 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSMF: Cascaded Selective Mask Fine-Tuning for Multi-Objective Embedding-Based Retrieval
Apr 17, 2025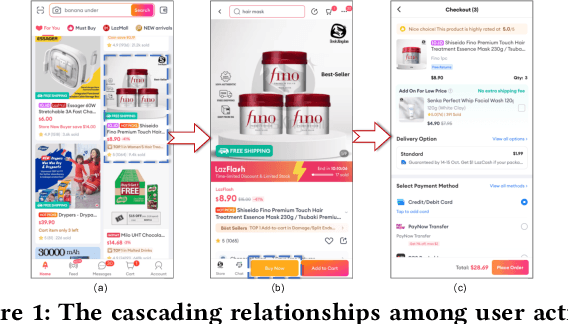
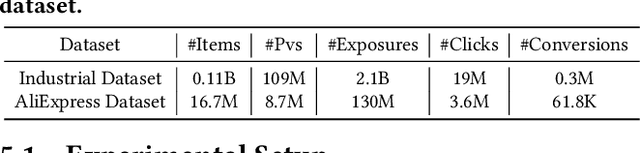
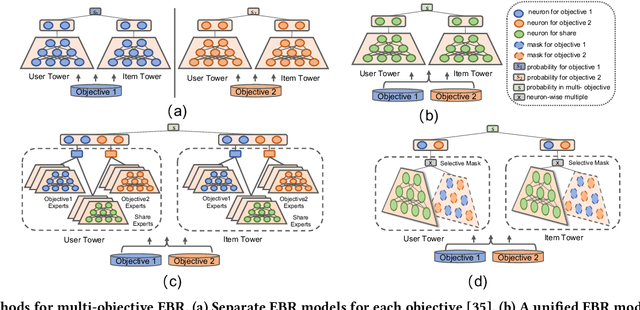
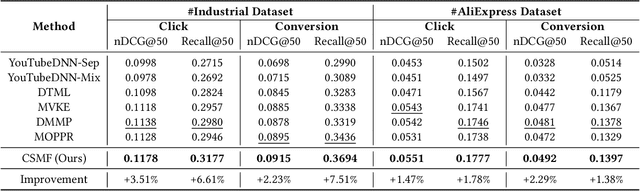
Multi-objective embedding-based retrieval (EBR) has become increasingly critical due to the growing complexity of user behaviors and commercial objectives. While traditional approaches often suffer from data sparsity and limited information sharing between objectives, recent methods utilizing a shared network alongside dedicated sub-networks for each objective partially address these limitations. However, such methods significantly increase the model parameters, leading to an increased retrieval latency and a limited ability to model causal relationships between objectives. To address these challenges, we propose the Cascaded Selective Mask Fine-Tuning (CSMF), a novel method that enhances both retrieval efficiency and serving performance for multi-objective EBR. The CSMF framework selectively masks model parameters to free up independent learning space for each objective, leveraging the cascading relationships between objectives during the sequential fine-tuning. Without increasing network parameters or online retrieval overhead, CSMF computes a linearly weighted fusion score for multiple objective probabilities while supporting flexible adjustment of each objective's weight across various recommendation scenarios. Experimental results on real-world datasets demonstrate the superior performance of CSMF, and online experiments validate its significant practical value.
Addressing Information Loss and Interaction Collapse: A Dual Enhanced Attention Framework for Feature Interaction
Mar 14, 2025The Transformer has proven to be a significant approach in feature interaction for CTR prediction, achieving considerable success in previous works. However, it also presents potential challenges in handling feature interactions. Firstly, Transformers may encounter information loss when capturing feature interactions. By relying on inner products to represent pairwise relationships, they compress raw interaction information, which can result in a degradation of fidelity. Secondly, due to the long-tail features distribution, feature fields with low information-abundance embeddings constrain the information abundance of other fields, leading to collapsed embedding matrices. To tackle these issues, we propose a Dual Attention Framework for Enhanced Feature Interaction, known as Dual Enhanced Attention. This framework integrates two attention mechanisms: the Combo-ID attention mechanism and the collapse-avoiding attention mechanism. The Combo-ID attention mechanism directly retains feature interaction pairs to mitigate information loss, while the collapse-avoiding attention mechanism adaptively filters out low information-abundance interaction pairs to prevent interaction collapse. Extensive experiments conducted on industrial datasets have shown the effectiveness of Dual Enhanced Attention.
