 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalient Information Prompting to Steer Content in Prompt-based Abstractive Summarization
Oct 03, 2024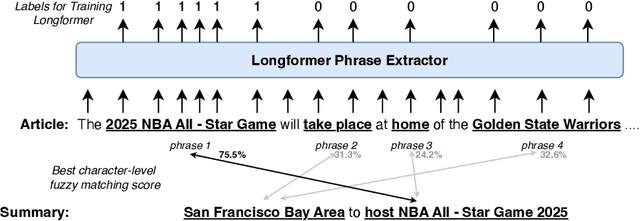
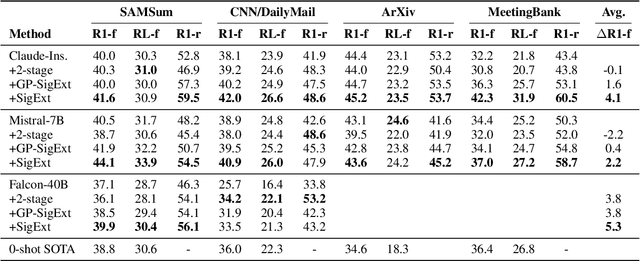
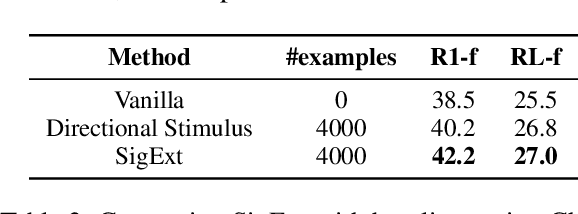
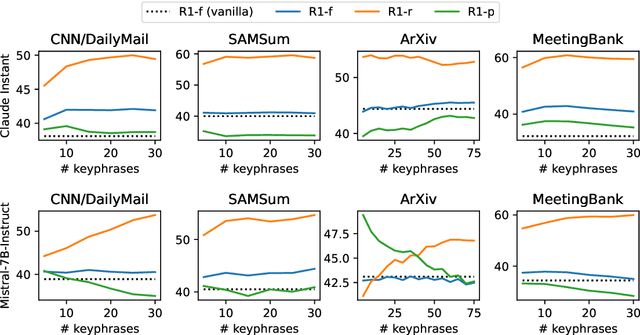
Large language models (LLMs) can generate fluent summaries across domains using prompting techniques, reducing the need to train models for summarization applications. However, crafting effective prompts that guide LLMs to generate summaries with the appropriate level of detail and writing style remains a challenge. In this paper, we explore the use of salient information extracted from the source document to enhance summarization prompts. We show that adding keyphrases in prompts can improve ROUGE F1 and recall, making the generated summaries more similar to the reference and more complete. The number of keyphrases can control the precision-recall trade-off. Furthermore, our analysis reveals that incorporating phrase-level salient information is superior to word- or sentence-level. However, the impact on hallucination is not universally positive across LLMs. To conduct this analysis, we introduce Keyphrase Signal Extractor (SigExt), a lightweight model that can be finetuned to extract salient keyphrases. By using SigExt, we achieve consistent ROUGE improvements across datasets and open-weight and proprietary LLMs without any LLM customization. Our findings provide insights into leveraging salient information in building prompt-based summarization systems.
Bridging the Gap: Exploring the Capabilities of Bridge-Architectures for Complex Visual Reasoning Tasks
Jul 31, 2023In recent times there has been a surge of multi-modal architectures based on Large Language Models, which leverage the zero shot generation capabilities of LLMs and project image embeddings into the text space and then use the auto-regressive capacity to solve tasks such as VQA, captioning, and image retrieval. We name these architectures as "bridge-architectures" as they project from the image space to the text space. These models deviate from the traditional recipe of training transformer based multi-modal models, which involve using large-scale pre-training and complex multi-modal interactions through co or cross attention. However, the capabilities of bridge architectures have not been tested on complex visual reasoning tasks which require fine grained analysis about the image. In this project, we investigate the performance of these bridge-architectures on the NLVR2 dataset, and compare it to state-of-the-art transformer based architectures. We first extend the traditional bridge architectures for the NLVR2 dataset, by adding object level features to faciliate fine-grained object reasoning. Our analysis shows that adding object level features to bridge architectures does not help, and that pre-training on multi-modal data is key for good performance on complex reasoning tasks such as NLVR2. We also demonstrate some initial results on a recently bridge-architecture, LLaVA, in the zero shot setting and analyze its performance.
