 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretrained Video Models as Differentiable Physics Simulators for Urban Wind Flows
Mar 22, 2026Designing urban spaces that provide pedestrian wind comfort and safety requires time-resolved Computational Fluid Dynamics (CFD) simulations, but their current computational cost makes extensive design exploration impractical. We introduce WinDiNet (Wind Diffusion Network), a pretrained video diffusion model that is repurposed as a fast, differentiable surrogate for this task. Starting from LTX-Video, a 2B-parameter latent video transformer, we fine-tune on 10,000 2D incompressible CFD simulations over procedurally generated building layouts. A systematic study of training regimes, conditioning mechanisms, and VAE adaptation strategies, including a physics-informed decoder loss, identifies a configuration that outperforms purpose-built neural PDE solvers. The resulting model generates full 112-frame rollouts in under a second. As the surrogate is end-to-end differentiable, it doubles as a physics simulator for gradient-based inverse optimization: given an urban footprint layout, we optimize building positions directly through backpropagation to improve wind safety as well as pedestrian wind comfort. Experiments on single- and multi-inlet layouts show that the optimizer discovers effective layouts even under challenging multi-objective configurations, with all improvements confirmed by ground-truth CFD simulations.
HyPINO: Multi-Physics Neural Operators via HyperPINNs and the Method of Manufactured Solutions
Sep 05, 2025We present HyPINO, a multi-physics neural operator designed for zero-shot generalization across a broad class of parametric PDEs without requiring task-specific fine-tuning. Our approach combines a Swin Transformer-based hypernetwork with mixed supervision: (i) labeled data from analytical solutions generated via the Method of Manufactured Solutions (MMS), and (ii) unlabeled samples optimized using physics-informed objectives. The model maps PDE parametrizations to target Physics-Informed Neural Networks (PINNs) and can handle linear elliptic, hyperbolic, and parabolic equations in two dimensions with varying source terms, geometries, and mixed Dirichlet/Neumann boundary conditions, including interior boundaries. HyPINO achieves strong zero-shot accuracy on seven benchmark problems from PINN literature, outperforming U-Nets, Poseidon, and Physics-Informed Neural Operators (PINO). Further, we introduce an iterative refinement procedure that compares the physics of the generated PINN to the requested PDE and uses the discrepancy to generate a "delta" PINN. Summing their contributions and repeating this process forms an ensemble whose combined solution progressively reduces the error on six benchmarks and achieves over 100x gain in average $L_2$ loss in the best case, while retaining forward-only inference. Additionally, we evaluate the fine-tuning behavior of PINNs initialized by HyPINO and show that they converge faster and to lower final error than both randomly initialized and Reptile-meta-learned PINNs on five benchmarks, performing on par on the remaining two. Our results highlight the potential of this scalable approach as a foundation for extending neural operators toward solving increasingly complex, nonlinear, and high-dimensional PDE problems with significantly improved accuracy and reduced computational cost.
Counterfactual Image Generation for adversarially robust and interpretable Classifiers
Oct 01, 2023



Neural Image Classifiers are effective but inherently hard to interpret and susceptible to adversarial attacks. Solutions to both problems exist, among others, in the form of counterfactual examples generation to enhance explainability or adversarially augment training datasets for improved robustness. However, existing methods exclusively address only one of the issues. We propose a unified framework leveraging image-to-image translation Generative Adversarial Networks (GANs) to produce counterfactual samples that highlight salient regions for interpretability and act as adversarial samples to augment the dataset for more robustness. This is achieved by combining the classifier and discriminator into a single model that attributes real images to their respective classes and flags generated images as "fake". We assess the method's effectiveness by evaluating (i) the produced explainability masks on a semantic segmentation task for concrete cracks and (ii) the model's resilience against the Projected Gradient Descent (PGD) attack on a fruit defects detection problem. Our produced saliency maps are highly descriptive, achieving competitive IoU values compared to classical segmentation models despite being trained exclusively on classification labels. Furthermore, the model exhibits improved robustness to adversarial attacks, and we show how the discriminator's "fakeness" value serves as an uncertainty measure of the predictions.
Design Space Exploration and Explanation via Conditional Variational Autoencoders in Meta-model-based Conceptual Design of Pedestrian Bridges
Nov 29, 2022For conceptual design, engineers rely on conventional iterative (often manual) techniques. Emerging parametric models facilitate design space exploration based on quantifiable performance metrics, yet remain time-consuming and computationally expensive. Pure optimisation methods, however, ignore qualitative aspects (e.g. aesthetics or construction methods). This paper provides a performance-driven design exploration framework to augment the human designer through a Conditional Variational Autoencoder (CVAE), which serves as forward performance predictor for given design features as well as an inverse design feature predictor conditioned on a set of performance requests. The CVAE is trained on 18'000 synthetically generated instances of a pedestrian bridge in Switzerland. Sensitivity analysis is employed for explainability and informing designers about (i) relations of the model between features and/or performances and (ii) structural improvements under user-defined objectives. A case study proved our framework's potential to serve as a future co-pilot for conceptual design studies of pedestrian bridges and beyond.
Automated Quality Control of Vacuum Insulated Glazing by Convolutional Neural Network Image Classification
Oct 15, 2021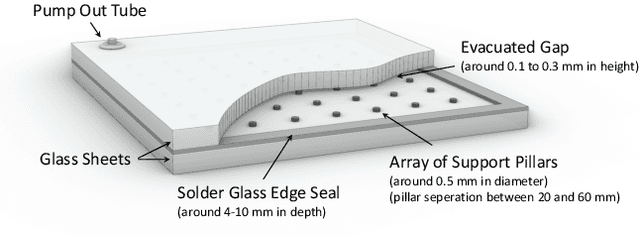


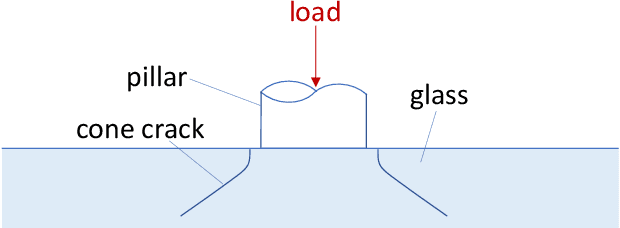
Vacuum Insulated Glazing (VIG) is a highly thermally insulating window technology, which boasts an extremely thin profile and lower weight as compared to gas-filled insulated glazing units of equivalent performance. The VIG is a double-pane configuration with a submillimeter vacuum gap between the panes and therefore under constant atmospheric pressure over their service life. Small pillars are positioned between the panes to maintain the gap, which can damage the glass reducing the lifetime of the VIG unit. To efficiently assess any surface damage on the glass, an automated damage detection system is highly desirable. For the purpose of classifying the damage, we have developed, trained, and tested a deep learning computer vision system using convolutional neural networks. The classification model flawlessly classified the test dataset with an area under the curve (AUC) for the receiver operating characteristic (ROC) of 100%. We have automatically cropped the images down to their relevant information by using Faster-RCNN to locate the position of the pillars. We employ the state-of-the-art methods Grad-CAM and Score-CAM of explainable Artificial Intelligence (XAI) to provide an understanding of the internal mechanisms and were able to show that our classifier outperforms ResNet50V2 for identification of crack locations and geometry. The proposed methods can therefore be used to detect systematic defects even without large amounts of training data. Further analyses of our model's predictive capabilities demonstrates its superiority over state-of-the-art models (ResNet50V2, ResNet101V2 and ResNet152V2) in terms of convergence speed, accuracy, precision at 100% recall and AUC for ROC.