 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning Based Few-Shot Graph-Level Anomaly Detection
Oct 09, 2025Graph-level anomaly detection aims to identify anomalous graphs or subgraphs within graph datasets, playing a vital role in various fields such as fraud detection, review classification, and biochemistry. While Graph Neural Networks (GNNs) have made significant progress in this domain, existing methods rely heavily on large amounts of labeled data, which is often unavailable in real-world scenarios. Additionally, few-shot anomaly detection methods based on GNNs are prone to noise interference, resulting in poor embedding quality and reduced model robustness. To address these challenges, we propose a novel meta-learning-based graph-level anomaly detection framework (MA-GAD), incorporating a graph compression module that reduces the graph size, mitigating noise interference while retaining essential node information. We also leverage meta-learning to extract meta-anomaly information from similar networks, enabling the learning of an initialization model that can rapidly adapt to new tasks with limited samples. This improves the anomaly detection performance on target graphs, and a bias network is used to enhance the distinction between anomalous and normal nodes. Our experimental results, based on four real-world biochemical datasets, demonstrate that MA-GAD outperforms existing state-of-the-art methods in graph-level anomaly detection under few-shot conditions. Experiments on both graph anomaly and subgraph anomaly detection tasks validate the framework's effectiveness on real-world datasets.
Addressing Graph Anomaly Detection via Causal Edge Separation and Spectrum
Aug 20, 2025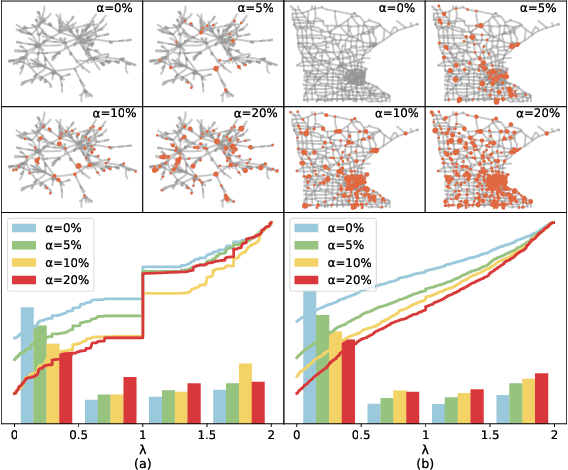
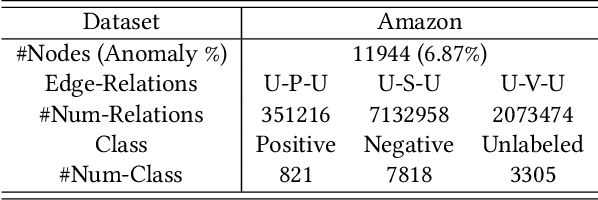
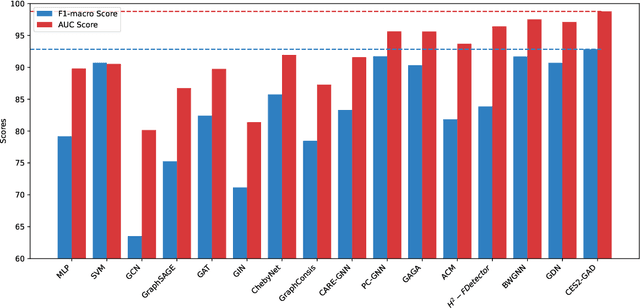
In the real world, anomalous entities often add more legitimate connections while hiding direct links with other anomalous entities, leading to heterophilic structures in anomalous networks that most GNN-based techniques fail to address. Several works have been proposed to tackle this issue in the spatial domain. However, these methods overlook the complex relationships between node structure encoding, node features, and their contextual environment and rely on principled guidance, research on solving spectral domain heterophilic problems remains limited. This study analyzes the spectral distribution of nodes with different heterophilic degrees and discovers that the heterophily of anomalous nodes causes the spectral energy to shift from low to high frequencies. To address the above challenges, we propose a spectral neural network CES2-GAD based on causal edge separation for anomaly detection on heterophilic graphs. Firstly, CES2-GAD will separate the original graph into homophilic and heterophilic edges using causal interventions. Subsequently, various hybrid-spectrum filters are used to capture signals from the segmented graphs. Finally, representations from multiple signals are concatenated and input into a classifier to predict anomalies. Extensive experiments with real-world datasets have proven the effectiveness of the method we proposed.
LLM-Driven Multimodal Opinion Expression Identification
Jun 26, 2024



