 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of CNN Optimization Methods for Edge AI: Exploring the Role of Early Exits
Apr 16, 2026Deploying deep neural networks on edge devices requires balancing accuracy, latency, and resource constraints under realistic execution conditions. To fit models within these constraints, two broad strategies have emerged: static compression techniques such as pruning and quantization, which permanently reduce model size, and dynamic approaches such as early-exit mechanisms, which adapt computational cost at runtime. While both families are widely studied in isolation, they are rarely compared under identical conditions on physical hardware. This paper presents a unified deployment-oriented comparison of static compression and dynamic early-exit mechanisms, evaluated on real edge devices using ONNX based inference pipelines. Our results show that static and dynamic techniques offer fundamentally different trade-offs for edge deployment. While pruning and quantization deliver consistent memory footprint reduction, early-exit mechanisms enable input-adaptive computation savings that static methods cannot match. Their combination proves highly effective, simultaneously reducing inference latency and memory usage with minimal accuracy loss, expanding what is achievable at the edge.
A Classification of Artificial Intelligence Systems for Mathematics Education
Jul 13, 2021

This chapter provides an overview of the different Artificial Intelligence (AI) systems that are being used in contemporary digital tools for Mathematics Education (ME). It is aimed at researchers in AI and Machine Learning (ML), for whom we shed some light on the specific technologies that are being used in educational applications; and at researchers in ME, for whom we clarify: i) what the possibilities of the current AI technologies are, ii) what is still out of reach and iii) what is to be expected in the near future. We start our analysis by establishing a high-level taxonomy of AI tools that are found as components in digital ME applications. Then, we describe in detail how these AI tools, and in particular ML, are being used in two key applications, specifically AI-based calculators and intelligent tutoring systems. We finish the chapter with a discussion about student modeling systems and their relationship to artificial general intelligence.
On the Stability and Generalization of Learning with Kernel Activation Functions
Mar 28, 2019
In this brief we investigate the generalization properties of a recently-proposed class of non-parametric activation functions, the kernel activation functions (KAFs). KAFs introduce additional parameters in the learning process in order to adapt nonlinearities individually on a per-neuron basis, exploiting a cheap kernel expansion of every activation value. While this increase in flexibility has been shown to provide significant improvements in practice, a theoretical proof for its generalization capability has not been addressed yet in the literature. Here, we leverage recent literature on the stability properties of non-convex models trained via stochastic gradient descent (SGD). By indirectly proving two key smoothness properties of the models under consideration, we prove that neural networks endowed with KAFs generalize well when trained with SGD for a finite number of steps. Interestingly, our analysis provides a guideline for selecting one of the hyper-parameters of the model, the bandwidth of the scalar Gaussian kernel. A short experimental evaluation validates the proof.
Widely Linear Kernels for Complex-Valued Kernel Activation Functions
Feb 06, 2019
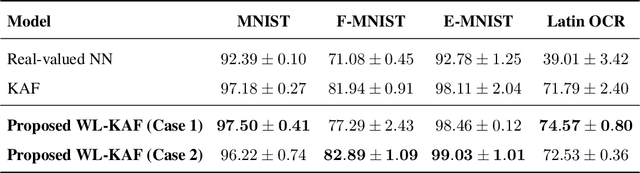
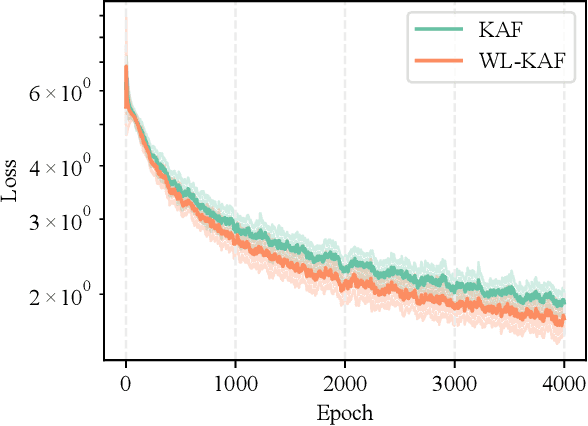
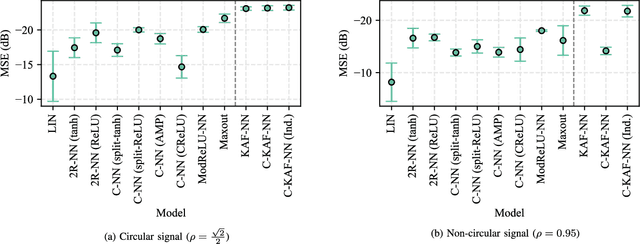
Complex-valued neural networks (CVNNs) have been shown to be powerful nonlinear approximators when the input data can be properly modeled in the complex domain. One of the major challenges in scaling up CVNNs in practice is the design of complex activation functions. Recently, we proposed a novel framework for learning these activation functions neuron-wise in a data-dependent fashion, based on a cheap one-dimensional kernel expansion and the idea of kernel activation functions (KAFs). In this paper we argue that, despite its flexibility, this framework is still limited in the class of functions that can be modeled in the complex domain. We leverage the idea of widely linear complex kernels to extend the formulation, allowing for a richer expressiveness without an increase in the number of adaptable parameters. We test the resulting model on a set of complex-valued image classification benchmarks. Experimental results show that the resulting CVNNs can achieve higher accuracy while at the same time converging faster.