Hierarchical Causal Transformer with Heterogeneous Information for Expandable Sequential Recommendation
Mar 04, 2025



Sequential recommendation systems leveraging transformer architectures have demonstrated exceptional capabilities in capturing user behavior patterns. At the core of these systems lies the critical challenge of constructing effective item representations. Traditional approaches employ feature fusion through simple concatenation or basic neural architectures to create uniform representation sequences. However, these conventional methods fail to address the intrinsic diversity of item attributes, thereby constraining the transformer's capacity to discern fine-grained patterns and hindering model extensibility. Although recent research has begun incorporating user-related heterogeneous features into item sequences, the equally crucial item-side heterogeneous feature continue to be neglected. To bridge this methodological gap, we present HeterRec - an innovative framework featuring two novel components: the Heterogeneous Token Flattening Layer (HTFL) and Hierarchical Causal Transformer (HCT). HTFL pioneers a sophisticated tokenization mechanism that decomposes items into multi-dimensional token sets and structures them into heterogeneous sequences, enabling scalable performance enhancement through model expansion. The HCT architecture further enhances pattern discovery through token-level and item-level attention mechanisms. furthermore, we develop a Listwise Multi-step Prediction (LMP) objective function to optimize learning process. Rigorous validation, including real-world industrial platforms, confirms HeterRec's state-of-the-art performance in both effective and efficiency.
Efficient Long Sequential Low-rank Adaptive Attention for Click-through rate Prediction
Mar 04, 2025In the context of burgeoning user historical behavior data, Accurate click-through rate(CTR) prediction requires effective modeling of lengthy user behavior sequences. As the volume of such data keeps swelling, the focus of research has shifted towards developing effective long-term behavior modeling methods to capture latent user interests. Nevertheless, the complexity introduced by large scale data brings about computational hurdles. There is a pressing need to strike a balance between achieving high model performance and meeting the strict response time requirements of online services. While existing retrieval-based methods (e.g., similarity filtering or attention approximation) achieve practical runtime efficiency, they inherently compromise information fidelity through aggressive sequence truncation or attention sparsification. This paper presents a novel attention mechanism. It overcomes the shortcomings of existing methods while ensuring computational efficiency. This mechanism learn compressed representation of sequence with length $L$ via low-rank projection matrices (rank $r \ll L$), reducing attention complexity from $O(L)$ to $O(r)$. It also integrates a uniquely designed loss function to preserve nonlinearity of attention. In the inference stage, the mechanism adopts matrix absorption and prestorage strategies. These strategies enable it to effectively satisfy online constraints. Comprehensive offline and online experiments demonstrate that the proposed method outperforms current state-of-the-art solutions.
Modeling User Viewing Flow using Large Language Models for Article Recommendation
Nov 12, 2023



This paper proposes the User Viewing Flow Modeling (SINGLE) method for the article recommendation task, which models the user constant preference and instant interest from user-clicked articles. Specifically, we employ a user constant viewing flow modeling method to summarize the user's general interest to recommend articles. We utilize Large Language Models (LLMs) to capture constant user preferences from previously clicked articles, such as skills and positions. Then we design the user instant viewing flow modeling method to build interactions between user-clicked article history and candidate articles. It attentively reads the representations of user-clicked articles and aims to learn the user's different interest views to match the candidate article. Our experimental results on the Alibaba Technology Association (ATA) website show the advantage of SINGLE, which achieves 2.4% improvements over previous baseline models in the online A/B test. Our further analyses illustrate that SINGLE has the ability to build a more tailored recommendation system by mimicking different article viewing behaviors of users and recommending more appropriate and diverse articles to match user interests.
Cold-Start based Multi-Scenario Ranking Model for Click-Through Rate Prediction
Apr 16, 2023Online travel platforms (OTPs), e.g., Ctrip.com or Fliggy.com, can effectively provide travel-related products or services to users. In this paper, we focus on the multi-scenario click-through rate (CTR) prediction, i.e., training a unified model to serve all scenarios. Existing multi-scenario based CTR methods struggle in the context of OTP setting due to the ignorance of the cold-start users who have very limited data. To fill this gap, we propose a novel method named Cold-Start based Multi-scenario Network (CSMN). Specifically, it consists of two basic components including: 1) User Interest Projection Network (UIPN), which firstly purifies users' behaviors by eliminating the scenario-irrelevant information in behaviors with respect to the visiting scenario, followed by obtaining users' scenario-specific interests by summarizing the purified behaviors with respect to the target item via an attention mechanism; and 2) User Representation Memory Network (URMN), which benefits cold-start users from users with rich behaviors through a memory read and write mechanism. CSMN seamlessly integrates both components in an end-to-end learning framework. Extensive experiments on real-world offline dataset and online A/B test demonstrate the superiority of CSMN over state-of-the-art methods.