Opinion Expression Identification (OEI) is essential in NLP for applications ranging from voice assistants to depression diagnosis. This study extends OEI to encompass multimodal inputs, underlining the significance of auditory cues in delivering emotional subtleties beyond the capabilities of text. We introduce a novel multimodal OEI (MOEI) task, integrating text and speech to mirror real-world scenarios. Utilizing CMU MOSEI and IEMOCAP datasets, we construct the CI-MOEI dataset. Additionally, Text-to-Speech (TTS) technology is applied to the MPQA dataset to obtain the CIM-OEI dataset. We design a template for the OEI task to take full advantage of the generative power of large language models (LLMs). Advancing further, we propose an LLM-driven method STOEI, which combines speech and text modal to identify opinion expressions. Our experiments demonstrate that MOEI significantly improves the performance while our method outperforms existing methods by 9.20\% and obtains SOTA results.
Domain-Specific NER via Retrieving Correlated Samples
Aug 27, 2022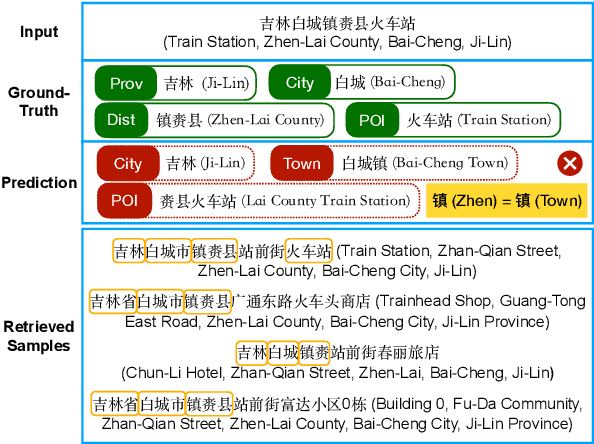


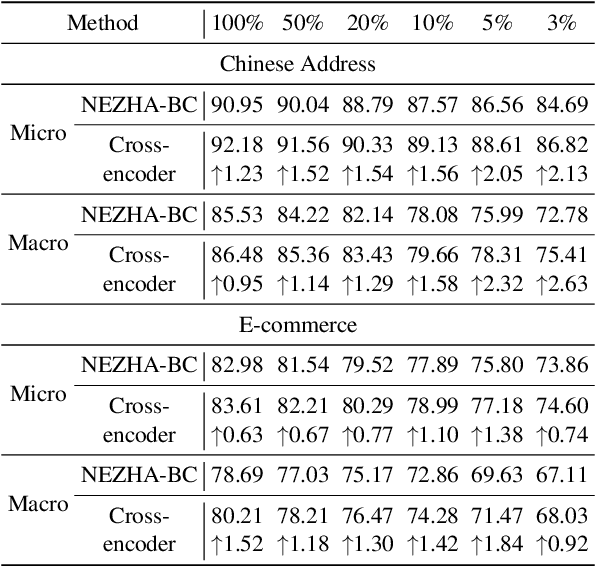
Successful Machine Learning based Named Entity Recognition models could fail on texts from some special domains, for instance, Chinese addresses and e-commerce titles, where requires adequate background knowledge. Such texts are also difficult for human annotators. In fact, we can obtain some potentially helpful information from correlated texts, which have some common entities, to help the text understanding. Then, one can easily reason out the correct answer by referencing correlated samples. In this paper, we suggest enhancing NER models with correlated samples. We draw correlated samples by the sparse BM25 retriever from large-scale in-domain unlabeled data. To explicitly simulate the human reasoning process, we perform a training-free entity type calibrating by majority voting. To capture correlation features in the training stage, we suggest to model correlated samples by the transformer-based multi-instance cross-encoder. Empirical results on datasets of the above two domains show the efficacy of our methods.
Identifying Chinese Opinion Expressions with Extremely-Noisy Crowdsourcing Annotations
Apr 22, 2022

