 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLA-Trace: Diagnosing Vision-Language-Action Models through Representation and Behavior Tracing
May 28, 2026Understanding how Vision-Language-Action (VLA) models transform multimodal knowledge into embodied control remains an open challenge. We present VLA-Trace, a progressive diagnostic framework that analyzes VLA models through a unified evidence chain from representation dynamics to causal control attribution and behavioral manifestation. It specifically combines cross-modal and checkpoint-drift centered kernel alignment (CKA) to trace representation evolution, attention knockout interventions to identify modality-specific control pathways, and rollout-level behavioral probes to examine grounding, shortcut dependence, and semantic following. Experiments on $π_{0.5}$ and OpenVLA reveal three key findings. First, the two models exhibit distinct modality-specific adaptation dynamics during VLA finetuning. Second, they rely on different multimodal routing strategies and layer-wise dependencies during action decoding. Third, although VLA policies excel at visually grounded trajectory generation, they remain limited in fine-grained semantic following. These findings highlight future directions for representation-preserving adaptation, causal VLA circuits, and compositional semantic control.
Robo-Cortex: A Self-Evolving Embodied Agent via Dual-Grain Cognitive Memory and Autonomous Knowledge Induction
May 18, 2026The ability to navigate and interact with complex environments is central to real-world embodied agents, yet navigation in unseen environments remains challenging due to "experiential amnesia," where existing trajectory-driven or reactive policies fail to synthesize generalizable strategies from past interactions. We propose Robo-Cortex, a self-evolving framework that enables robots to autonomously induce navigation heuristics and refine cognitive strategies through a continuous reflection-adaptation loop. By abstracting success patterns and failure pitfalls into natural-language heuristics, Robo-Cortex enables a transition from passive execution to active strategy evolution. Our core innovation is an Autonomous Knowledge Induction (AKI) mechanism that distills multimodal trajectories into a structured Navigation Heuristic Library for knowledge generalization. The architecture further incorporates a Dual-Grain Cognitive Memory system, comprising a Short-term Reflective Memory (SRM) for real-time local progress analysis, and a Long-term Principle Memory (LPM) that abstracts past trajectories into reusable guiding and cautionary principles. To ensure robust decision-making, we introduce a multimodal Imagine-then-Verify loop, where a world model simulates potential outcomes and a VLM-based evaluator validates action plans. Extensive evaluations on IGNav, AR, and AEQA show that Robo-Cortex consistently outperforms strong baselines in both task success and exploration efficiency, with gains of up to +4.16% SPL over the strongest prior method and up to +15.30% SPL under heuristic transfer to unseen environments. Preliminary real-world robotic experiments further support the effectiveness of Robo-Cortex in physical settings.
Pelican-Unified 1.0: A Unified Embodied Intelligence Model for Understanding, Reasoning, Imagination and Action
May 14, 2026We present Pelican-Unified 1.0, the first embodied foundation model trained according to the principle of unification. Pelican-Unified 1.0 uses a single VLM as a unified understanding module, mapping scenes, instructions, visual contexts, and action histories into a shared semantic space. The same VLM also serves as a unified reasoning module, autoregressively producing task-, action-, and future-oriented chains of thought in a single forward pass and projecting the final hidden state into a dense latent variable. A Unified Future Generator (UFG) then conditions on this latent variable and jointly generates future videos and future actions through two modality-specific output heads within the same denoising process. The language, video, and action losses are all backpropagated into the shared representation, enabling the model to jointly optimize understanding, reasoning, imagination, and action during training, rather than training three isolated expert systems. Experiments demonstrate that unification does not imply compromise. With a single checkpoint, Pelican-Unified 1.0 achieves strong performance across all three capabilities: 64.7 on eight VLM benchmarks, the best among comparable-scale models; 66.03 on WorldArena, ranking first; and 93.5 on RoboTwin, the second-best average among compared action methods. These results show that the unified paradigm succeeds in preserving specialist strength while bringing understanding, reasoning, imagination, and action into one model.
