 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORE-Acu: Structured Reasoning Traces and Knowledge Graph Safety Verification for Acupuncture Clinical Decision Support
Mar 09, 2026Large language models (LLMs) show significant potential for clinical decision support (CDS), yet their black-box nature -- characterized by untraceable reasoning and probabilistic hallucinations -- poses severe challenges in acupuncture, a field demanding rigorous interpretability and safety. To address this, we propose CORE-Acu, a neuro-symbolic framework for acupuncture clinical decision support that integrates Structured Chain-of-Thought (S-CoT) with knowledge graph (KG) safety verification. First, we construct the first acupuncture Structured Reasoning Trace dataset and a schema-constrained fine-tuning framework. By enforcing an explicit causal chain from pattern identification to treatment principles, treatment plans, and acupoint selection, we transform implicit Traditional Chinese Medicine (TCM) reasoning into interpretable generation constraints, mitigating the opacity of LLM-based CDS. Furthermore, we construct a TCM safety knowledge graph and establish a ``Generate--Verify--Revise'' closed-loop inference system based on a Symbolic Veto Mechanism, employing deterministic rules to intercept hallucinations and enforce hard safety boundaries. Finally, we introduce the Lexicon-Matched Entity-Reweighted Loss (LMERL), which corrects terminology drift caused by the frequency--importance mismatch in general optimization by adaptively amplifying gradient contributions of high-risk entities during fine-tuning. Experiments on 1,000 held-out cases demonstrate CORE-Acu's superior entity fidelity and reasoning quality. Crucially, CORE-Acu achieved 0/1,000 observed safety violations (95\% CI: 0--0.37\%), whereas GPT-4o exhibited an 8.5\% violation rate under identical rules. These results establish CORE-Acu as a robust neuro-symbolic framework for acupuncture clinical decision support, guaranteeing both reasoning auditability and strict safety compliance.
GT-Rain Single Image Deraining Challenge Report
Mar 18, 2024


This report reviews the results of the GT-Rain challenge on single image deraining at the UG2+ workshop at CVPR 2023. The aim of this competition is to study the rainy weather phenomenon in real world scenarios, provide a novel real world rainy image dataset, and to spark innovative ideas that will further the development of single image deraining methods on real images. Submissions were trained on the GT-Rain dataset and evaluated on an extension of the dataset consisting of 15 additional scenes. Scenes in GT-Rain are comprised of real rainy image and ground truth image captured moments after the rain had stopped. 275 participants were registered in the challenge and 55 competed in the final testing phase.
From Sky to the Ground: A Large-scale Benchmark and Simple Baseline Towards Real Rain Removal
Aug 18, 2023Learning-based image deraining methods have made great progress. However, the lack of large-scale high-quality paired training samples is the main bottleneck to hamper the real image deraining (RID). To address this dilemma and advance RID, we construct a Large-scale High-quality Paired real rain benchmark (LHP-Rain), including 3000 video sequences with 1 million high-resolution (1920*1080) frame pairs. The advantages of the proposed dataset over the existing ones are three-fold: rain with higher-diversity and larger-scale, image with higher-resolution and higher-quality ground-truth. Specifically, the real rains in LHP-Rain not only contain the classical rain streak/veiling/occlusion in the sky, but also the \textbf{splashing on the ground} overlooked by deraining community. Moreover, we propose a novel robust low-rank tensor recovery model to generate the GT with better separating the static background from the dynamic rain. In addition, we design a simple transformer-based single image deraining baseline, which simultaneously utilize the self-attention and cross-layer attention within the image and rain layer with discriminative feature representation. Extensive experiments verify the superiority of the proposed dataset and deraining method over state-of-the-art.
Mutual Query Network for Multi-Modal Product Image Segmentation
Jun 26, 2023



