Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Sampling in Deep Learning
Paper and Code
Jun 05, 2020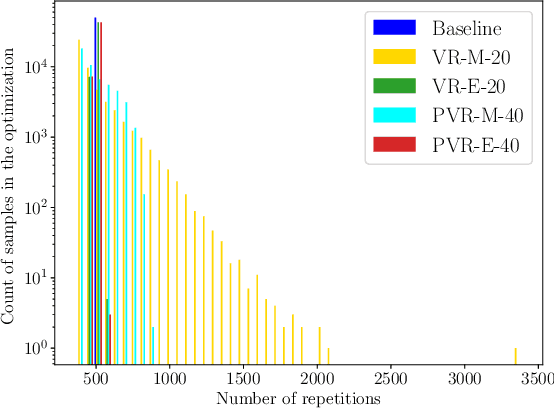

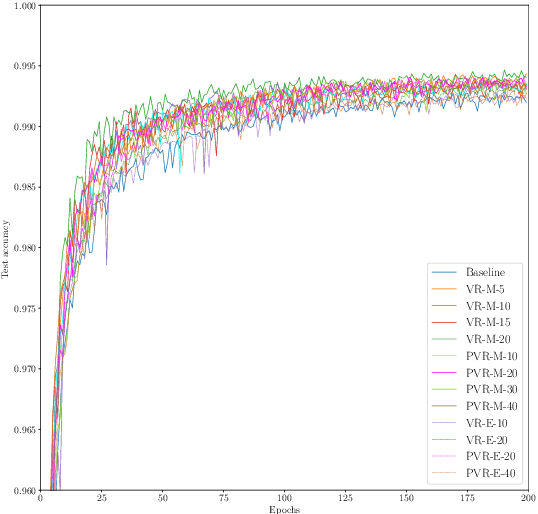

Deep learning requires regularization mechanisms to reduce overfitting and improve generalization. We address this problem by a new regularization method based on distributional robust optimization. The key idea is to modify the contribution from each sample for tightening the empirical risk bound. During the stochastic training, the selection of samples is done according to their accuracy in such a way that the worst performed samples are the ones that contribute the most in the optimization. We study different scenarios and show the ones where it can make the convergence faster or increase the accuracy.
* 8 pages, 3 figures
View paper on