable overall quality. We identify the major challenges and outline an agenda for future research.
Comprehensive Study on German Language Models for Clinical and Biomedical Text Understanding
Apr 08, 2024



Recent advances in natural language processing (NLP) can be largely attributed to the advent of pre-trained language models such as BERT and RoBERTa. While these models demonstrate remarkable performance on general datasets, they can struggle in specialized domains such as medicine, where unique domain-specific terminologies, domain-specific abbreviations, and varying document structures are common. This paper explores strategies for adapting these models to domain-specific requirements, primarily through continuous pre-training on domain-specific data. We pre-trained several German medical language models on 2.4B tokens derived from translated public English medical data and 3B tokens of German clinical data. The resulting models were evaluated on various German downstream tasks, including named entity recognition (NER), multi-label classification, and extractive question answering. Our results suggest that models augmented by clinical and translation-based pre-training typically outperform general domain models in medical contexts. We conclude that continuous pre-training has demonstrated the ability to match or even exceed the performance of clinical models trained from scratch. Furthermore, pre-training on clinical data or leveraging translated texts have proven to be reliable methods for domain adaptation in medical NLP tasks.
Text or Image? What is More Important in Cross-Domain Generalization Capabilities of Hate Meme Detection Models?
Feb 07, 2024This paper delves into the formidable challenge of cross-domain generalization in multimodal hate meme detection, presenting compelling findings. We provide enough pieces of evidence supporting the hypothesis that only the textual component of hateful memes enables the existing multimodal classifier to generalize across different domains, while the image component proves highly sensitive to a specific training dataset. The evidence includes demonstrations showing that hate-text classifiers perform similarly to hate-meme classifiers in a zero-shot setting. Simultaneously, the introduction of captions generated from images of memes to the hate-meme classifier worsens performance by an average F1 of 0.02. Through blackbox explanations, we identify a substantial contribution of the text modality (average of 83%), which diminishes with the introduction of meme's image captions (52%). Additionally, our evaluation on a newly created confounder dataset reveals higher performance on text confounders as compared to image confounders with an average $\Delta$F1 of 0.18.
HateProof: Are Hateful Meme Detection Systems really Robust?
Feb 11, 2023Exploiting social media to spread hate has tremendously increased over the years. Lately, multi-modal hateful content such as memes has drawn relatively more traction than uni-modal content. Moreover, the availability of implicit content payloads makes them fairly challenging to be detected by existing hateful meme detection systems. In this paper, we present a use case study to analyze such systems' vulnerabilities against external adversarial attacks. We find that even very simple perturbations in uni-modal and multi-modal settings performed by humans with little knowledge about the model can make the existing detection models highly vulnerable. Empirically, we find a noticeable performance drop of as high as 10% in the macro-F1 score for certain attacks. As a remedy, we attempt to boost the model's robustness using contrastive learning as well as an adversarial training-based method - VILLA. Using an ensemble of the above two approaches, in two of our high resolution datasets, we are able to (re)gain back the performance to a large extent for certain attacks. We believe that ours is a first step toward addressing this crucial problem in an adversarial setting and would inspire more such investigations in the future.
