 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Stay Safe: Adaptive Regularization Against Safety Degradation during Fine-Tuning
Feb 19, 2026Instruction-following language models are trained to be helpful and safe, yet their safety behavior can deteriorate under benign fine-tuning and worsen under adversarial updates. Existing defenses often offer limited protection or force a trade-off between safety and utility. We introduce a training framework that adapts regularization in response to safety risk, enabling models to remain aligned throughout fine-tuning. To estimate safety risk at training time, we explore two distinct approaches: a judge-based Safety Critic that assigns high-level harm scores to training batches, and an activation-based risk predictor built with a lightweight classifier trained on intermediate model activations to estimate harmful intent. Each approach provides a risk signal that is used to constrain updates deemed higher risk to remain close to a safe reference policy, while lower-risk updates proceed with standard training. We empirically verify that harmful intent signals are predictable from pre-generation activations and that judge scores provide effective high-recall safety guidance. Across multiple model families and attack scenarios, adaptive regularization with either risk estimation approach consistently lowers attack success rate compared to standard fine-tuning, preserves downstream performance, and adds no inference-time cost. This work demonstrates a principled mechanism for maintaining safety without sacrificing utility.
CVOCSemRPL: Class-Variance Optimized Clustering, Semantic Information Injection and Restricted Pseudo Labeling based Improved Semi-Supervised Few-Shot Learning
Jan 24, 2025Few-shot learning has been extensively explored to address problems where the amount of labeled samples is very limited for some classes. In the semi-supervised few-shot learning setting, substantial quantities of unlabeled samples are available. Such unlabeled samples are generally cheaper to obtain and can be used to improve the few-shot learning performance of the model. Some of the recent methods for this setting rely on clustering to generate pseudo-labels for the unlabeled samples. Since the quality of the representation learned by the model heavily influences the effectiveness of clustering, this might also lead to incorrect labeling of the unlabeled samples and consequently lead to a drop in the few-shot learning performance. We propose an approach for semi-supervised few-shot learning that performs a class-variance optimized clustering in order to improve the effectiveness of clustering the labeled and unlabeled samples in this setting. It also optimizes the clustering-based pseudo-labeling process using a restricted pseudo-labeling approach and performs semantic information injection in order to improve the semi-supervised few-shot learning performance of the model. We experimentally demonstrate that our proposed approach significantly outperforms recent state-of-the-art methods on the benchmark datasets.
Hybrid Sample Synthesis-based Debiasing of Classifier in Limited Data Setting
Dec 20, 2023Deep learning models are known to suffer from the problem of bias, and researchers have been exploring methods to address this issue. However, most of these methods require prior knowledge of the bias and are not always practical. In this paper, we focus on a more practical setting with no prior information about the bias. Generally, in this setting, there are a large number of bias-aligned samples that cause the model to produce biased predictions and a few bias-conflicting samples that do not conform to the bias. If the training data is limited, the influence of the bias-aligned samples may become even stronger on the model predictions, and we experimentally demonstrate that existing debiasing techniques suffer severely in such cases. In this paper, we examine the effects of unknown bias in small dataset regimes and present a novel approach to mitigate this issue. The proposed approach directly addresses the issue of the extremely low occurrence of bias-conflicting samples in limited data settings through the synthesis of hybrid samples that can be used to reduce the effect of bias. We perform extensive experiments on several benchmark datasets and experimentally demonstrate the effectiveness of our proposed approach in addressing any unknown bias in the presence of limited data. Specifically, our approach outperforms the vanilla, LfF, LDD, and DebiAN debiasing methods by absolute margins of 10.39%, 9.08%, 8.07%, and 9.67% when only 10% of the Corrupted CIFAR-10 Type 1 dataset is available with a bias-conflicting sample ratio of 0.05.