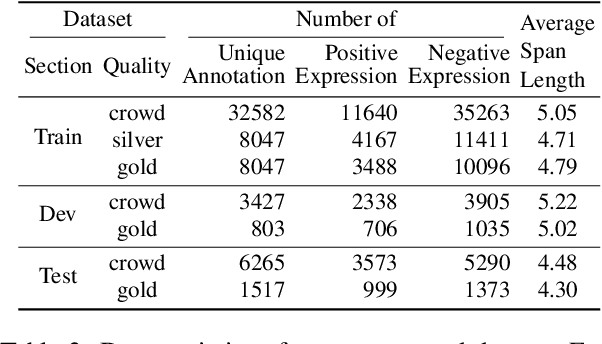
Recent works of opinion expression identification (OEI) rely heavily on the quality and scale of the manually-constructed training corpus, which could be extremely difficult to satisfy. Crowdsourcing is one practical solution for this problem, aiming to create a large-scale but quality-unguaranteed corpus. In this work, we investigate Chinese OEI with extremely-noisy crowdsourcing annotations, constructing a dataset at a very low cost. Following zhang et al. (2021), we train the annotator-adapter model by regarding all annotations as gold-standard in terms of crowd annotators, and test the model by using a synthetic expert, which is a mixture of all annotators. As this annotator-mixture for testing is never modeled explicitly in the training phase, we propose to generate synthetic training samples by a pertinent mixup strategy to make the training and testing highly consistent. The simulation experiments on our constructed dataset show that crowdsourcing is highly promising for OEI, and our proposed annotator-mixup can further enhance the crowdsourcing modeling.
A Graph-Based Neural Model for End-to-End Frame Semantic Parsing
Sep 25, 2021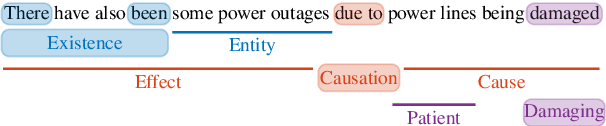
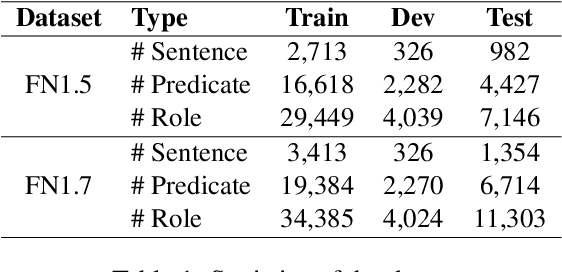
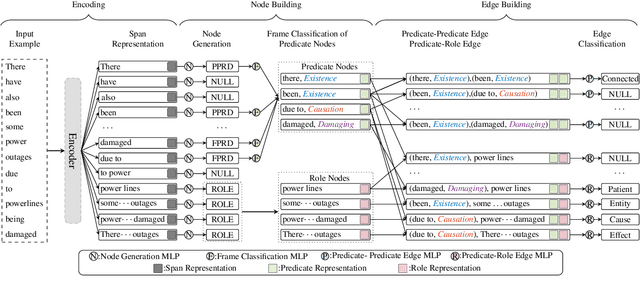
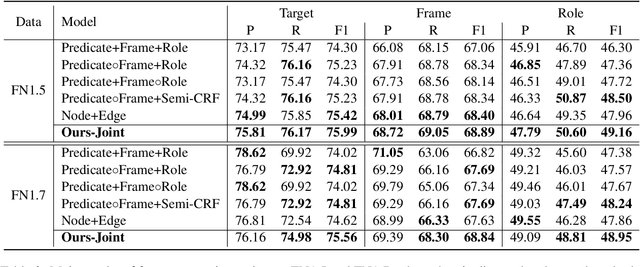
Frame semantic parsing is a semantic analysis task based on FrameNet which has received great attention recently. The task usually involves three subtasks sequentially: (1) target identification, (2) frame classification and (3) semantic role labeling. The three subtasks are closely related while previous studies model them individually, which ignores their intern connections and meanwhile induces error propagation problem. In this work, we propose an end-to-end neural model to tackle the task jointly. Concretely, we exploit a graph-based method, regarding frame semantic parsing as a graph construction problem. All predicates and roles are treated as graph nodes, and their relations are taken as graph edges. Experiment results on two benchmark datasets of frame semantic parsing show that our method is highly competitive, resulting in better performance than pipeline models.
Crowdsourcing Learning as Domain Adaptation: A Case Study on Named Entity Recognition
May 31, 2021

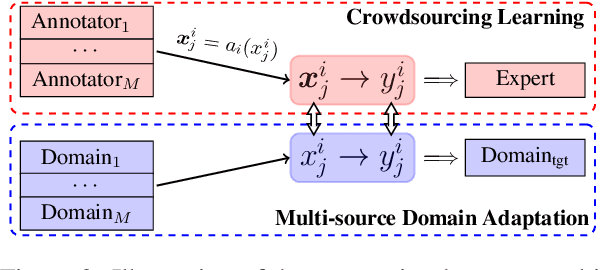

Crowdsourcing is regarded as one prospective solution for effective supervised learning, aiming to build large-scale annotated training data by crowd workers. Previous studies focus on reducing the influences from the noises of the crowdsourced annotations for supervised models. We take a different point in this work, regarding all crowdsourced annotations as gold-standard with respect to the individual annotators. In this way, we find that crowdsourcing could be highly similar to domain adaptation, and then the recent advances of cross-domain methods can be almost directly applied to crowdsourcing. Here we take named entity recognition (NER) as a study case, suggesting an annotator-aware representation learning model that inspired by the domain adaptation methods which attempt to capture effective domain-aware features. We investigate both unsupervised and supervised crowdsourcing learning, assuming that no or only small-scale expert annotations are available. Experimental results on a benchmark crowdsourced NER dataset show that our method is highly effective, leading to a new state-of-the-art performance. In addition, under the supervised setting, we can achieve impressive performance gains with only a very small scale of expert annotations.