Recurrent Neural Networks with Flexible Gates using Kernel Activation Functions
Jul 11, 2018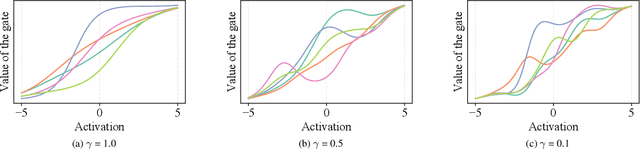
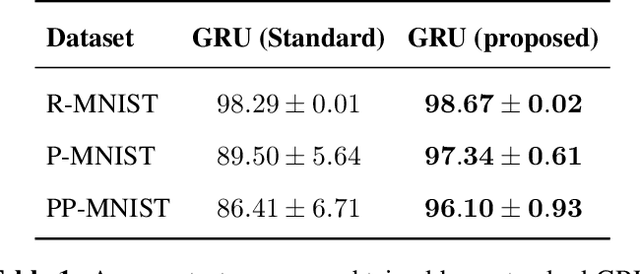
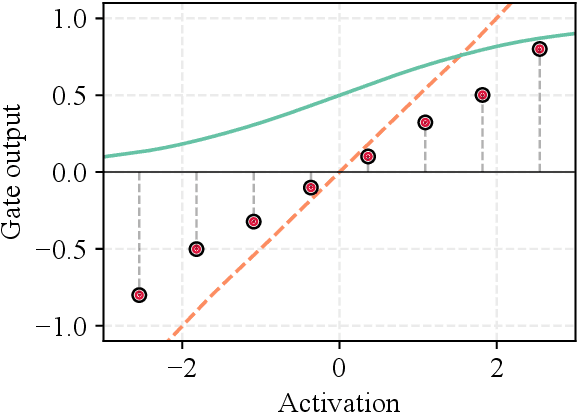
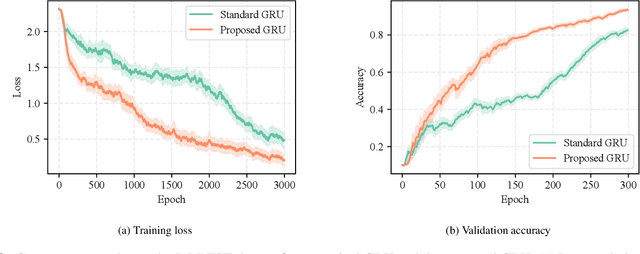
Gated recurrent neural networks have achieved remarkable results in the analysis of sequential data. Inside these networks, gates are used to control the flow of information, allowing to model even very long-term dependencies in the data. In this paper, we investigate whether the original gate equation (a linear projection followed by an element-wise sigmoid) can be improved. In particular, we design a more flexible architecture, with a small number of adaptable parameters, which is able to model a wider range of gating functions than the classical one. To this end, we replace the sigmoid function in the standard gate with a non-parametric formulation extending the recently proposed kernel activation function (KAF), with the addition of a residual skip-connection. A set of experiments on sequential variants of the MNIST dataset shows that the adoption of this novel gate allows to improve accuracy with a negligible cost in terms of computational power and with a large speed-up in the number of training iterations.
