 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Adaptive Visualizations for Critical Decision Making
Nov 14, 2025Effective decision-making often relies on timely insights from complex visual data. While Information Visualization (InfoVis) dashboards can support this process, they rarely adapt to users' cognitive state, and less so in real time. We present Symbiotik, an intelligent, context-aware adaptive visualization system that leverages neurophysiological signals to estimate mental workload (MWL) and dynamically adapt visual dashboards using reinforcement learning (RL). Through a user study with 120 participants and three visualization types, we demonstrate that our approach improves task performance and engagement. Symbiotik offers a scalable, real-time adaptation architecture, and a validated methodology for neuroadaptive user interfaces.
AdSight: Scalable and Accurate Quantification of User Attention in Multi-Slot Sponsored Search
Apr 30, 2025Modern Search Engine Results Pages (SERPs) present complex layouts where multiple elements compete for visibility. Attention modelling is crucial for optimising web design and computational advertising, whereas attention metrics can inform ad placement and revenue strategies. We introduce AdSight, a method leveraging mouse cursor trajectories to quantify in a scalable and accurate manner user attention in multi-slot environments like SERPs. AdSight uses a novel Transformer-based sequence-to-sequence architecture where the encoder processes cursor trajectory embeddings, and the decoder incorporates slot-specific features, enabling robust attention prediction across various SERP layouts. We evaluate our approach on two Machine Learning tasks: (1)~\emph{regression}, to predict fixation times and counts; and (2)~\emph{classification}, to determine some slot types were noticed. Our findings demonstrate the model's ability to predict attention with unprecedented precision, offering actionable insights for researchers and practitioners.
Diffusion Models for Tabular Data Imputation and Synthetic Data Generation
Jul 02, 2024



Data imputation and data generation have important applications for many domains, like healthcare and finance, where incomplete or missing data can hinder accurate analysis and decision-making. Diffusion models have emerged as powerful generative models capable of capturing complex data distributions across various data modalities such as image, audio, and time series data. Recently, they have been also adapted to generate tabular data. In this paper, we propose a diffusion model for tabular data that introduces three key enhancements: (1) a conditioning attention mechanism, (2) an encoder-decoder transformer as the denoising network, and (3) dynamic masking. The conditioning attention mechanism is designed to improve the model's ability to capture the relationship between the condition and synthetic data. The transformer layers help model interactions within the condition (encoder) or synthetic data (decoder), while dynamic masking enables our model to efficiently handle both missing data imputation and synthetic data generation tasks within a unified framework. We conduct a comprehensive evaluation by comparing the performance of diffusion models with transformer conditioning against state-of-the-art techniques, such as Variational Autoencoders, Generative Adversarial Networks and Diffusion Models, on benchmark datasets. Our evaluation focuses on the assessment of the generated samples with respect to three important criteria, namely: (1) Machine Learning efficiency, (2) statistical similarity, and (3) privacy risk mitigation. For the task of data imputation, we consider the efficiency of the generated samples across different levels of missing features.
Graph Neural Network contextual embedding for Deep Learning on Tabular Data
Mar 11, 2023All industries are trying to leverage Artificial Intelligence (AI) based on their existing big data which is available in so called tabular form, where each record is composed of a number of heterogeneous continuous and categorical columns also known as features. Deep Learning (DL) has consituted a major breathrough for AI in fields related to human skills like natural language processing, but its applicability to tabular data has been more challenging. More classical Machine Learning (ML) models like tree-based ensemble ones usually perform better. In this manuscript a novel DL model that uses Graph Neural Network (GNN), more specifically Interaction Network (IN), for contextual embedding is introduced. Its results outperform those of the recently published survey with DL benchmark based on five public datasets, achieving also competitive results when compared to boosted-tree solutions.
Pattern Localization in Time Series through Signal-To-Model Alignment in Latent Space
Feb 19, 2018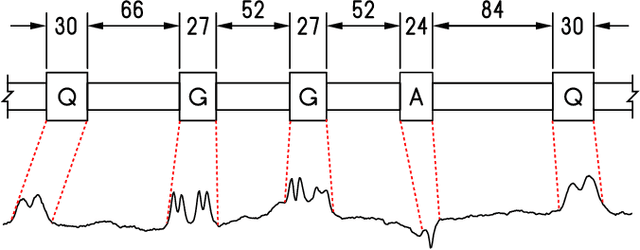
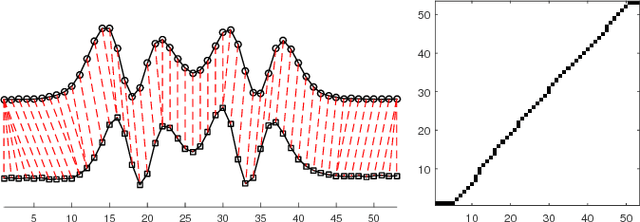

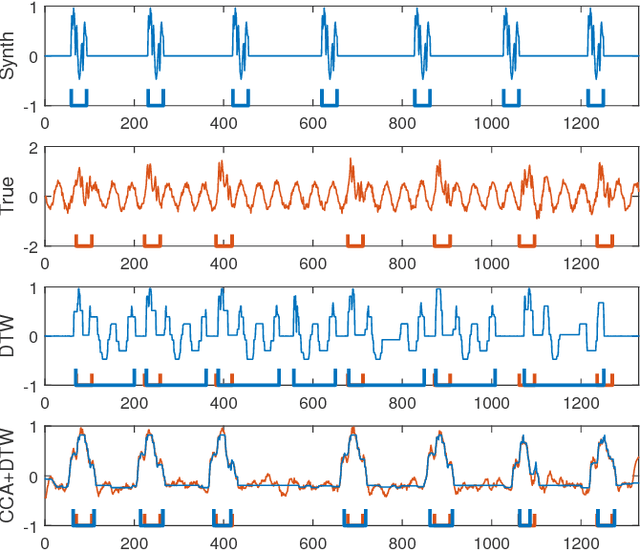
In this paper, we study the problem of locating a predefined sequence of patterns in a time series. In particular, the studied scenario assumes a theoretical model is available that contains the expected locations of the patterns. This problem is found in several contexts, and it is commonly solved by first synthesizing a time series from the model, and then aligning it to the true time series through dynamic time warping. We propose a technique that increases the similarity of both time series before aligning them, by mapping them into a latent correlation space. The mapping is learned from the data through a machine-learning setup. Experiments on data from non-destructive testing demonstrate that the proposed approach shows significant improvements over the state of the art.