 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Fine-Tuning in Large Models: A Survey of Methodologies
Oct 24, 2024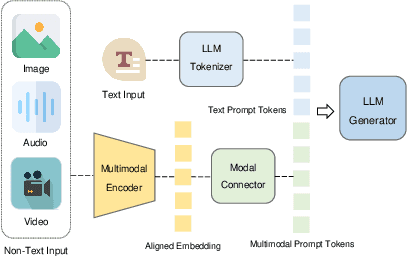
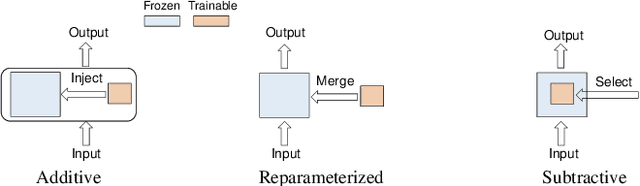
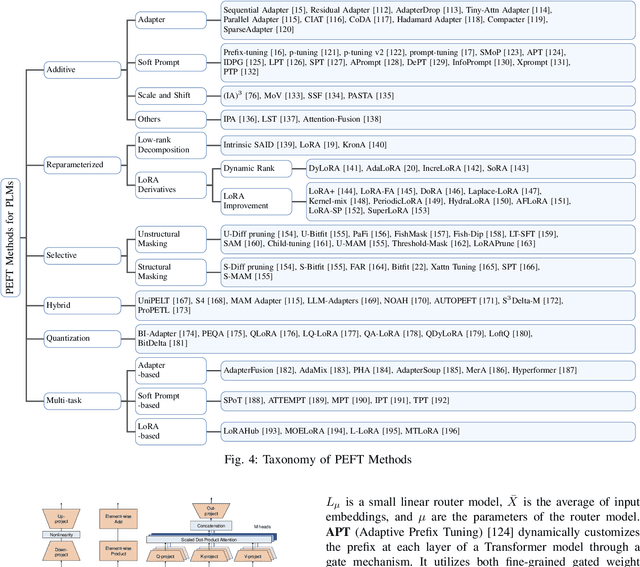
The large models, as predicted by scaling raw forecasts, have made groundbreaking progress in many fields, particularly in natural language generation tasks, where they have approached or even surpassed human levels. However, the unprecedented scale of their parameters brings significant computational and storage costs. These large models require substantial computational resources and GPU memory to operate. When adapting large models to specific downstream tasks, their massive parameter scale poses a significant challenge in fine-tuning on hardware platforms with limited computational power and GPU memory. To address this issue, Parameter-Efficient Fine-Tuning (PEFT) offers a practical solution by efficiently adjusting the parameters of large pre-trained models to suit various downstream tasks. Specifically, PEFT adjusts the parameters of pre-trained large models to adapt to specific tasks or domains, minimizing the introduction of additional parameters and the computational resources required. This review mainly introduces the preliminary knowledge of PEFT, the core ideas and principles of various PEFT algorithms, the applications of PEFT, and potential future research directions. By reading this review, we believe that interested parties can quickly grasp the PEFT methodology, thereby accelerating its development and innovation.
GT-Rain Single Image Deraining Challenge Report
Mar 18, 2024


This report reviews the results of the GT-Rain challenge on single image deraining at the UG2+ workshop at CVPR 2023. The aim of this competition is to study the rainy weather phenomenon in real world scenarios, provide a novel real world rainy image dataset, and to spark innovative ideas that will further the development of single image deraining methods on real images. Submissions were trained on the GT-Rain dataset and evaluated on an extension of the dataset consisting of 15 additional scenes. Scenes in GT-Rain are comprised of real rainy image and ground truth image captured moments after the rain had stopped. 275 participants were registered in the challenge and 55 competed in the final testing phase.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
A Boosted Model Ensembling Approach to Ball Action Spotting in Videos: The Runner-Up Solution to CVPR'23 SoccerNet Challenge
Jun 12, 2023


This technical report presents our solution to Ball Action Spotting in videos. Our method reached second place in the CVPR'23 SoccerNet Challenge. Details of this challenge can be found at https://www.soccer-net.org/tasks/ball-action-spotting. Our approach is developed based on a baseline model termed E2E-Spot, which was provided by the organizer of this competition. We first generated several variants of the E2E-Spot model, resulting in a candidate model set. We then proposed a strategy for selecting appropriate model members from this set and assigning an appropriate weight to each model. The aim of this strategy is to boost the performance of the resulting model ensemble. Therefore, we call our approach Boosted Model Ensembling (BME). Our code is available at https://github.com/ZJLAB-AMMI/E2E-Spot-MBS.
Restormer-Plus for Real World Image Deraining: the Runner-up Solution to the GT-RAIN Challenge
May 26, 2023