Improving Graph Convolutional Networks with Non-Parametric Activation Functions
Feb 26, 2018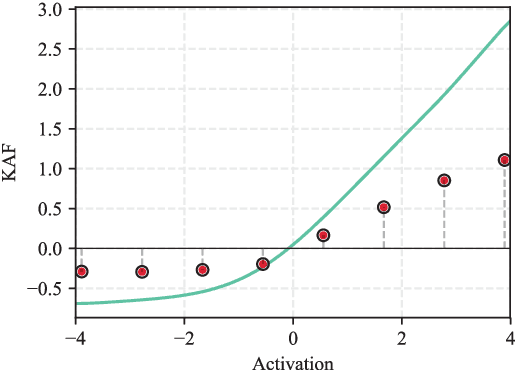
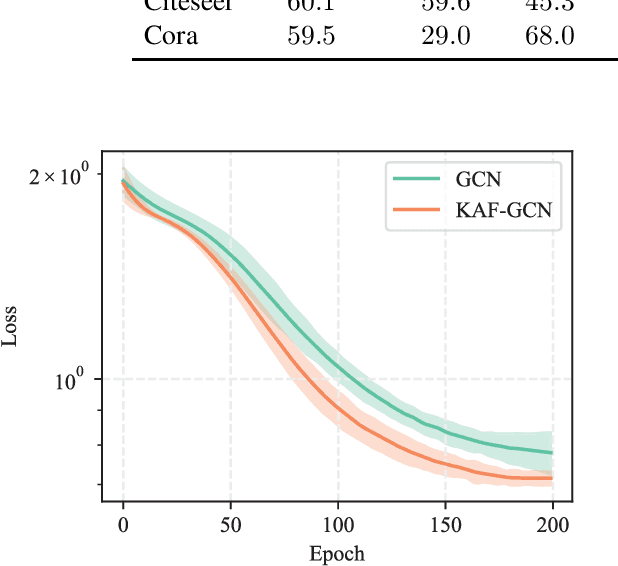
Graph neural networks (GNNs) are a class of neural networks that allow to efficiently perform inference on data that is associated to a graph structure, such as, e.g., citation networks or knowledge graphs. While several variants of GNNs have been proposed, they only consider simple nonlinear activation functions in their layers, such as rectifiers or squashing functions. In this paper, we investigate the use of graph convolutional networks (GCNs) when combined with more complex activation functions, able to adapt from the training data. More specifically, we extend the recently proposed kernel activation function, a non-parametric model which can be implemented easily, can be regularized with standard $\ell_p$-norms techniques, and is smooth over its entire domain. Our experimental evaluation shows that the proposed architecture can significantly improve over its baseline, while similar improvements cannot be obtained by simply increasing the depth or size of the original GCN.
Complex-valued Neural Networks with Non-parametric Activation Functions
Feb 22, 2018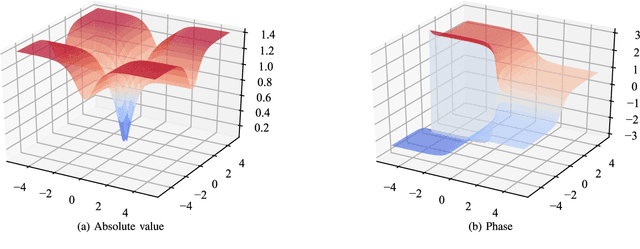
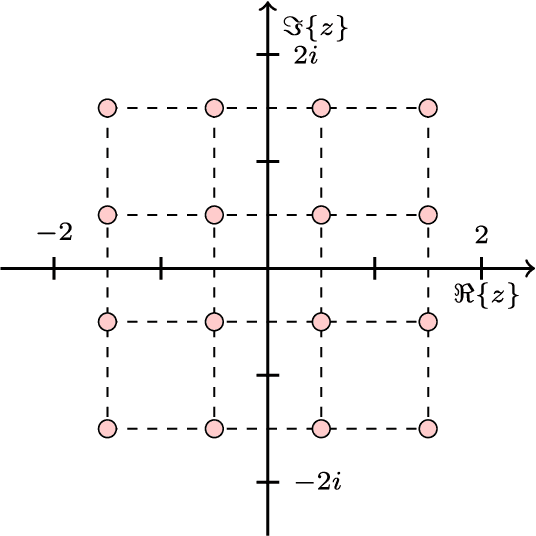
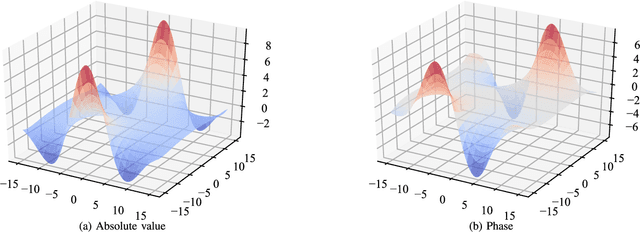
Complex-valued neural networks (CVNNs) are a powerful modeling tool for domains where data can be naturally interpreted in terms of complex numbers. However, several analytical properties of the complex domain (e.g., holomorphicity) make the design of CVNNs a more challenging task than their real counterpart. In this paper, we consider the problem of flexible activation functions (AFs) in the complex domain, i.e., AFs endowed with sufficient degrees of freedom to adapt their shape given the