 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKG-FRUS: a Novel Graph-based Dataset of 127 Years of US Diplomatic Relations
Oct 30, 2023

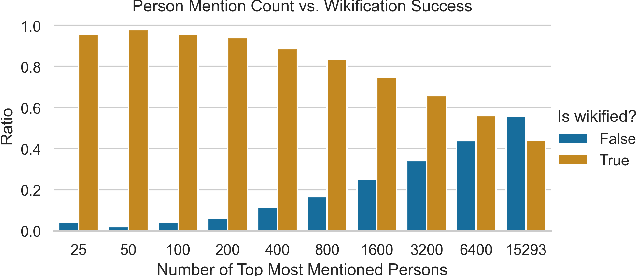

In the current paper, we present the KG-FRUS dataset, comprised of more than 300,000 US government diplomatic documents encoded in a Knowledge Graph (KG). We leverage the data of the Foreign Relations of the United States (FRUS) (available as XML files) to extract information about the documents and the individuals and countries mentioned within them. We use the extracted entities, and associated metadata, to create a graph-based dataset. Further, we supplement the created KG with additional entities and relations from Wikidata. The relations in the KG capture the synergies and dynamics required to study and understand the complex fields of diplomacy, foreign relations, and politics. This goes well beyond a simple collection of documents which neglects the relations between entities in the text. We showcase a range of possibilities of the current dataset by illustrating different approaches to probe the KG. In the paper, we exemplify how to use a query language to answer simple research questions and how to use graph algorithms such as Node2Vec and PageRank, that benefit from the complete graph structure. More importantly, the chosen structure provides total flexibility for continuously expanding and enriching the graph. Our solution is general, so the proposed pipeline for building the KG can encode other original corpora of time-dependent and complex phenomena. Overall, we present a mechanism to create KG databases providing a more versatile representation of time-dependent related text data and a particular application to the all-important FRUS database.
Regularizing Transformers With Deep Probabilistic Layers
Aug 23, 2021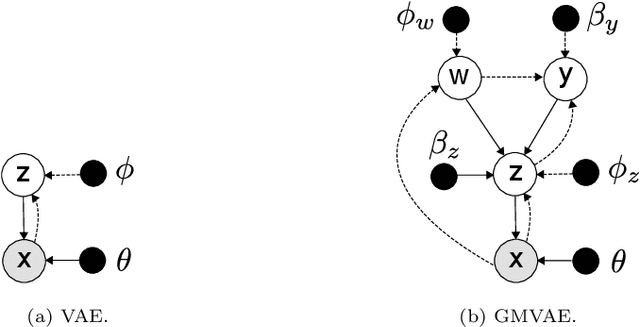
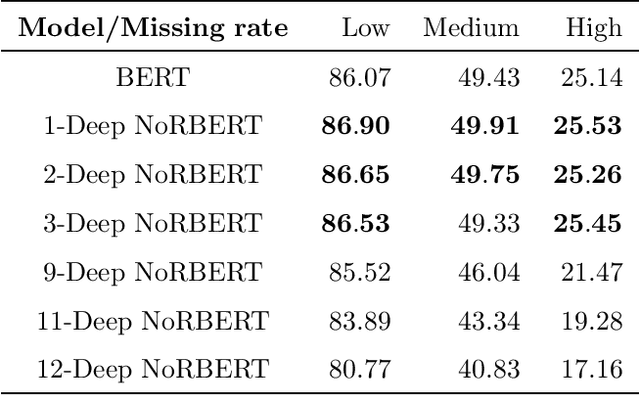
Language models (LM) have grown with non-stop in the last decade, from sequence-to-sequence architectures to the state-of-the-art and utter attention-based Transformers. In this work, we demonstrate how the inclusion of deep generative models within BERT can bring more versatile models, able to impute missing/noisy words with richer text or even improve BLEU score. More precisely, we use a Gaussian Mixture Variational Autoencoder (GMVAE) as a regularizer layer and prove its effectiveness not only in Transformers but also in the most relevant encoder-decoder based LM, seq2seq with and without attention.
