 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKG-FRUS: a Novel Graph-based Dataset of 127 Years of US Diplomatic Relations
Paper and Code


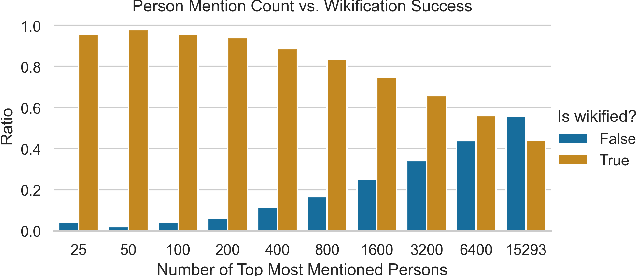

In the current paper, we present the KG-FRUS dataset, comprised of more than 300,000 US government diplomatic documents encoded in a Knowledge Graph (KG). We leverage the data of the Foreign Relations of the United States (FRUS) (available as XML files) to extract information about the documents and the individuals and countries mentioned within them. We use the extracted entities, and associated metadata, to create a graph-based dataset. Further, we supplement the created KG with additional entities and relations from Wikidata. The relations in the KG capture the synergies and dynamics required to study and understand the complex fields of diplomacy, foreign relations, and politics. This goes well beyond a simple collection of documents which neglects the relations between entities in the text. We showcase a range of possibilities of the current dataset by illustrating different approaches to probe the KG. In the paper, we exemplify how to use a query language to answer simple research questions and how to use graph algorithms such as Node2Vec and PageRank, that benefit from the complete graph structure. More importantly, the chosen structure provides total flexibility for continuously expanding and enriching the graph. Our solution is general, so the proposed pipeline for building the KG can encode other original corpora of time-dependent and complex phenomena. Overall, we present a mechanism to create KG databases providing a more versatile representation of time-dependent related text data and a particular application to the all-important FRUS database.