Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of Layer Freezing when Transferring DeepSpeech to New Languages
Paper and Code
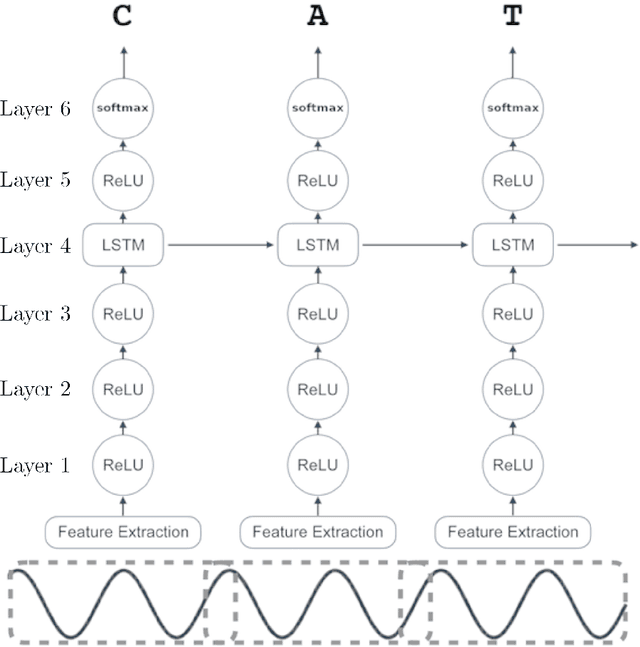

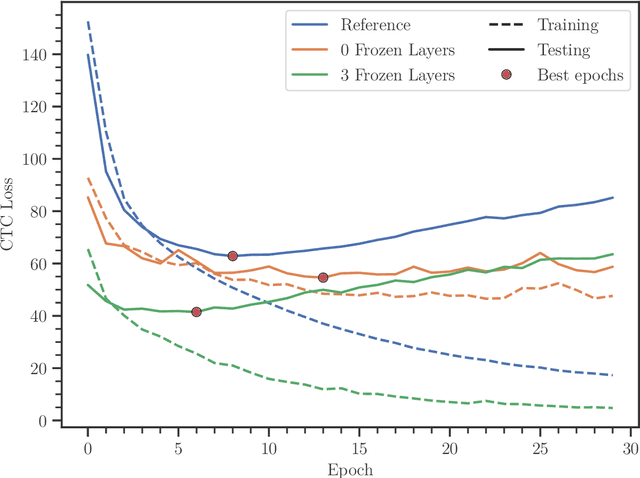
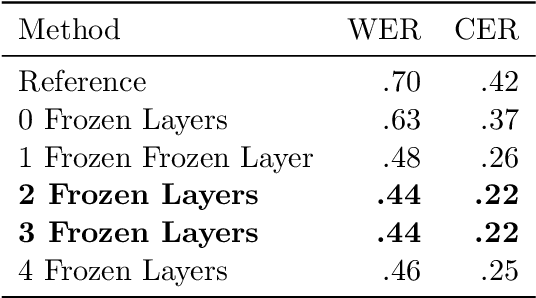
In this paper, we train Mozilla's DeepSpeech architecture on German and Swiss German speech datasets and compare the results of different training methods. We first train the models from scratch on both languages and then improve upon the results by using an English pretrained version of DeepSpeech for weight initialization and experiment with the effects of freezing different layers during training. We see that even freezing only one layer already improves the results dramatically.
View paper on