Robustness of end-to-end Automatic Speech Recognition Models -- A Case Study using Mozilla DeepSpeech
May 08, 2021

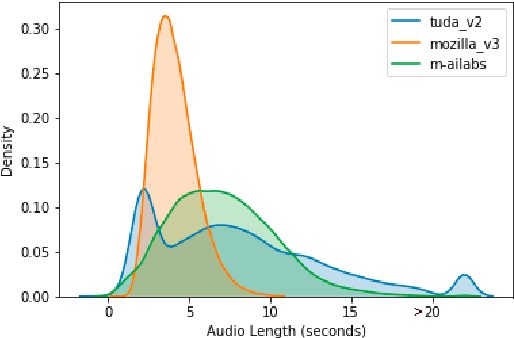
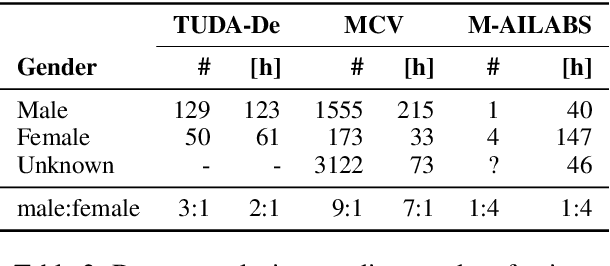
When evaluating the performance of automatic speech recognition models, usually word error rate within a certain dataset is used. Special care must be taken in understanding the dataset in order to report realistic performance numbers. We argue that many performance numbers reported probably underestimate the expected error rate. We conduct experiments controlling for selection bias, gender as well as overlap (between training and test data) in content, voices, and recording conditions. We find that content overlap has the biggest impact, but other factors like gender also play a role.
Effects of Layer Freezing when Transferring DeepSpeech to New Languages
Feb 08, 2021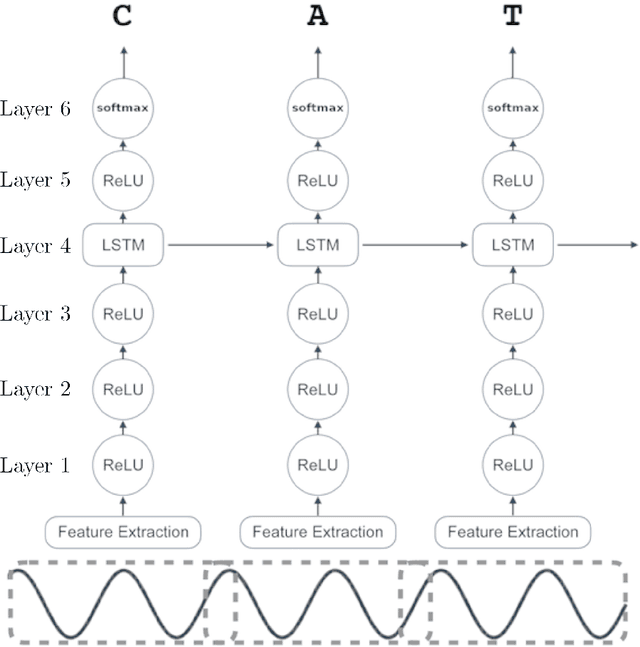

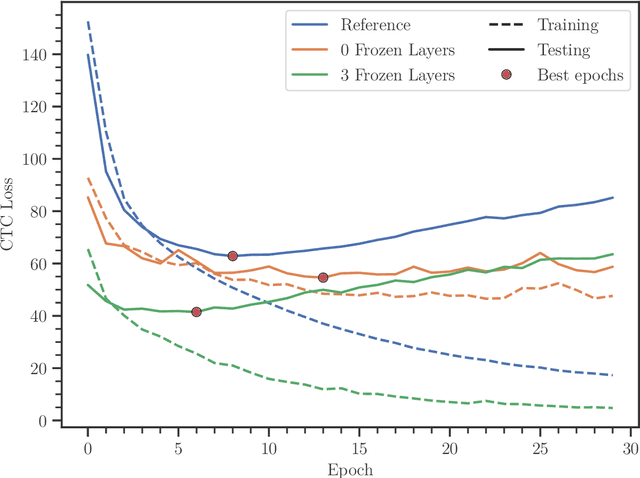
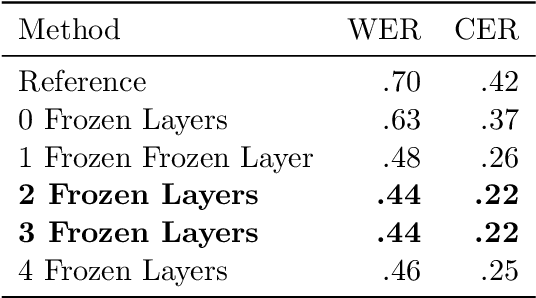
In this paper, we train Mozilla's DeepSpeech architecture on German and Swiss German speech datasets and compare the results of different training methods. We first train the models from scratch on both languages and then improve upon the results by using an English pretrained version of DeepSpeech for weight initialization and experiment with the effects of freezing different layers during training. We see that even freezing only one layer already improves the results dramatically.