Robust Sampling in Deep Learning
Jun 05, 2020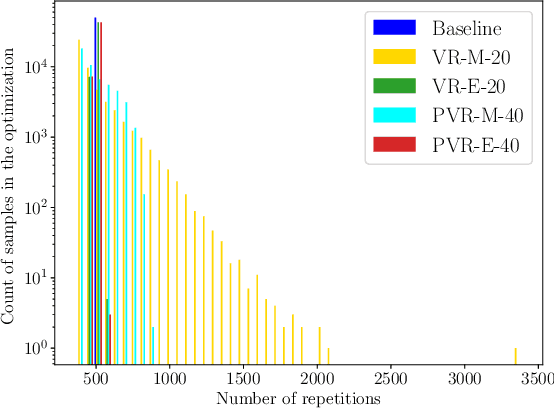

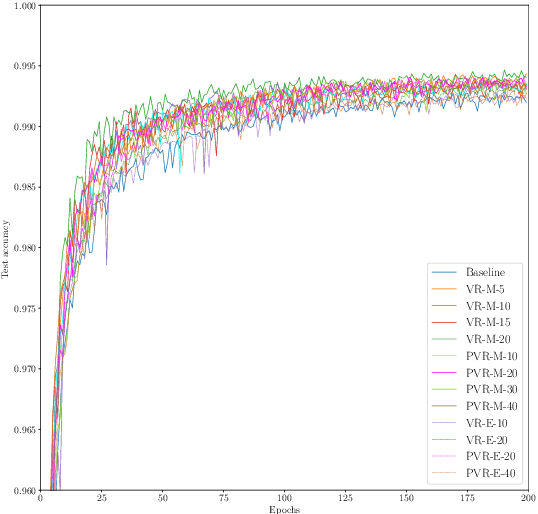

Deep learning requires regularization mechanisms to reduce overfitting and improve generalization. We address this problem by a new regularization method based on distributional robust optimization. The key idea is to modify the contribution from each sample for tightening the empirical risk bound. During the stochastic training, the selection of samples is done according to their accuracy in such a way that the worst performed samples are the ones that contribute the most in the optimization. We study different scenarios and show the ones where it can make the convergence faster or increase the accuracy.
Out-of-Sample Testing for GANs
Jan 28, 2019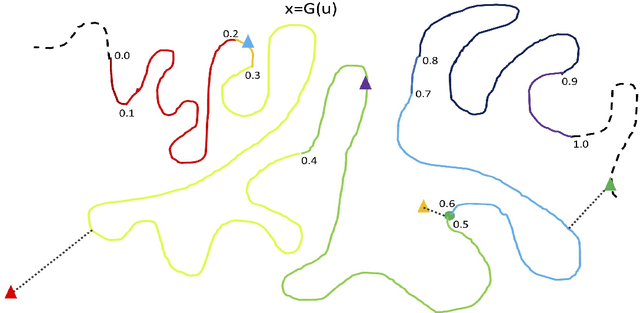
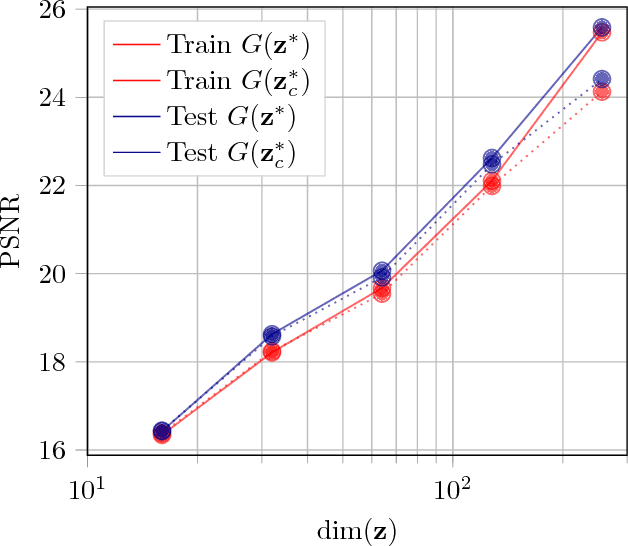
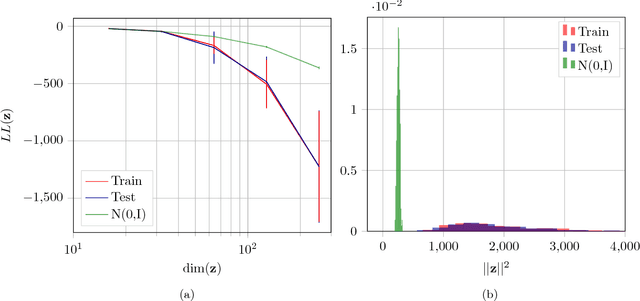

We propose a new method to evaluate GANs, namely EvalGAN. EvalGAN relies on a test set to directly measure the reconstruction quality in the original sample space (no auxiliary networks are necessary), and it also computes the (log)likelihood for the reconstructed samples in the test set. Further, EvalGAN is agnostic to the GAN algorithm and the dataset. We decided to test it on three state-of-the-art GANs over the well-known CIFAR-10 and CelebA datasets.