Attaining Class-level Forgetting in Pretrained Model using Few Samples
Oct 19, 2022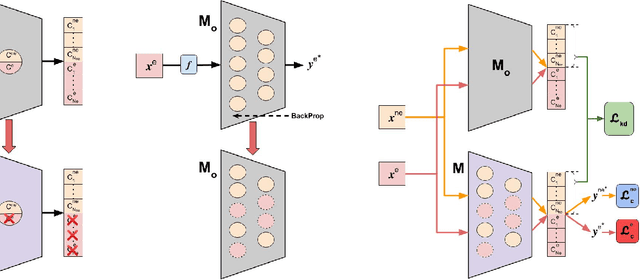
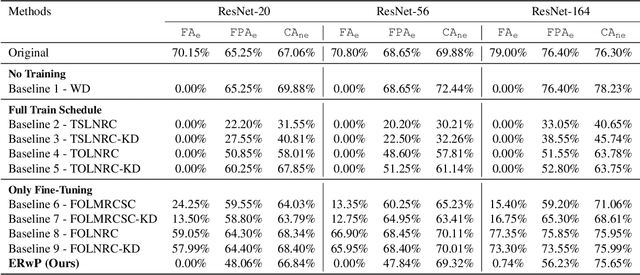
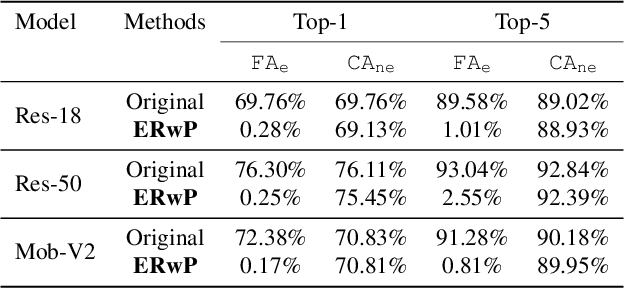

In order to address real-world problems, deep learning models are jointly trained on many classes. However, in the future, some classes may become restricted due to privacy/ethical concerns, and the restricted class knowledge has to be removed from the models that have been trained on them. The available data may also be limited due to privacy/ethical concerns, and re-training the model will not be possible. We propose a novel approach to address this problem without affecting the model's prediction power for the remaining classes. Our approach identifies the model parameters that are highly relevant to the restricted classes and removes the knowledge regarding the restricted classes from them using the limited available training data. Our approach is significantly faster and performs similar to the model re-trained on the complete data of the remaining classes.
DILF-EN framework for Class-Incremental Learning
Dec 23, 2021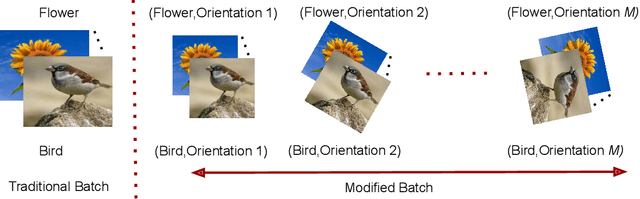
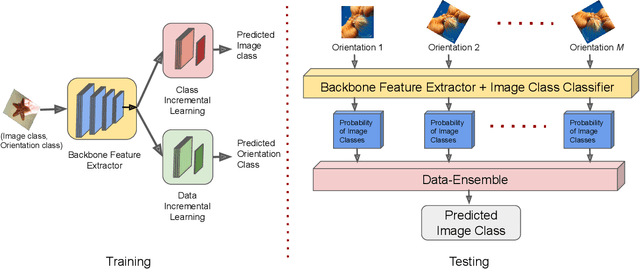

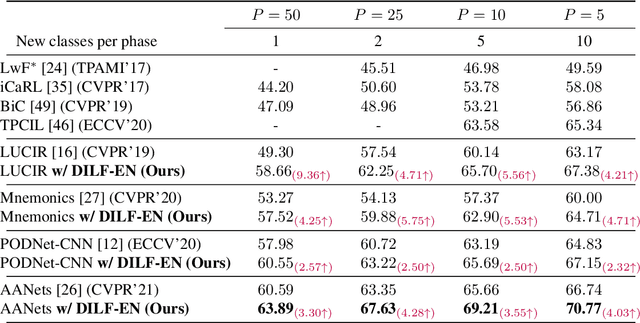
Deep learning models suffer from catastrophic forgetting of the classes in the older phases as they get trained on the classes introduced in the new phase in the class-incremental learning setting. In this work, we show that the effect of catastrophic forgetting on the model prediction varies with the change in orientation of the same image, which is a novel finding. Based on this, we propose a novel data-ensemble approach that combines the predictions for the different orientations of the image to help the model retain further information regarding the previously seen classes and thereby reduce the effect of forgetting on the model predictions. However, we cannot directly use the data-ensemble approach if the model is trained using traditional techniques. Therefore, we also propose a novel dual-incremental learning framework that involves jointly training the network with two incremental learning objectives, i.e., the class-incremental learning objective and our proposed data-incremental learning objective. In the dual-incremental learning framework, each image belongs to two classes, i.e., the image class (for class-incremental learning) and the orientation class (for data-incremental learning). In class-incremental learning, each new phase introduces a new set of classes, and the model cannot access the complete training data from the older phases. In our proposed data-incremental learning, the orientation classes remain the same across all the phases, and the data introduced by the new phase in class-incremental learning acts as new training data for these orientation classes. We empirically demonstrate that the dual-incremental learning framework is vital to the data-ensemble approach. We apply our proposed approach to state-of-the-art class-incremental learning methods and empirically show that our framework significantly improves the performance of these methods.
