 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Role Labeling: A Systematical Survey
Feb 09, 2025Semantic role labeling (SRL) is a central natural language processing (NLP) task aiming to understand the semantic roles within texts, facilitating a wide range of downstream applications. While SRL has garnered extensive and enduring research, there is currently a lack of a comprehensive survey that thoroughly organizes and synthesizes the field. This paper aims to review the entire research trajectory of the SRL community over the past two decades. We begin by providing a complete definition of SRL. To offer a comprehensive taxonomy, we categorize SRL methodologies into four key perspectives: model architectures, syntax feature modeling, application scenarios, and multi-modal extensions. Further, we discuss SRL benchmarks, evaluation metrics, and paradigm modeling approaches, while also exploring practical applications across various domains. Finally, we analyze future research directions in SRL, addressing the evolving role of SRL in the age of large language models (LLMs) and its potential impact on the broader NLP landscape. We maintain a public repository and consistently update related resources at: https://github.com/DreamH1gh/Awesome-SRL
Dynamic Token Reduction during Generation for Vision Language Models
Jan 24, 2025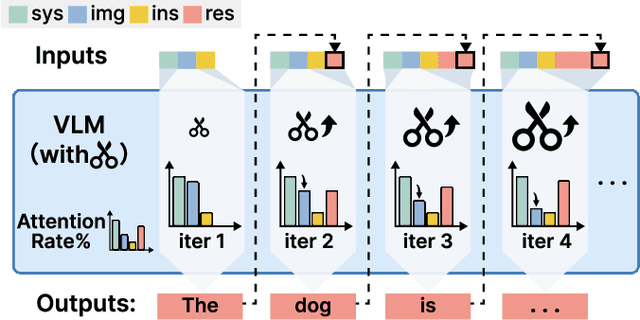
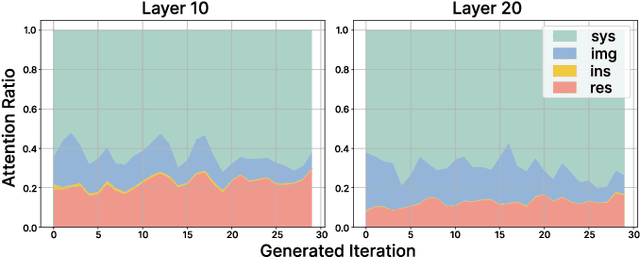
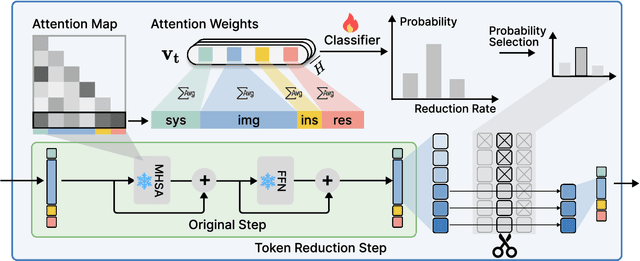

Vision-Language Models (VLMs) have achieved notable success in multimodal tasks but face practical limitations due to the quadratic complexity of decoder attention mechanisms and autoregressive generation. Existing methods like FASTV and VTW have achieved notable results in reducing redundant visual tokens, but these approaches focus on pruning tokens in a single forward pass without systematically analyzing the redundancy of visual tokens throughout the entire generation process. In this paper, we introduce a dynamic pruning strategy tailored for VLMs, namedDynamic Rate (DyRate), which progressively adjusts the compression rate during generation. Our analysis of the distribution of attention reveals that the importance of visual tokens decreases throughout the generation process, inspiring us to adopt a more aggressive compression rate. By integrating a lightweight predictor based on attention distribution, our approach enables flexible adjustment of pruning rates based on the attention distribution. Our experimental results demonstrate that our method not only reduces computational demands but also maintains the quality of responses.
LLM-Driven Multimodal Opinion Expression Identification
Jun 26, 2024



Opinion Expression Identification (OEI) is essential in NLP for applications ranging from voice assistants to depression diagnosis. This study extends OEI to encompass multimodal inputs, underlining the significance of auditory cues in delivering emotional subtleties beyond the capabilities of text. We introduce a novel multimodal OEI (MOEI) task, integrating text and speech to mirror real-world scenarios. Utilizing CMU MOSEI and IEMOCAP datasets, we construct the CI-MOEI dataset. Additionally, Text-to-Speech (TTS) technology is applied to the MPQA dataset to obtain the CIM-OEI dataset. We design a template for the OEI task to take full advantage of the generative power of large language models (LLMs). Advancing further, we propose an LLM-driven method STOEI, which combines speech and text modal to identify opinion expressions. Our experiments demonstrate that MOEI significantly improves the performance while our method outperforms existing methods by 9.20\% and obtains SOTA results.
Retrieval-style In-Context Learning for Few-shot Hierarchical Text Classification
Jun 25, 2024Hierarchical text classification (HTC) is an important task with broad applications, while few-shot HTC has gained increasing interest recently. While in-context learning (ICL) with large language models (LLMs) has achieved significant success in few-shot learning, it is not as effective for HTC because of the expansive hierarchical label sets and extremely-ambiguous labels. In this work, we introduce the first ICL-based framework with LLM for few-shot HTC. We exploit a retrieval database to identify relevant demonstrations, and an iterative policy to manage multi-layer hierarchical labels. Particularly, we equip the retrieval database with HTC label-aware representations for the input texts, which is achieved by continual training on a pretrained language model with masked language modeling (MLM), layer-wise classification (CLS, specifically for HTC), and a novel divergent contrastive learning (DCL, mainly for adjacent semantically-similar labels) objective. Experimental results on three benchmark datasets demonstrate superior performance of our method, and we can achieve state-of-the-art results in few-shot HTC.