 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Linear Recurrent Memory Works in Partially Observable Reinforcement Learning
May 29, 2026The family of linear recurrent neural networks has shown strong performance as recurrent memory units in partially observable reinforcement learning. We provide a theoretical justification for their empirical effectiveness by constructing and studying two linear filters: (i) the first exactly reproduces the pre-softmax logits of the belief vector in a hidden Markov model (HMM) under a deterministic transition matrix, thereby serving as a sufficient statistic for optimal policy learning, (ii) the second achieves vanishing state-decoding error under a nearly deterministic transition matrix, thus reducing state ambiguity to near zero. The results extend to action-controlled HMMs, where the corresponding linear filters become time-varying with action-dependent dynamics. We illustrate our main results through numerical experiments and further show that the constructed linear filter serves as a strong feature extractor in a small reinforcement learning game.
Commit to the Bit: Reactive Reinforcement Learning Done Right
May 27, 2026Reinforcement learning algorithms are commonly analyzed (and designed) under the Markov assumption. This is unrealistic, as most environments encountered in practice are either partially observable, or require function approximation that restricts the agent to access non-Markovian state features. We consider the problem of learning an optimal reactive policy in a finite environment with deterministic observations (or equivalently, hard state aggregation). We introduce a new algorithm, Committed Q-learning, and prove almost-sure convergence to the optimal reactive policy under an intuitive assumption we call rewire-robustness. This assumption is strictly weaker than the $q_\star$-realizability condition used in prior work. Our algorithm is a variant of classical Q-learning in which the behavior policy commits to a single action upon entering a feature, and only resamples actions when the observed feature changes. A crucial part of our analysis is the introduction of quasi-Markov environments.
Middle-mile logistics through the lens of goal-conditioned reinforcement learning
May 04, 2026Middle-mile logistics describes the problem of routing parcels through a network of hubs linked by trucks with finite capacity. We rephrase this as a multi-object goal-conditioned MDP. Our method combines graph neural networks with model-free RL, extracting small feature graphs from the environment state.
A Pontryagin Perspective on Reinforcement Learning
May 28, 2024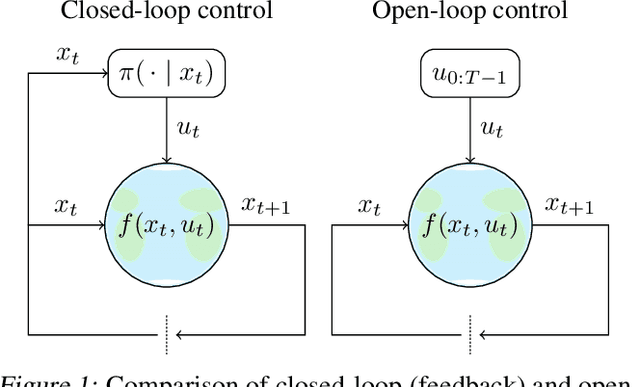

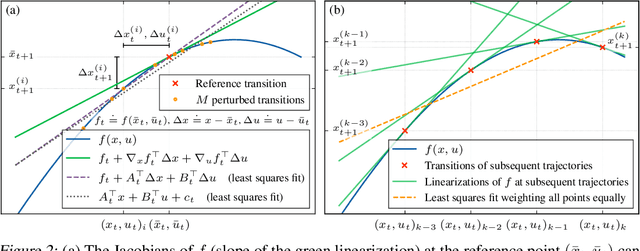

Reinforcement learning has traditionally focused on learning state-dependent policies to solve optimal control problems in a closed-loop fashion. In this work, we introduce the paradigm of open-loop reinforcement learning where a fixed action sequence is learned instead. We present three new algorithms: one robust model-based method and two sample-efficient model-free methods. Rather than basing our algorithms on Bellman's equation from dynamic programming, our work builds on Pontryagin's principle from the theory of open-loop optimal control. We provide convergence guarantees and evaluate all methods empirically on a pendulum swing-up task, as well as on two high-dimensional MuJoCo tasks, demonstrating remarkable performance compared to existing baselines.
Effects of Layer Freezing when Transferring DeepSpeech to New Languages
Feb 08, 2021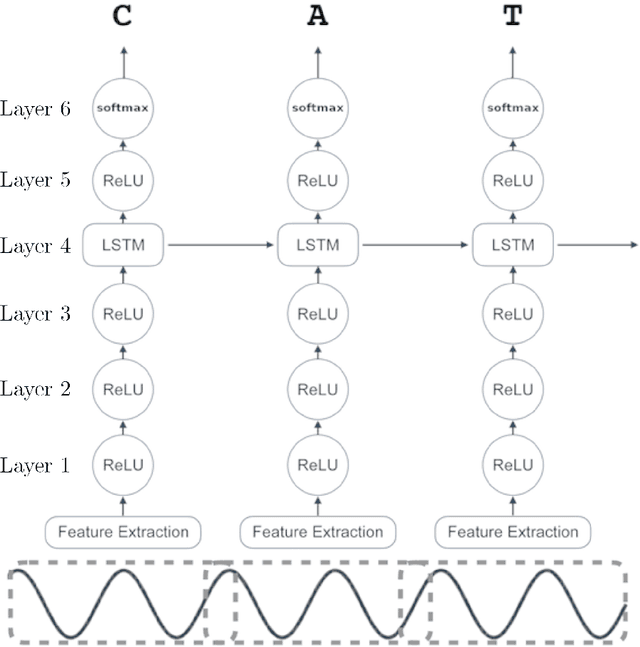

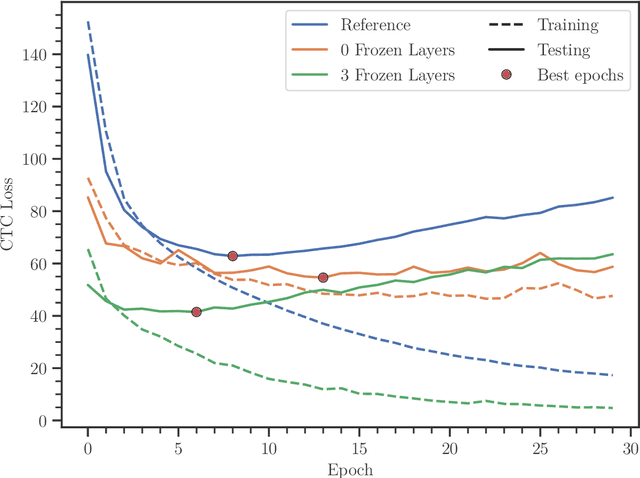
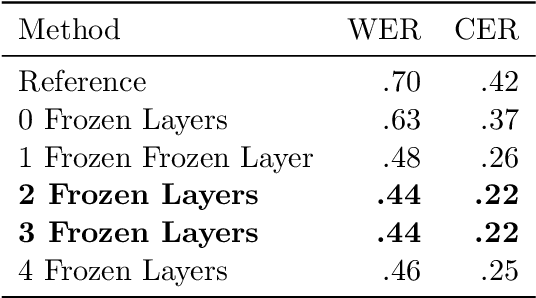
In this paper, we train Mozilla's DeepSpeech architecture on German and Swiss German speech datasets and compare the results of different training methods. We first train the models from scratch on both languages and then improve upon the results by using an English pretrained version of DeepSpeech for weight initialization and experiment with the effects of freezing different layers during training. We see that even freezing only one layer already improves the results dramatically.