Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Transformers With Deep Probabilistic Layers
Paper and Code
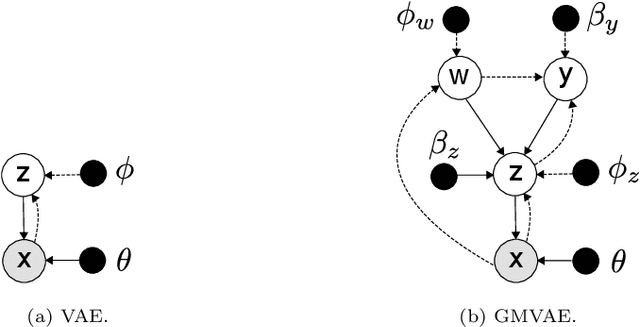
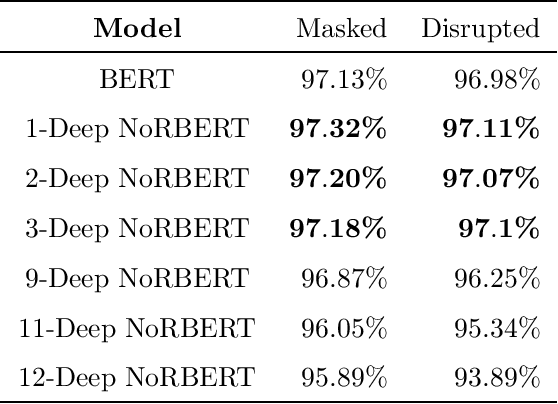
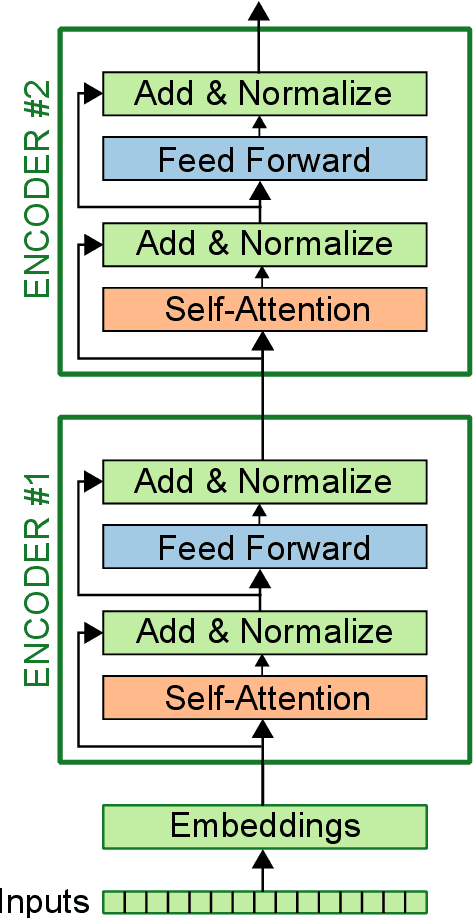
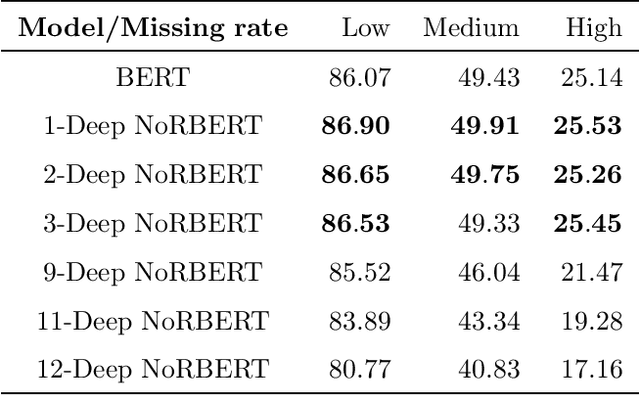
Language models (LM) have grown with non-stop in the last decade, from sequence-to-sequence architectures to the state-of-the-art and utter attention-based Transformers. In this work, we demonstrate how the inclusion of deep generative models within BERT can bring more versatile models, able to impute missing/noisy words with richer text or even improve BLEU score. More precisely, we use a Gaussian Mixture Variational Autoencoder (GMVAE) as a regularizer layer and prove its effectiveness not only in Transformers but also in the most relevant encoder-decoder based LM, seq2seq with and without attention.
View paper on