Operationalizing the legal concept of 'Incitement to Hatred' as an NLP task
Apr 07, 2020
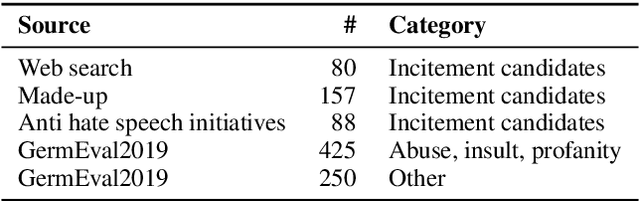
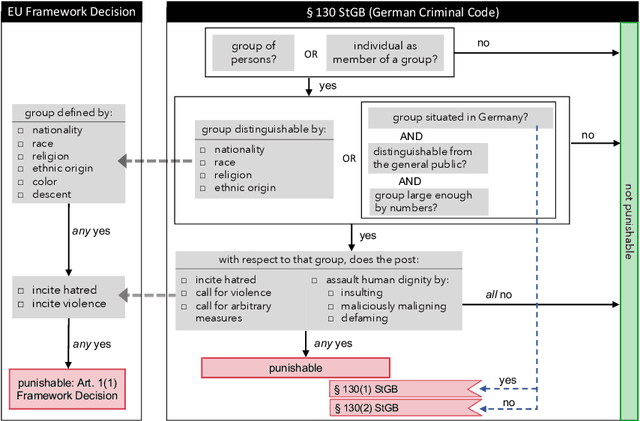
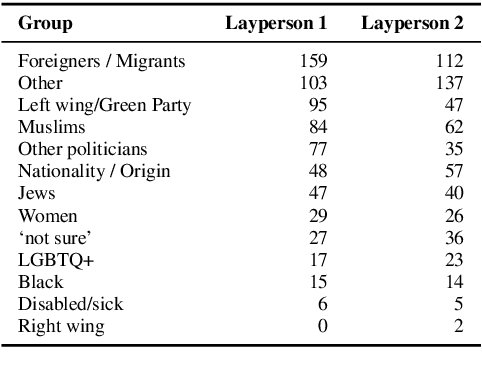
Hate speech detection or offensive language detection are well-established but controversial NLP tasks. There is no denying the temptation to use them for law enforcement or by private actors to censor, delete, or punish online statements. However, given the importance of freedom of expression for the public discourse in a democracy, determining statements that would potentially be subject to these measures requires a legal justification that outweighs the right to free speech in the respective case. The legal concept of 'incitement to hatred' answers this question by preventing discrimination against and segregation of a target group, thereby ensuring the members' acceptance as equal in a society - likewise a prerequisite for democracy. In this paper, we pursue these questions based on the criminal offense of 'incitement to hatred' in {\S} 130 of the German Criminal Code along with the underlying EU Council Framework Decision. Under the German Network Enforcement Act, social media providers are subject to a direct obligation to delete postings violating this offense. We take this as a use case to study the transition from the ill-defined concepts of hate speech or offensive language which are usually used in NLP to an operationalization of an actual legally binding obligation. We first translate the legal assessment into a series of binary decisions and then collect, annotate, and analyze a dataset according to our annotation scheme. Finally, we translate each of the legal decisions into an NLP task based on the annotated data. In this way, we ultimately also explore the extent to which the underlying value-based decisions could be carried over to NLP.