Attaining Class-level Forgetting in Pretrained Model using Few Samples
Oct 19, 2022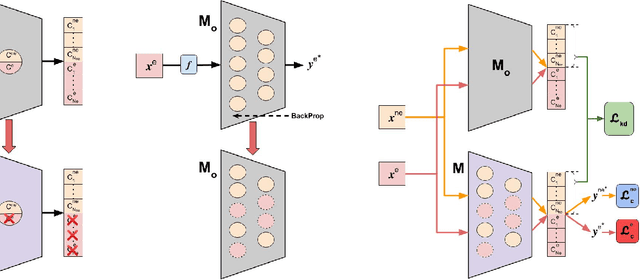
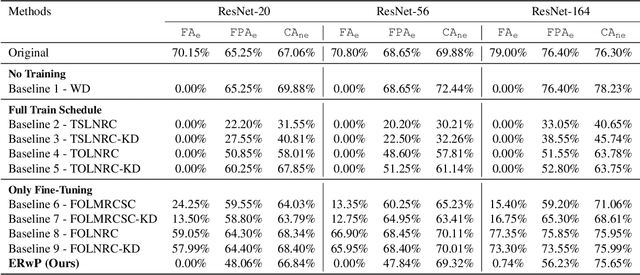
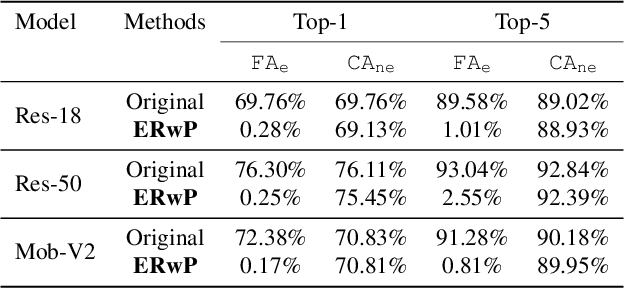

In order to address real-world problems, deep learning models are jointly trained on many classes. However, in the future, some classes may become restricted due to privacy/ethical concerns, and the restricted class knowledge has to be removed from the models that have been trained on them. The available data may also be limited due to privacy/ethical concerns, and re-training the model will not be possible. We propose a novel approach to address this problem without affecting the model's prediction power for the remaining classes. Our approach identifies the model parameters that are highly relevant to the restricted classes and removes the knowledge regarding the restricted classes from them using the limited available training data. Our approach is significantly faster and performs similar to the model re-trained on the complete data of the remaining classes.
DILF-EN framework for Class-Incremental Learning
Dec 23, 2021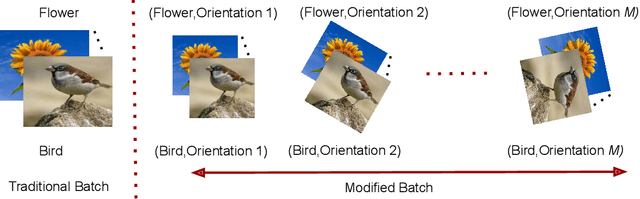
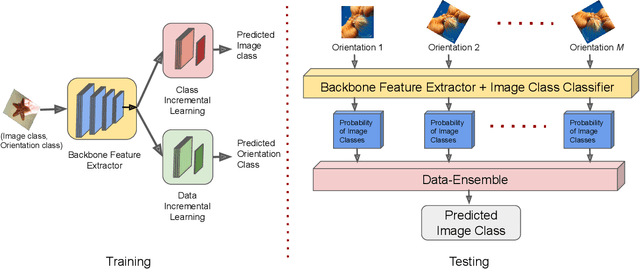

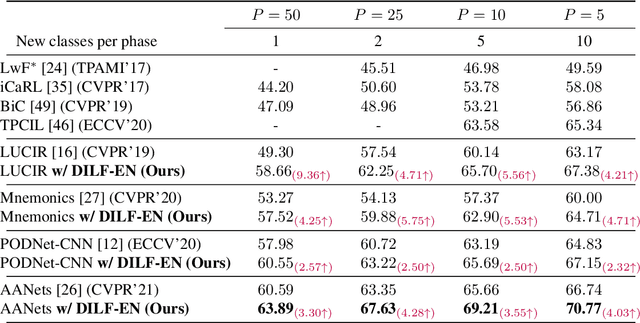
Deep learning models suffer from catastrophic forgetting of the classes in the older phases as they get trained on the classes introduced in the new phase in the class-incremental learning setting. In this work, we show that the effect of catastrophic forgetting on the model prediction varies with the change in orientation of the same image, which is a novel finding. Based on this, we propose a novel data-ensemble approach that combines the predictions for the different orientations of the image to help the model retain further information regarding the previously seen classes and thereby reduce the effect of forgetting on the model predictions. However, we cannot directly use the data-ensemble approach if the model is trained using traditional techniques. Therefore, we also propose a novel dual-incremental learning framework that involves jointly training the network with two incremental learning objectives, i.e., the class-incremental learning objective and our proposed data-incremental learning objective. In the dual-incremental learning framework, each image