Complex-Valued Kernel Methods for Regression
Oct 31, 2016
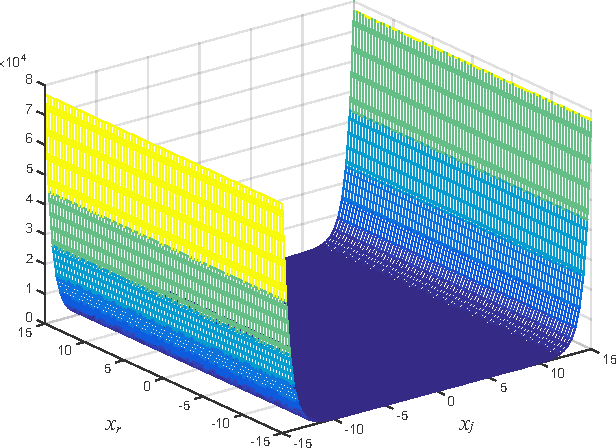
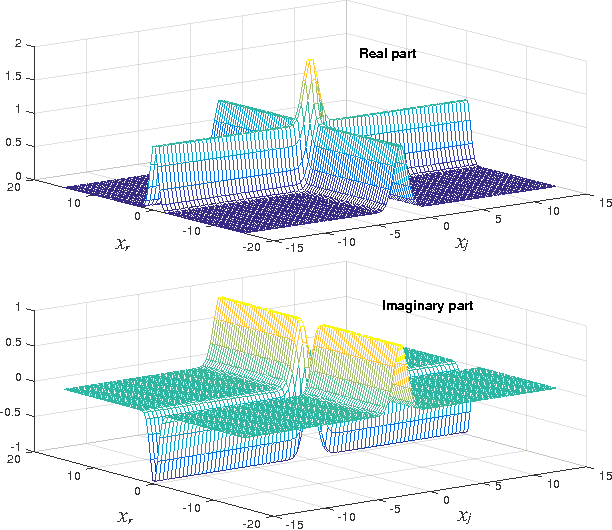
Usually, complex-valued RKHS are presented as an straightforward application of the real-valued case. In this paper we prove that this procedure yields a limited solution for regression. We show that another kernel, here denoted as pseudo kernel, is needed to learn any function in complex-valued fields. Accordingly, we derive a novel RKHS to include it, the widely RKHS (WRKHS). When the pseudo-kernel cancels, WRKHS reduces to complex-valued RKHS of previous approaches. We address the kernel and pseudo-kernel design, paying attention to the kernel and the pseudo-kernel being complex-valued. In the experiments included we report remarkable improvements in simple scenarios where real a imaginary parts have different similitude relations for given inputs or cases where real and imaginary parts are correlated. In the context of these novel results we revisit the problem of non-linear channel equalization, to show that the WRKHS helps to design more efficient solutions.