Fair Visual Recognition in Limited Data Regime using Self-Supervision and Self-Distillation
Jun 30, 2021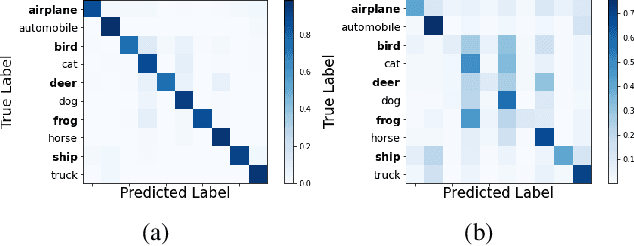
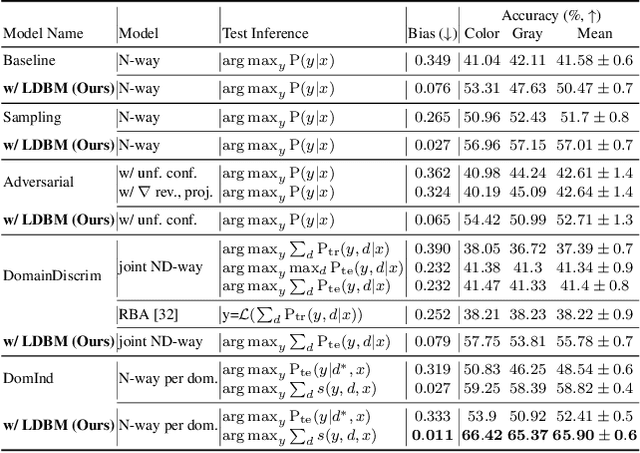
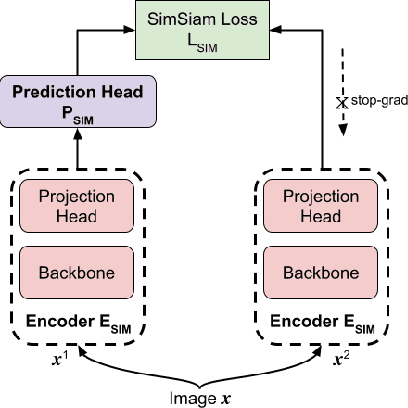
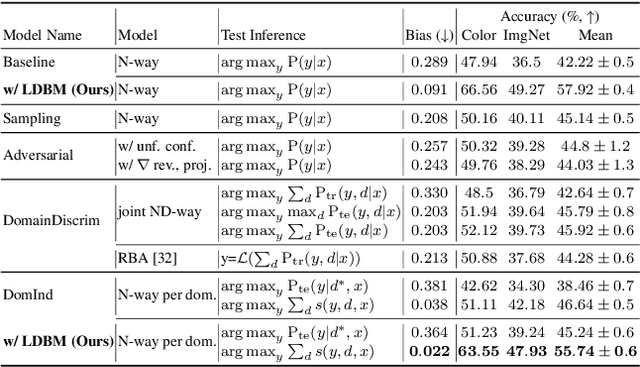
Deep learning models generally learn the biases present in the training data. Researchers have proposed several approaches to mitigate such biases and make the model fair. Bias mitigation techniques assume that a sufficiently large number of training examples are present. However, we observe that if the training data is limited, then the effectiveness of bias mitigation methods is severely degraded. In this paper, we propose a novel approach to address this problem. Specifically, we adapt self-supervision and self-distillation to reduce the impact of biases on the model in this setting. Self-supervision and self-distillation are not used for bias mitigation. However, through this work, we demonstrate for the first time that these techniques are very effective in bias mitigation. We empirically show that our approach can significantly reduce the biases learned by the model. Further, we experimentally demonstrate that our approach is complementary to other bias mitigation strategies. Our approach significantly improves their performance and further reduces the model biases in the limited data regime. Specifically, on the L-CIFAR-10S skewed dataset, our approach significantly reduces the bias score of the baseline model by 78.22% and outperforms it in terms of accuracy by a significant absolute margin of 8.89%. It also significantly reduces the bias score for the state-of-the-art domain independent bias mitigation method by 59.26% and improves its performance by a significant absolute margin of 7.08%.