Product image segmentation is vital in e-commerce. Most existing methods extract the product image foreground only based on the visual modality, making it difficult to distinguish irrelevant products. As product titles contain abundant appearance information and provide complementary cues for product image segmentation, we propose a mutual query network to segment products based on both visual and linguistic modalities. First, we design a language query vision module to obtain the response of language description in image areas, thus aligning the visual and linguistic representations across modalities. Then, a vision query language module utilizes the correlation between visual and linguistic modalities to filter the product title and effectively suppress the content irrelevant to the vision in the title. To promote the research in this field, we also construct a Multi-Modal Product Segmentation dataset (MMPS), which contains 30,000 images and corresponding titles. The proposed method significantly outperforms the state-of-the-art methods on MMPS.
A Two-Stage Real Image Deraining Method for GT-RAIN Challenge CVPR 2023 Workshop UG$^{\textbf{2}}$+ Track 3
May 13, 2023



In this technical report, we briefly introduce the solution of our team HUST\li VIE for GT-Rain Challenge in CVPR 2023 UG$^{2}$+ Track 3. In this task, we propose an efficient two-stage framework to reconstruct a clear image from rainy frames. Firstly, a low-rank based video deraining method is utilized to generate pseudo GT, which fully takes the advantage of multi and aligned rainy frames. Secondly, a transformer-based single image deraining network Uformer is implemented to pre-train on large real rain dataset and then fine-tuned on pseudo GT to further improve image restoration. Moreover, in terms of visual pleasing effect, a comprehensive image processor module is utilized at the end of pipeline. Our overall framework is elaborately designed and able to handle both heavy rainy and foggy sequences provided in the final testing phase. Finally, we rank 1st on the average structural similarity (SSIM) and rank 2nd on the average peak signal-to-noise ratio (PSNR). Our code is available at https://github.com/yunguo224/UG2_Deraining.
Unsupervised Deraining: Where Asymmetric Contrastive Learning Meets Self-similarity
Nov 02, 2022
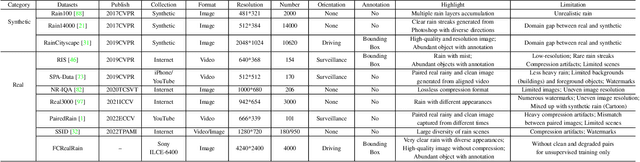

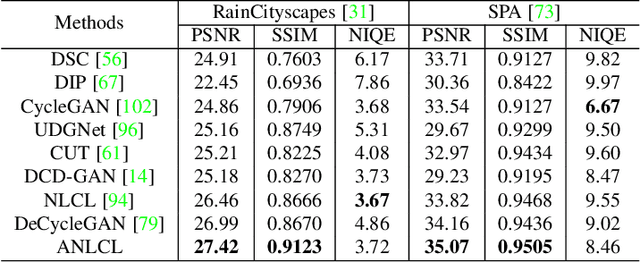
Most of the existing learning-based deraining methods are supervisedly trained on synthetic rainy-clean pairs. The domain gap between the synthetic and real rain makes them less generalized to complex real rainy scenes. Moreover, the existing methods mainly utilize the property of the image or rain layers independently, while few of them have considered their mutually exclusive relationship. To solve above dilemma, we explore the intrinsic intra-similarity within each layer and inter-exclusiveness between two layers and propose an unsupervised non-local contrastive learning (NLCL) deraining method. The non-local self-similarity image patches as the positives are tightly pulled together, rain patches as the negatives are remarkably pushed away, and vice versa. On one hand, the intrinsic self-similarity knowledge within positive/negative samples of each layer benefits us to discover more compact representation; on the other hand, the mutually exclusive property between the two layers enriches the discriminative decomposition. Thus, the internal self-similarity within each layer (similarity) and the external exclusive relationship of the two layers (dissimilarity) serving as a generic image prior jointly facilitate us to unsupervisedly differentiate the rain from clean image. We further discover that the intrinsic dimension of the non-local image patches is generally higher than that of the rain patches. This motivates us to design an asymmetric contrastive loss to precisely model the compactness discrepancy of the two layers for better discriminative decomposition. In addition, considering that the existing real rain datasets are of low quality, either small scale or downloaded from the internet, we collect a real large-scale dataset under various rainy kinds of weather that contains high-resolution rainy images.