* 8 pages, 9 figures
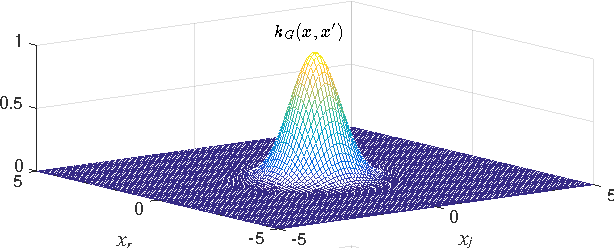
Gaussian Processes for Nonlinear Signal Processing
Sep 27, 2013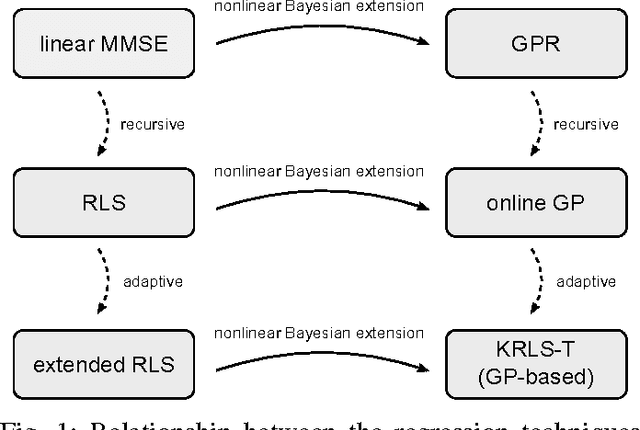
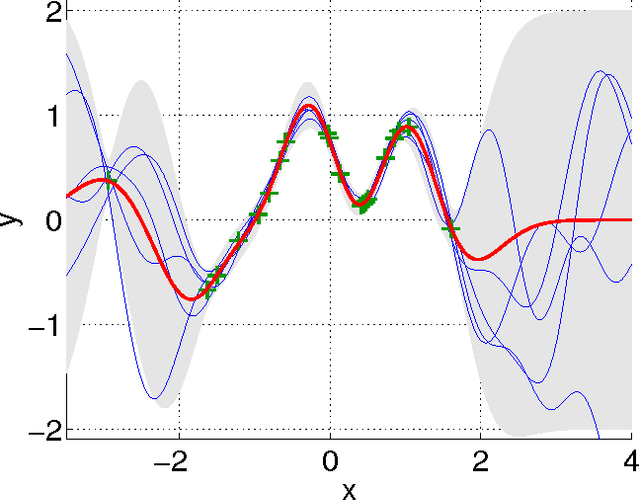
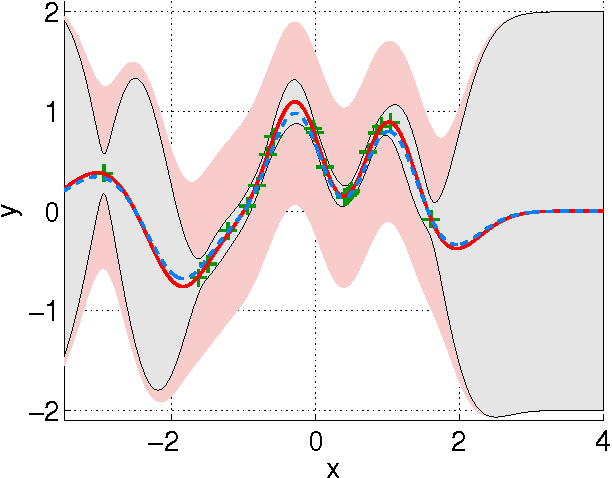

Gaussian processes (GPs) are versatile tools that have been successfully employed to solve nonlinear estimation problems in machine learning, but that are rarely used in signal processing. In this tutorial, we present GPs for regression as a natural nonlinear extension to optimal Wiener filtering. After establishing their basic formulation, we discuss several important aspects and extensions, including recursive and adaptive algorithms for dealing with non-stationarity, low-complexity solutions, non-Gaussian noise models and classification scenarios. Furthermore, we provide a selection of relevant applications to wireless digital communications.