Hierarchically Fusing Long and Short-Term User Interests for Click-Through Rate Prediction in Product Search
Apr 04, 2023Estimating Click-Through Rate (CTR) is a vital yet challenging task in personalized product search. However, existing CTR methods still struggle in the product search settings due to the following three challenges including how to more effectively extract users' short-term interests with respect to multiple aspects, how to extract and fuse users' long-term interest with short-term interests, how to address the entangling characteristic of long and short-term interests. To resolve these challenges, in this paper, we propose a new approach named Hierarchical Interests Fusing Network (HIFN), which consists of four basic modules namely Short-term Interests Extractor (SIE), Long-term Interests Extractor (LIE), Interests Fusion Module (IFM) and Interests Disentanglement Module (IDM). Specifically, SIE is proposed to extract user's short-term interests by integrating three fundamental interests encoders within it namely query-dependent, target-dependent and causal-dependent interest encoder, respectively, followed by delivering the resultant representation to the module LIE, where it can effectively capture user long-term interests by devising an attention mechanism with respect to the short-term interests from SIE module. In IFM, the achieved long and short-term interests are further fused in an adaptive manner, followed by concatenating it with original raw context features for the final prediction result. Last but not least, considering the entangling characteristic of long and short-term interests, IDM further devises a self-supervised framework to disentangle long and short-term interests. Extensive offline and online evaluations on a real-world e-commerce platform demonstrate the superiority of HIFN over state-of-the-art methods.
Re-weighting Negative Samples for Model-Agnostic Matching
Jul 06, 2022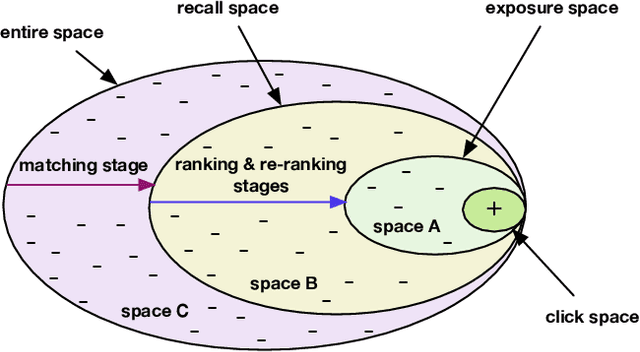
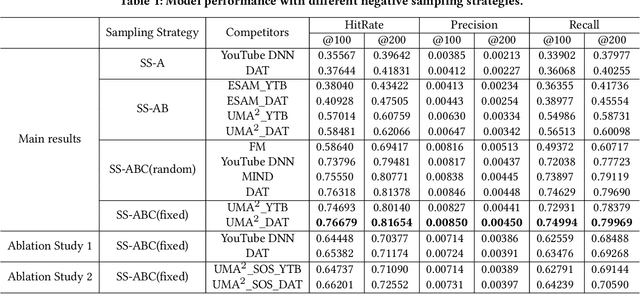
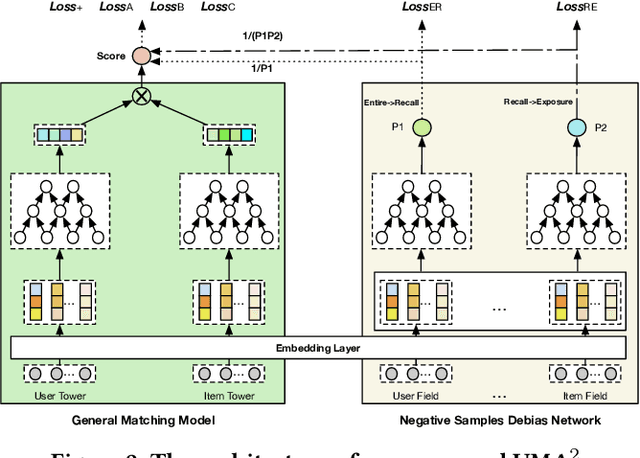
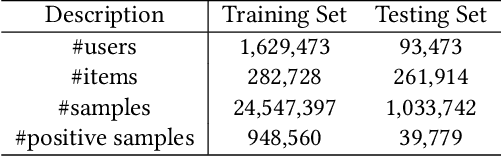
Recommender Systems (RS), as an efficient tool to discover users' interested items from a very large corpus, has attracted more and more attention from academia and industry. As the initial stage of RS, large-scale matching is fundamental yet challenging. A typical recipe is to learn user and item representations with a two-tower architecture and then calculate the similarity score between both representation vectors, which however still struggles in how to properly deal with negative samples. In this paper, we find that the common practice that randomly sampling negative samples from the entire space and treating them equally is not an optimal choice, since the negative samples from different sub-spaces at different stages have different