training data. While this problem has received considerable attention in the real case, a very limited literature exists for CVNNs, where most activation functions are generally developed in a split fashion (i.e., by considering the real and imaginary parts of the activation separately) or with simple phase-amplitude techniques. Leveraging over the recently proposed kernel activation functions (KAFs), and related advances in the design of complex-valued kernels, we propose the first fully complex, non-parametric activation function for CVNNs, which is based on a kernel expansion with a fixed dictionary that can be implemented efficiently on vectorized hardware. Several experiments on common use cases, including prediction and channel equalization, validate our proposal when compared to real-valued neural networks and CVNNs with fixed activation functions.
Pattern Localization in Time Series through Signal-To-Model Alignment in Latent Space
Feb 19, 2018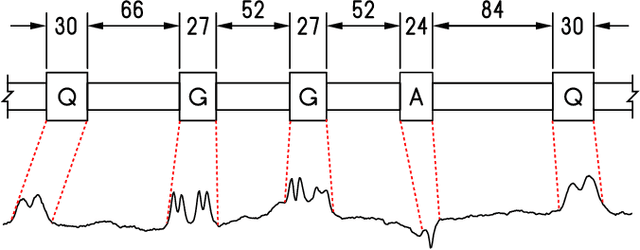
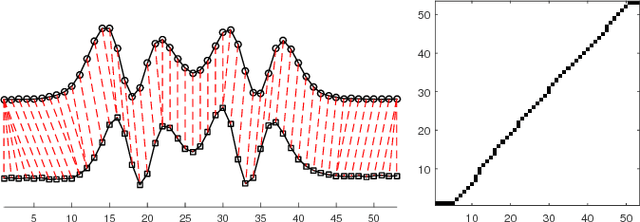

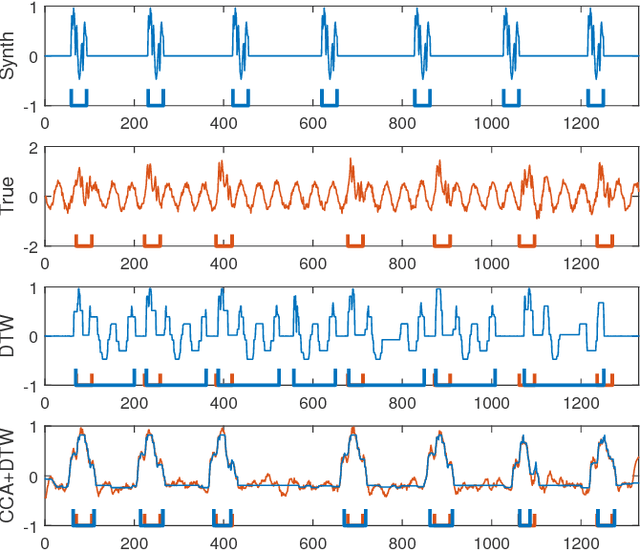
In this paper, we study the problem of locating a predefined sequence of patterns in a time series. In particular, the studied scenario assumes a theoretical model is available that contains the expected locations of the patterns. This problem is found in several contexts, and it is commonly solved by first synthesizing a time series from the model, and then aligning it to the true time series through dynamic time warping. We propose a technique that increases the similarity of both time series before aligning them, by mapping them into a latent correlation space. The mapping is learned from the data through a machine-learning setup. Experiments on data from non-destructive testing demonstrate that the proposed approach shows significant improvements over the state of the art.