Rectification-based Knowledge Retention for Continual Learning
Mar 30, 2021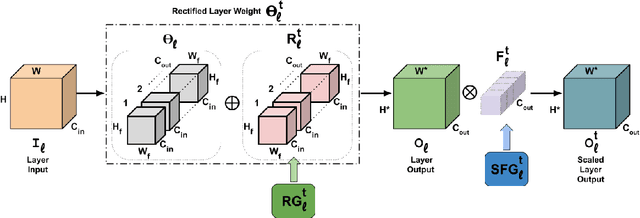
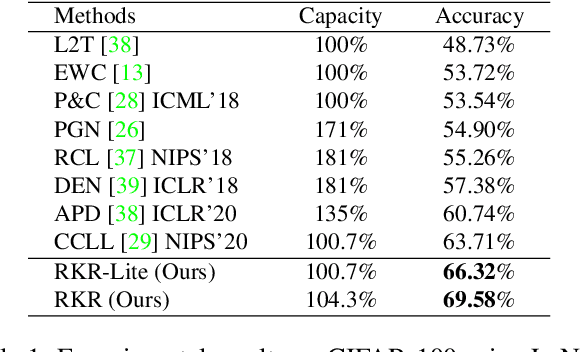

Deep learning models suffer from catastrophic forgetting when trained in an incremental learning setting. In this work, we propose a novel approach to address the task incremental learning problem, which involves training a model on new tasks that arrive in an incremental manner. The task incremental learning problem becomes even more challenging when the test set contains classes that are not part of the train set, i.e., a task incremental generalized zero-shot learning problem. Our approach can be used in both the zero-shot and non zero-shot task incremental learning settings. Our proposed method uses weight rectifications and affine transformations in order to adapt the model to different tasks that arrive sequentially. Specifically, we adapt the network weights to work for new tasks by "rectifying" the weights learned from the previous task. We learn these weight rectifications using very few parameters. We additionally learn affine transformations on the outputs generated by the network in order to better adapt them for the new task. We perform experiments on several datasets in both zero-shot and non zero-shot task incremental learning settings and empirically show that our approach achieves state-of-the-art results. Specifically, our approach outperforms the state-of-the-art non zero-shot task incremental learning method by over 5% on the CIFAR-100 dataset. Our approach also significantly outperforms the state-of-the-art task incremental generalized zero-shot learning method by absolute margins of 6.91% and 6.33% for the AWA1 and CUB datasets, respectively. We validate our approach using various ablation studies.