This technical report presents our Restormer-Plus approach, which was submitted to the GT-RAIN Challenge (CVPR 2023 UG$^2$+ Track 3). Details regarding the challenge are available at http://cvpr2023.ug2challenge.org/track3.html. Restormer-Plus outperformed all other submitted solutions in terms of peak signal-to-noise ratio (PSNR), and ranked 4th in terms of structural similarity (SSIM). It was officially evaluated by the competition organizers as a runner-up solution. It consists of four main modules: the single-image de-raining module (Restormer-X), the median filtering module, the weighted averaging module, and the post-processing module. Restormer-X is applied to each rainy image and built on top of Restormer. The median filtering module is used as a median operator for rainy images associated with each scene. The weighted averaging module combines the median filtering results with those of Restormer-X to alleviate overfitting caused by using only Restormer-X. Finally, the post-processing module is utilized to improve the brightness restoration. These modules make Restormer-Plus one of the state-of-the-art solutions for the GT-RAIN Challenge. Our code can be found at https://github.com/ZJLAB-AMMI/Restormer-Plus.
Use the Detection Transformer as a Data Augmenter
Apr 26, 2023



Detection Transformer (DETR) is a Transformer architecture based object detection model. In this paper, we demonstrate that it can also be used as a data augmenter. We term our approach as DETR assisted CutMix, or DeMix for short. DeMix builds on CutMix, a simple yet highly effective data augmentation technique that has gained popularity in recent years. CutMix improves model performance by cutting and pasting a patch from one image onto another, yielding a new image. The corresponding label for this new example is specified as the weighted average of the original labels, where the weight is proportional to the area of the patch. CutMix selects a random patch to be cut. In contrast, DeMix elaborately selects a semantically rich patch, located by a pre-trained DETR. The label of the new image is specified in the same way as in CutMix. Experimental results on benchmark datasets for image classification demonstrate that DeMix significantly outperforms prior art data augmentation methods including CutMix. Oue code is available at https://github.com/ZJLAB-AMMI/DeMix.
Conversion Rate Prediction via Meta Learning in Small-Scale Recommendation Scenarios
Dec 27, 2021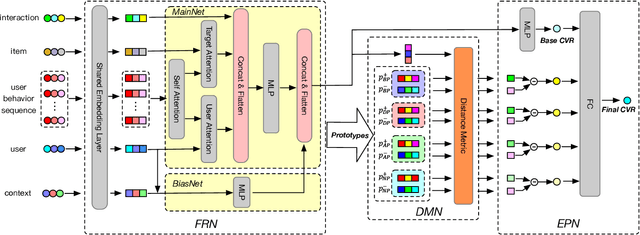
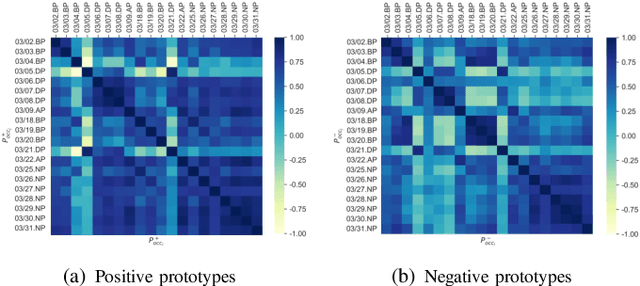
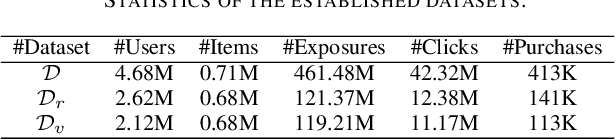
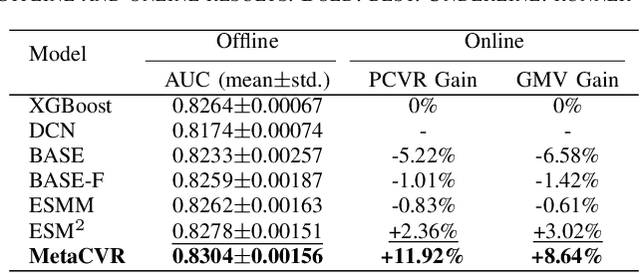
Different from large-scale platforms such as Taobao and Amazon, developing CVR models in small-scale recommendation scenarios is more challenging due to the severe Data Distribution Fluctuation (DDF) issue. DDF prevents existing CVR models from being effective since 1) several months of data are needed to train CVR models sufficiently in small scenarios, leading to considerable distribution discrepancy between training and online serving; and 2) e-commerce promotions have much more significant impacts on small scenarios, leading to distribution uncertainty of the upcoming time period. In this work, we propose a novel CVR method named MetaCVR from a perspective of meta learning to address the DDF issue. Firstly, a base CVR model which consists of a Feature Representation Network (FRN) and output layers is elaborately designed and trained sufficiently with samples across months. Then we treat time periods with different data distributions as different occasions and obtain positive and negative prototypes for each occasion using the corresponding samples and the pre-trained FRN. Subsequently, a Distance Metric Network (DMN) is devised to calculate the distance metrics between each sample and all prototypes to facilitate mitigating the distribution uncertainty. At last, we develop an Ensemble Prediction Network (EPN) which incorporates the output of FRN and DMN to make the final CVR prediction. In this stage, we freeze the FRN and train the DMN and EPN with samples from recent time period, therefore effectively easing the distribution discrepancy. To the best of our knowledge, this is the first study of CVR prediction targeting the DDF issue in small-scale recommendation scenarios. Experimental results on real-world datasets validate the superiority of our MetaCVR and online A/B test also shows our model achieves impressive gains of 11.92% on PCVR and 8.64% on GMV.