Kafnets: kernel-based non-parametric activation functions for neural networks
Nov 23, 2017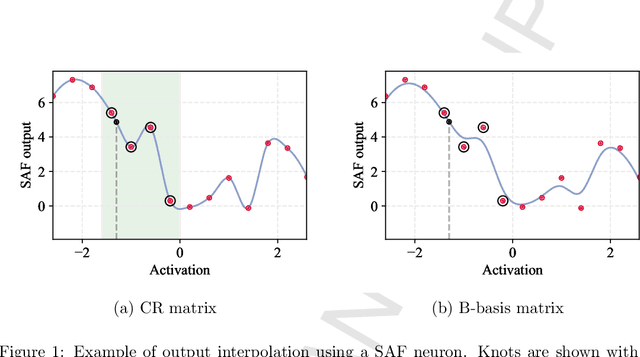
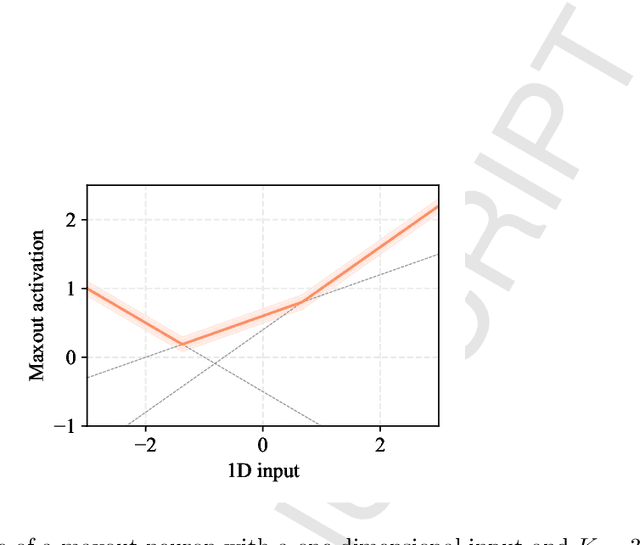
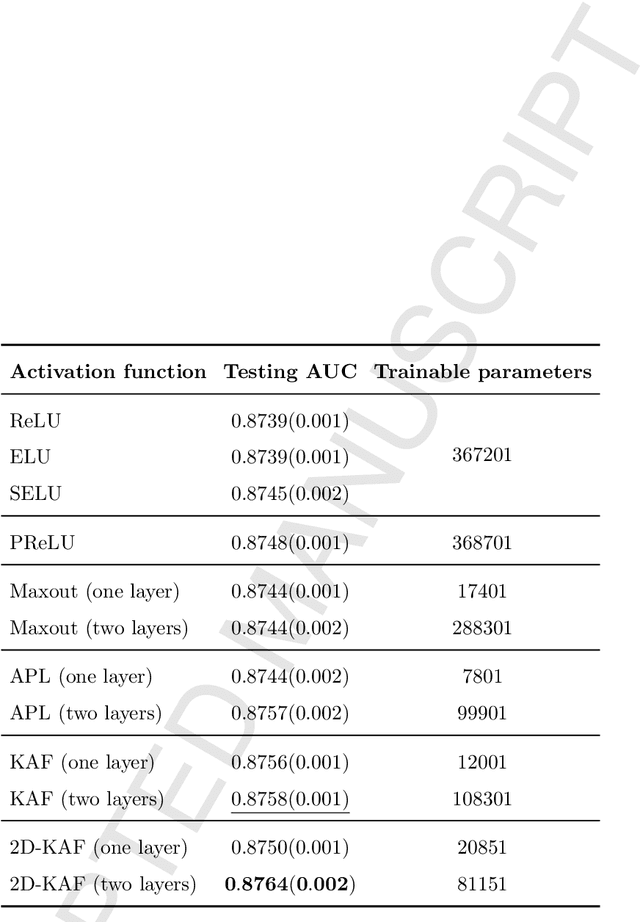
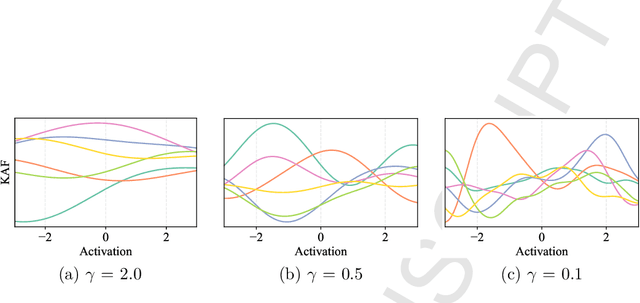
Neural networks are generally built by interleaving (adaptable) linear layers with (fixed) nonlinear activation functions. To increase their flexibility, several authors have proposed methods for adapting the activation functions themselves, endowing them with varying degrees of flexibility. None of these approaches, however, have gained wide acceptance in practice, and research in this topic remains open. In this paper, we introduce a novel family of flexible activation functions that are based on an inexpensive kernel expansion at every neuron. Leveraging over several properties of kernel-based models, we propose multiple variations for designing and initializing these kernel activation functions (KAFs), including a multidimensional scheme allowing to nonlinearly combine information from different paths in the network. The resulting KAFs can approximate any mapping defined over a subset of the real line, either convex or nonconvex. Furthermore, they are smooth over their entire domain, linear in their parameters, and they can be regularized using any known scheme, including the use of $\ell_1$ penalties to enforce sparseness. To the best of our knowledge, no other known model satisfies all these properties simultaneously. In addition, we provide a relatively complete overview on alternative techniques for adapting the activation functions, which is currently lacking in the literature. A large set of experiments validates our proposal.