importance to a matching model. To address this issue, we propose a novel method named Unbiased Model-Agnostic Matching Approach (UMA$^2$). It consists of two basic modules including 1) General Matching Model (GMM), which is model-agnostic and can be implemented as any embedding-based two-tower models; and 2) Negative Samples Debias Network (NSDN), which discriminates negative samples by borrowing the idea of Inverse Propensity Weighting (IPW) and re-weighs the loss in GMM. UMA$^2$ seamlessly integrates these two modules in an end-to-end multi-task learning framework. Extensive experiments on both real-world offline dataset and online A/B test demonstrate its superiority over state-of-the-art methods.
Conversion Rate Prediction via Meta Learning in Small-Scale Recommendation Scenarios
Dec 27, 2021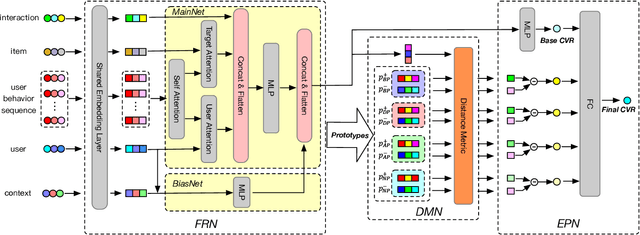
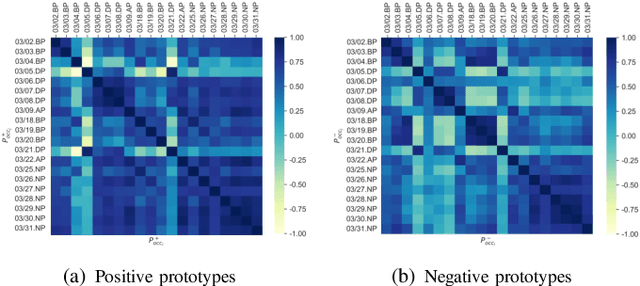
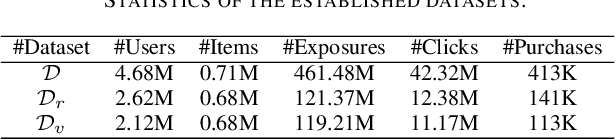
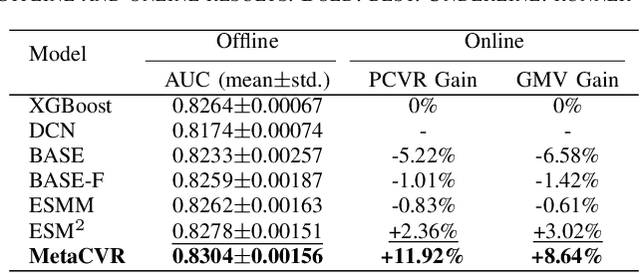
Different from large-scale platforms such as Taobao and Amazon, developing CVR models in small-scale recommendation scenarios is more challenging due to the severe Data Distribution Fluctuation (DDF) issue. DDF prevents existing CVR models from being effective since 1) several months of data are needed to train CVR models sufficiently in small scenarios, leading to considerable distribution discrepancy between training and online serving; and 2) e-commerce promotions have much more significant impacts on small scenarios, leading to distribution uncertainty of the upcoming time period. In this work, we propose a novel CVR method named MetaCVR from a perspective of meta learning to address the DDF issue. Firstly, a base CVR model which consists of a Feature Representation Network (FRN) and output layers is elaborately designed and trained sufficiently with samples across months. Then we treat time periods with different data distributions as different occasions and obtain positive and negative prototypes for each occasion using the corresponding samples and the pre-trained FRN. Subsequently, a Distance Metric Network (DMN) is devised to calculate the distance metrics between each sample and all prototypes to facilitate mitigating the distribution uncertainty. At last, we develop an Ensemble Prediction Network (EPN) which incorporates the output of FRN and DMN to make the final CVR prediction. In this stage, we freeze the FRN and train the DMN and EPN with samples from recent time period, therefore effectively easing the distribution discrepancy. To the best of our knowledge, this is the first study of CVR prediction targeting the DDF issue in small-scale recommendation scenarios. Experimental results on real-world datasets validate the superiority of our MetaCVR and online A/B test also shows our model achieves impressive gains of 11.92% on PCVR and 8.64% on GMV.