Mutual Query Network for Multi-Modal Product Image Segmentation
Jun 26, 2023



Product image segmentation is vital in e-commerce. Most existing methods extract the product image foreground only based on the visual modality, making it difficult to distinguish irrelevant products. As product titles contain abundant appearance information and provide complementary cues for product image segmentation, we propose a mutual query network to segment products based on both visual and linguistic modalities. First, we design a language query vision module to obtain the response of language description in image areas, thus aligning the visual and linguistic representations across modalities. Then, a vision query language module utilizes the correlation between visual and linguistic modalities to filter the product title and effectively suppress the content irrelevant to the vision in the title. To promote the research in this field, we also construct a Multi-Modal Product Segmentation dataset (MMPS), which contains 30,000 images and corresponding titles. The proposed method significantly outperforms the state-of-the-art methods on MMPS.
Adversarial Training Based Multi-Source Unsupervised Domain Adaptation for Sentiment Analysis
Jun 10, 2020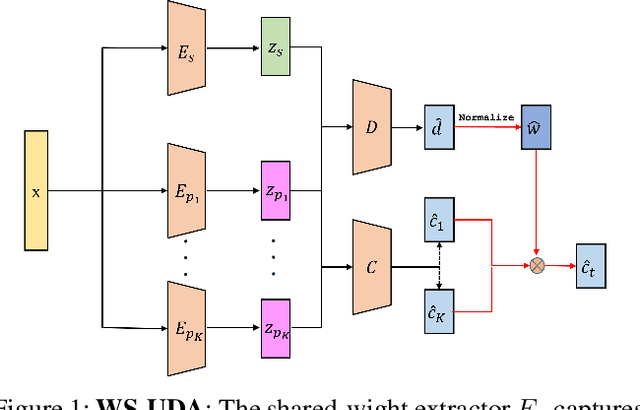
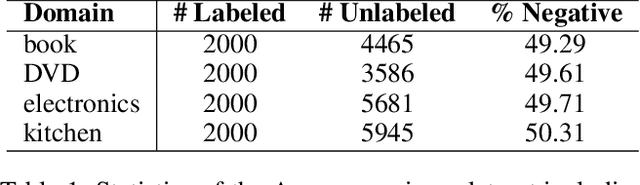

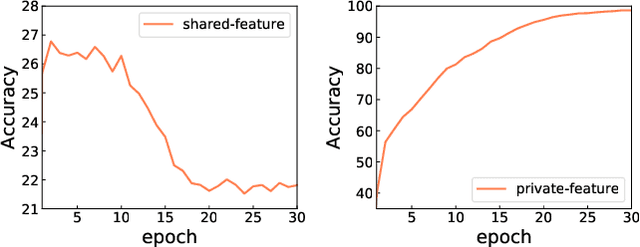
Multi-source unsupervised domain adaptation (MS-UDA) for sentiment analysis (SA) aims to leverage useful information in multiple source domains to help do SA in an unlabeled target domain that has no supervised information. Existing algorithms of MS-UDA either only exploit the shared features, i.e., the domain-invariant information, or based on some weak assumption in NLP, e.g., smoothness assumption. To avoid these problems, we propose two transfer learning frameworks based on the multi-source domain adaptation methodology for SA by combining the source hypotheses to derive a good target hypothesis. The key feature of the first framework is a novel Weighting Scheme based Unsupervised Domain Adaptation framework (WS-UDA), which combine the source classifiers to acquire pseudo labels for target instances directly. While the second framework is a Two-Stage Training based Unsupervised Domain Adaptation framework (2ST-UDA), which further exploits these pseudo labels to train a target private extractor. Importantly, the weights assigned to each source classifier are based on the relations between target instances and source domains, which measured by a discriminator through the adversarial training. Furthermore, through the same discriminator, we also fulfill the separation of shared features and private features. Experimental results on two SA datasets demonstrate the promising performance of our frameworks, which outperforms unsupervised state-of-the-art competitors.