 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Stability and Generalization of Learning with Kernel Activation Functions
Paper and Code
Mar 28, 2019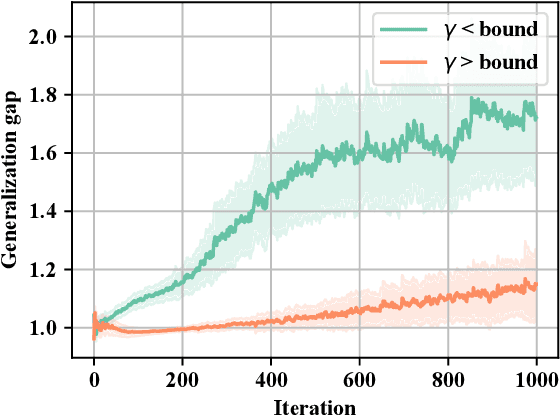
In this brief we investigate the generalization properties of a recently-proposed class of non-parametric activation functions, the kernel activation functions (KAFs). KAFs introduce additional parameters in the learning process in order to adapt nonlinearities individually on a per-neuron basis, exploiting a cheap kernel expansion of every activation value. While this increase in flexibility has been shown to provide significant improvements in practice, a theoretical proof for its generalization capability has not been addressed yet in the literature. Here, we leverage recent literature on the stability properties of non-convex models trained via stochastic gradient descent (SGD). By indirectly proving two key smoothness properties of the models under consideration, we prove that neural networks endowed with KAFs generalize well when trained with SGD for a finite number of steps. Interestingly, our analysis provides a guideline for selecting one of the hyper-parameters of the model, the bandwidth of the scalar Gaussian kernel. A short experimental evaluation validates the proof.