Few-Shot Lifelong Learning
Mar 01, 2021
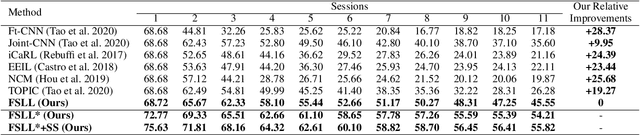
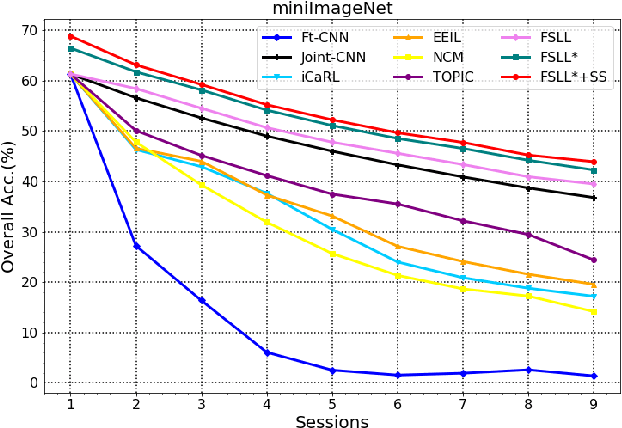

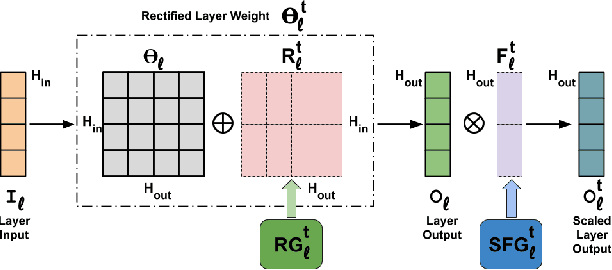
Many real-world classification problems often have classes with very few labeled training samples. Moreover, all possible classes may not be initially available for training, and may be given incrementally. Deep learning models need to deal with this two-fold problem in order to perform well in real-life situations. In this paper, we propose a novel Few-Shot Lifelong Learning (FSLL) method that enables deep learning models to perform lifelong/continual learning on few-shot data. Our method selects very few parameters from the model for training every new set of classes instead of training the full model. This helps in preventing overfitting. We choose the few parameters from the model in such a way that only the currently unimportant parameters get selected. By keeping the important parameters in the model intact, our approach minimizes catastrophic forgetting. Furthermore, we minimize the cosine similarity between the new and the old class prototypes in order to maximize their separation, thereby improving the classification performance. We also show that integrating our method with self-supervision improves the model performance significantly. We experimentally show that our method significantly outperforms existing methods on the miniImageNet, CIFAR-100, and CUB-200 datasets. Specifically, we outperform the state-of-the-art method by an absolute margin of 19.27% for the CUB dataset.
RNNP: A Robust Few-Shot Learning Approach
Nov 22, 2020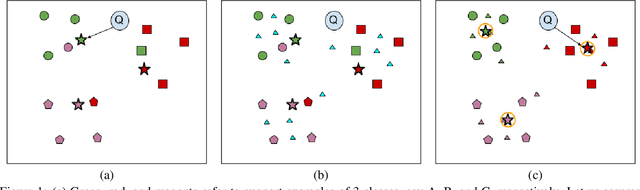


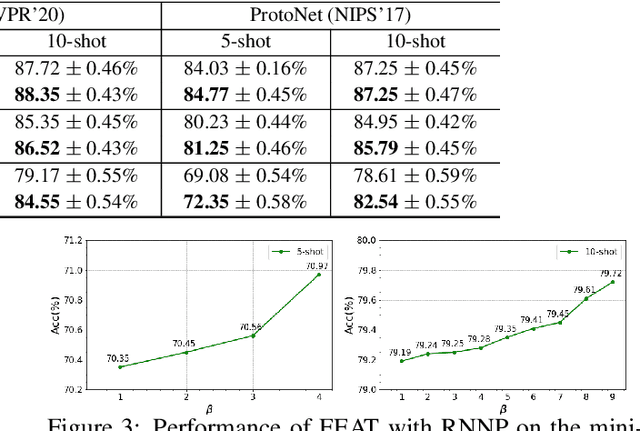
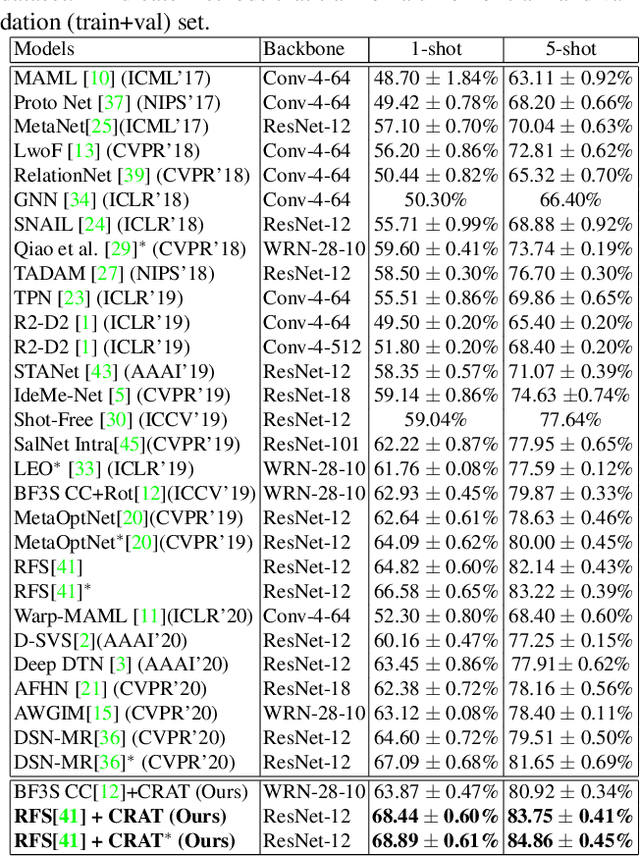
Learning from a few examples is an important practical aspect of training classifiers. Various works have examined this aspect quite well. However, all existing approaches assume that the few examples provided are always correctly labeled. This is a strong assumption, especially if one considers the current techniques for labeling using crowd-based labeling services. We address this issue by proposing a novel robust few-shot learning approach. Our method relies on generating robust prototypes from a set of few