Recursive Multikernel Filters Exploiting Nonlinear Temporal Structure
Jun 12, 2017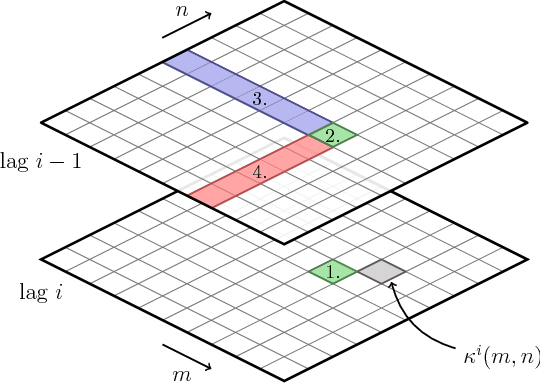
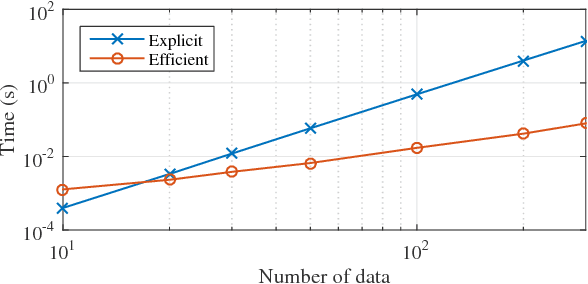
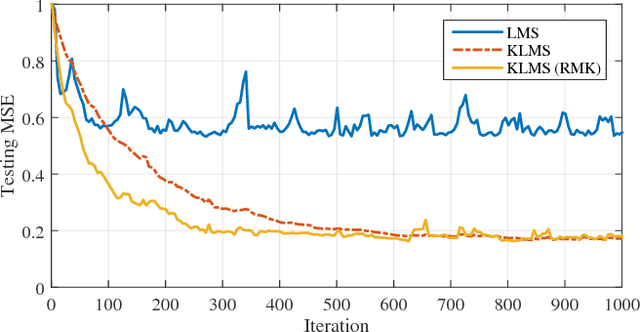
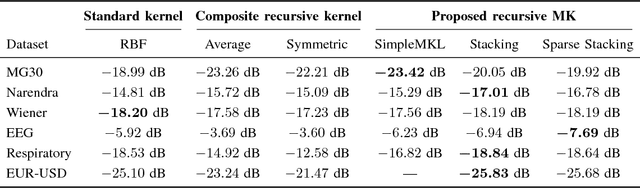
In kernel methods, temporal information on the data is commonly included by using time-delayed embeddings as inputs. Recently, an alternative formulation was proposed by defining a gamma-filter explicitly in a reproducing kernel Hilbert space, giving rise to a complex model where multiple kernels operate on different temporal combinations of the input signal. In the original formulation, the kernels are then simply combined to obtain a single kernel matrix (for instance by averaging), which provides computational benefits but discards important information on the temporal structure of the signal. Inspired by works on multiple kernel learning, we overcome this drawback by considering the different kernels separately. We propose an efficient strategy to adaptively combine and select these kernels during the training phase. The resulting batch and online algorithms automatically learn to process highly nonlinear temporal information extracted from the input signal, which is implicitly encoded in the kernel values. We evaluate our proposal on several artificial and real tasks, showing that it can outperform classical approaches both in batch and online settings.