 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Visual Recognition in Limited Data Regime using Self-Supervision and Self-Distillation
Paper and Code
Jun 30, 2021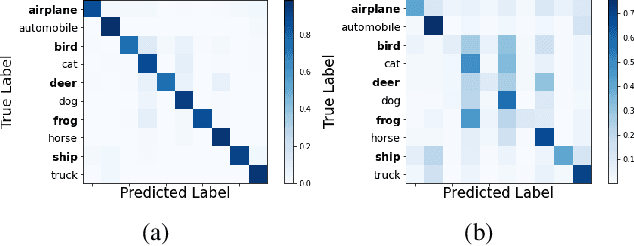
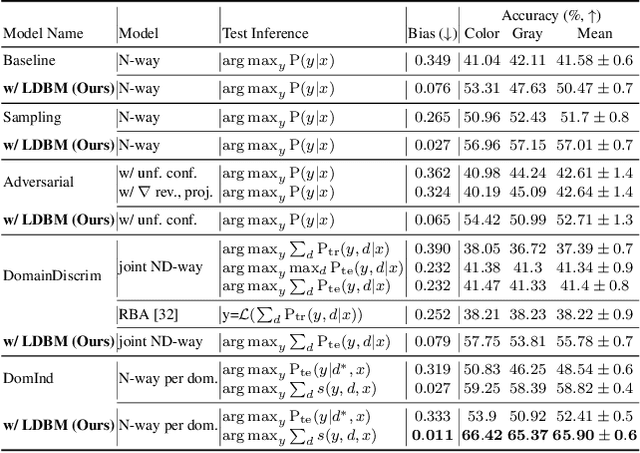
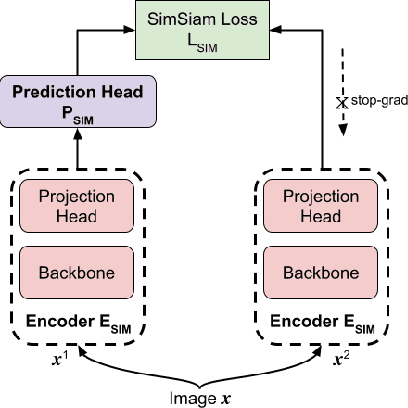
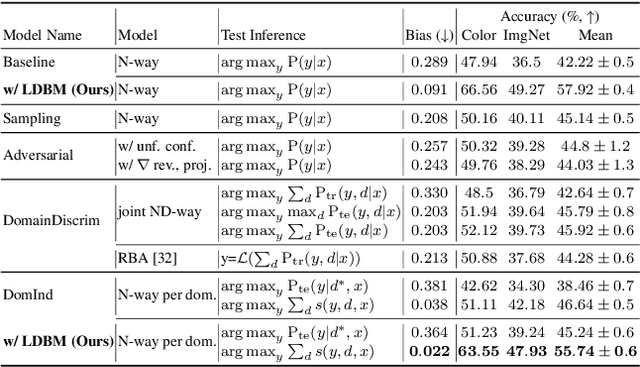
Deep learning models generally learn the biases present in the training data. Researchers have proposed several approaches to mitigate such biases and make the model fair. Bias mitigation techniques assume that a sufficiently large number of training examples are present. However, we observe that if the training data is limited, then the effectiveness of bias mitigation methods is severely degraded. In this paper, we propose a novel approach to address this problem. Specifically, we adapt self-supervision and self-distillation to reduce the impact of biases on the model in this setting. Self-supervision and self-distillation are not used for bias mitigation. However, through this work, we demonstrate for the first time that these techniques are very effective in bias mitigation. We empirically show that our approach can significantly reduce the biases learned by the model. Further, we experimentally demonstrate that our approach is complementary to other bias mitigation strategies. Our approach significantly improves their performance and further reduces the model biases in the limited data regime. Specifically, on the L-CIFAR-10S skewed dataset, our approach significantly reduces the bias score of the baseline model by 78.22% and outperforms it in terms of accuracy by a significant absolute margin of 8.89%. It also significantly reduces the bias score for the state-of-the-art domain independent bias mitigation method by 59.26% and improves its performance by a significant absolute margin of 7.08%.