belongs to two classes, i.e., the image class (for class-incremental learning) and the orientation class (for data-incremental learning). In class-incremental learning, each new phase introduces a new set of classes, and the model cannot access the complete training data from the older phases. In our proposed data-incremental learning, the orientation classes remain the same across all the phases, and the data introduced by the new phase in class-incremental learning acts as new training data for these orientation classes. We empirically demonstrate that the dual-incremental learning framework is vital to the data-ensemble approach. We apply our proposed approach to state-of-the-art class-incremental learning methods and empirically show that our framework significantly improves the performance of these methods.
Knowledge Consolidation based Class Incremental Online Learning with Limited Data
Jun 12, 2021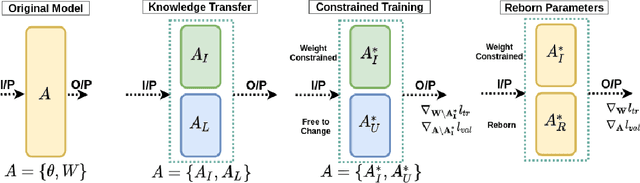
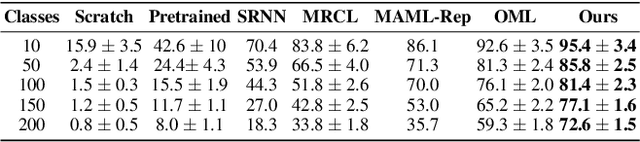
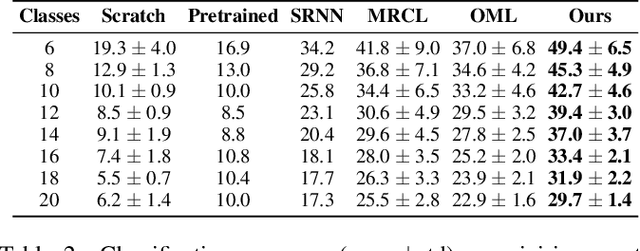
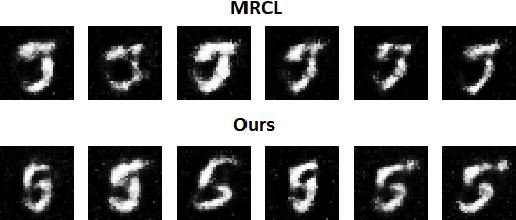
We propose a novel approach for class incremental online learning in a limited data setting. This problem setting is challenging because of the following constraints: (1) Classes are given incrementally, which necessitates a class incremental learning approach; (2) Data for each class is given in an online fashion, i.e., each training example is seen only once during training; (3) Each class has very few training examples; and (4) We do not use or assume access to any replay/memory to store data from previous classes. Therefore, in this setting, we have to handle twofold problems of catastrophic forgetting and overfitting. In our approach, we learn robust representations that are generalizable across tasks without suffering from the problems of catastrophic forgetting and overfitting to accommodate future classes with limited samples. Our proposed method leverages the meta-learning framework with knowledge consolidation. The meta-learning framework helps the model for rapid learning when samples appear in an online fashion. Simultaneously, knowledge consolidation helps to learn a robust representation against forgetting under online updates to facilitate future learning. Our approach significantly outperforms other methods on several benchmarks.