examples. Specifically, our method refines the class prototypes by producing hybrid features from the support examples of each class. The refined prototypes help to classify the query images better. Our method can replace the evaluation phase of any few-shot learning method that uses a nearest neighbor prototype-based evaluation procedure to make them robust. We evaluate our method on standard mini-ImageNet and tiered-ImageNet datasets. We perform experiments with various label corruption rates in the support examples of the few-shot classes. We obtain significant improvement over widely used few-shot learning methods that suffer significant performance degeneration in the presence of label noise. We finally provide extensive ablation experiments to validate our method.
Improving Few-Shot Learning using Composite Rotation based Auxiliary Task
Jun 29, 2020
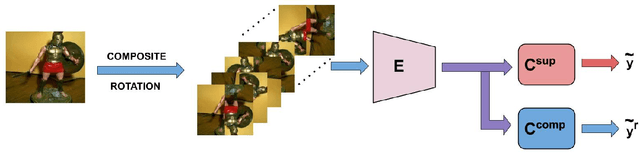
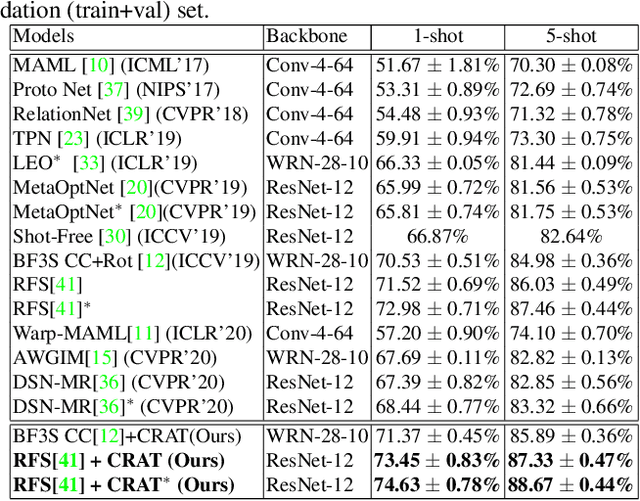
In this paper, we propose an approach to improve few-shot classification performance using a composite rotation based auxiliary task. Few-shot classification methods aim to produce neural networks that perform well for classes with a large number of training samples and classes with less number of training samples. They employ techniques to enable the network to produce highly discriminative features that are also very generic. Generally, the better the quality and generic-nature of the features produced by the network, the better is the performance of the network on few-shot learning. Our approach aims to train networks to produce such features by using a self-supervised auxiliary task. Our proposed composite rotation based auxiliary task performs rotation at two levels, i.e., rotation of patches inside the image (inner rotation) and rotation of the whole image (outer rotation) and assigns one out of 16 rotation classes to the modified image. We then simultaneously train for the composite rotation prediction task along with the original classification task, which forces the network to learn high-quality generic features that help improve the few-shot classification performance. We experimentally show that our approach performs better than existing few-shot learning methods on multiple benchmark datasets.