SAME: Scenario Adaptive Mixture-of-Experts for Promotion-Aware Click-Through Rate Prediction
Dec 27, 2021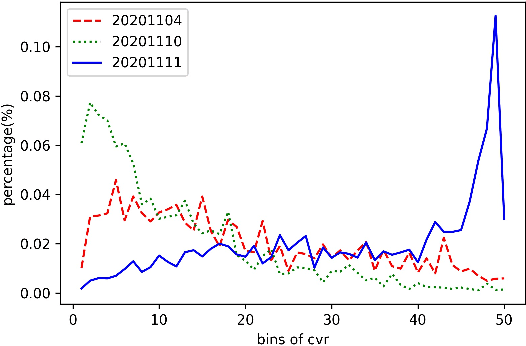
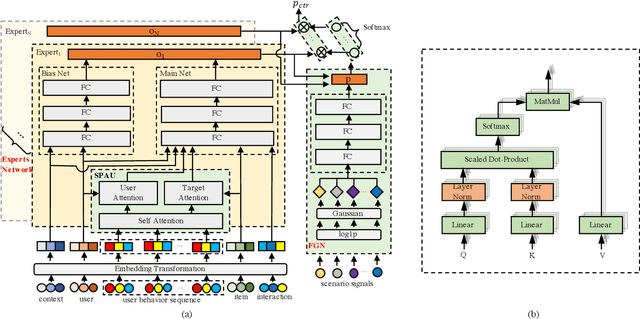
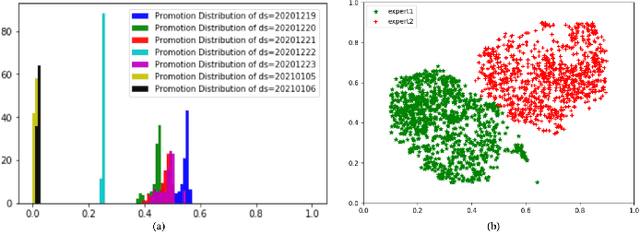
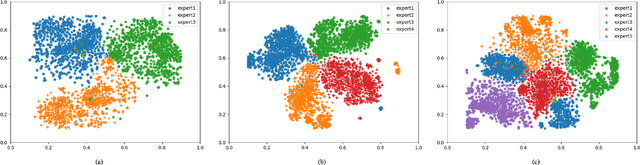
Promotions are becoming more important and prevalent in e-commerce platforms to attract customers and boost sales. However, Click-Through Rate (CTR) prediction methods in recommender systems are not able to handle such circumstances well since: 1) they can't generalize well to serving because the online data distribution is uncertain due to the potentially upcoming promotions; 2) without paying enough attention to scenario signals, they are incapable of learning different feature representation patterns which coexist in each scenario. In this work, we propose Scenario Adaptive Mixture-of-Experts (SAME), a simple yet effective model that serves both promotion and normal scenarios. Technically, it follows the idea of Mixture-of-Experts by adopting multiple experts to learn feature representations, which are modulated by a Feature Gated Network (FGN) via an attention mechanism. To obtain high-quality representations, we design a Stacked Parallel Attention Unit (SPAU) to help each expert better handle user behavior sequence. To tackle the distribution uncertainty, a set of scenario signals are elaborately devised from a perspective of time series prediction and fed into the FGN, whose output is concatenated with feature representation from each expert to learn the attention. Accordingly, a mixture of the feature representations is obtained scenario-adaptively and used for the final CTR prediction. In this way, each expert can learn a discriminative representation pattern. To the best of our knowledge, this is the first study for promotion-aware CTR prediction. Experimental results on real-world datasets validate the superiority of SAME. Online A/B test also shows SAME achieves significant gains of 3.58% on CTR and 5.94% on IPV during promotion periods as well as 3.93% and 6.57% in normal days, respectively.