 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCA3D: Monocular 3D Bounding Box Prediction in the Image Plane
Mar 20, 2026Monocular 3D object understanding has largely been cast as a 2D RoI-to-3D box lifting problem. However, emerging downstream applications require image-plane geometry (e.g., projected 3D box corners) which cannot be easily obtained without known intrinsics, a problem for object detection in the wild. We introduce MoCA3D, a Monocular, Class-Agnostic 3D model that predicts projected 3D bounding box corners and per-corner depths without requiring camera intrinsics at inference time. MoCA3D formulates pixel-space localization and depth assignment as dense prediction via corner heatmaps and depth maps. To evaluate image-plane geometric fidelity, we propose Pixel-Aligned Geometry (PAG), which directly measures image-plane corner and depth consistency. Extensive experiments demonstrate that MoCA3D achieves state-of-the-art performance, improving image-plane corner PAG by 22.8% while remaining comparable on 3D IoU, using up to 57 times fewer trainable parameters. Finally, we apply MoCA3D to downstream tasks which were previously impractical under unknown intrinsics, highlighting its utility beyond standard baseline models.
WorldBench: Disambiguating Physics for Diagnostic Evaluation of World Models
Jan 29, 2026Recent advances in generative foundational models, often termed "world models," have propelled interest in applying them to critical tasks like robotic planning and autonomous system training. For reliable deployment, these models must exhibit high physical fidelity, accurately simulating real-world dynamics. Existing physics-based video benchmarks, however, suffer from entanglement, where a single test simultaneously evaluates multiple physical laws and concepts, fundamentally limiting their diagnostic capability. We introduce WorldBench, a novel video-based benchmark specifically designed for concept-specific, disentangled evaluation, allowing us to rigorously isolate and assess understanding of a single physical concept or law at a time. To make WorldBench comprehensive, we design benchmarks at two different levels: 1) an evaluation of intuitive physical understanding with concepts such as object permanence or scale/perspective, and 2) an evaluation of low-level physical constants and material properties such as friction coefficients or fluid viscosity. When SOTA video-based world models are evaluated on WorldBench, we find specific patterns of failure in particular physics concepts, with all tested models lacking the physical consistency required to generate reliable real-world interactions. Through its concept-specific evaluation, WorldBench offers a more nuanced and scalable framework for rigorously evaluating the physical reasoning capabilities of video generation and world models, paving the way for more robust and generalizable world-model-driven learning.
All-day Depth Completion
May 27, 2024



We propose a method for depth estimation under different illumination conditions, i.e., day and night time. As photometry is uninformative in regions under low-illumination, we tackle the problem through a multi-sensor fusion approach, where we take as input an additional synchronized sparse point cloud (i.e., from a LiDAR) projected onto the image plane as a sparse depth map, along with a camera image. The crux of our method lies in the use of the abundantly available synthetic data to first approximate the 3D scene structure by learning a mapping from sparse to (coarse) dense depth maps along with their predictive uncertainty - we term this, SpaDe. In poorly illuminated regions where photometric intensities do not afford the inference of local shape, the coarse approximation of scene depth serves as a prior; the uncertainty map is then used with the image to guide refinement through an uncertainty-driven residual learning (URL) scheme. The resulting depth completion network leverages complementary strengths from both modalities - depth is sparse but insensitive to illumination and in metric scale, and image is dense but sensitive with scale ambiguity. SpaDe can be used in a plug-and-play fashion, which allows for 25% improvement when augmented onto existing methods to preprocess sparse depth. We demonstrate URL on the nuScenes dataset where we improve over all baselines by an average 11.65% in all-day scenarios, 11.23% when tested specifically for daytime, and 13.12% for nighttime scenes.
WeatherProof: Leveraging Language Guidance for Semantic Segmentation in Adverse Weather
Mar 21, 2024
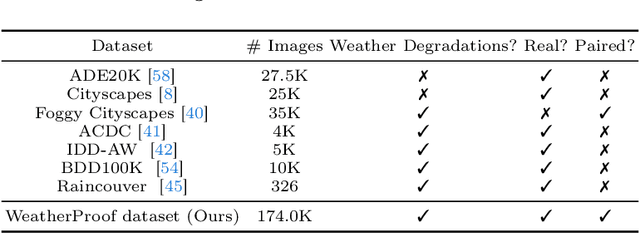


We propose a method to infer semantic segmentation maps from images captured under adverse weather conditions. We begin by examining existing models on images degraded by weather conditions such as rain, fog, or snow, and found that they exhibit a large performance drop as compared to those captured under clear weather. To control for changes in scene structures, we propose WeatherProof, the first semantic segmentation dataset with accurate clear and adverse weather image pairs that share an underlying scene. Through this dataset, we analyze the error modes in existing models and found that they were sensitive to the highly complex combination of different weather effects induced on the image during capture. To improve robustness, we propose a way to use language as guidance by identifying contributions of adverse weather conditions and injecting that as "side information". Models trained using our language guidance exhibit performance gains by up to 10.2% in mIoU on WeatherProof, up to 8.44% in mIoU on the widely used ACDC dataset compared to standard training techniques, and up to 6.21% in mIoU on the ACDC dataset as compared to previous SOTA methods.
GT-Rain Single Image Deraining Challenge Report
Mar 18, 2024


This report reviews the results of the GT-Rain challenge on single image deraining at the UG2+ workshop at CVPR 2023. The aim of this competition is to study the rainy weather phenomenon in real world scenarios, provide a novel real world rainy image dataset, and to spark innovative ideas that will further the development of single image deraining methods on real images. Submissions were trained on the GT-Rain dataset and evaluated on an extension of the dataset consisting of 15 additional scenes. Scenes in GT-Rain are comprised of real rainy image and ground truth image captured moments after the rain had stopped. 275 participants were registered in the challenge and 55 competed in the final testing phase.
WeatherProof: A Paired-Dataset Approach to Semantic Segmentation in Adverse Weather
Dec 15, 2023



The introduction of large, foundational models to computer vision has led to drastically improved performance on the task of semantic segmentation. However, these existing methods exhibit a large performance drop when testing on images degraded by weather conditions such as rain, fog, or snow. We introduce a general paired-training method that can be applied to all current foundational model architectures that leads to improved performance on images in adverse weather conditions. To this end, we create the WeatherProof Dataset, the first semantic segmentation dataset with accurate clear and adverse weather image pairs, which not only enables our new training paradigm, but also improves the evaluation of the performance gap between clear and degraded segmentation. We find that training on these paired clear and adverse weather frames which share an underlying scene results in improved performance on adverse weather data. With this knowledge, we propose a training pipeline which accentuates the advantages of paired-data training using consistency losses and language guidance, which leads to performance improvements by up to 18.4% as compared to standard training procedures.
Enhancing Diffusion Models with 3D Perspective Geometry Constraints
Dec 01, 2023



While perspective is a well-studied topic in art, it is generally taken for granted in images. However, for the recent wave of high-quality image synthesis methods such as latent diffusion models, perspective accuracy is not an explicit requirement. Since these methods are capable of outputting a wide gamut of possible images, it is difficult for these synthesized images to adhere to the principles of linear perspective. We introduce a novel geometric constraint in the training process of generative models to enforce perspective accuracy. We show that outputs of models trained with this constraint both appear more realistic and improve performance of downstream models trained on generated images. Subjective human trials show that images generated with latent diffusion models trained with our constraint are preferred over images from the Stable Diffusion V2 model 70% of the time. SOTA monocular depth estimation models such as DPT and PixelFormer, fine-tuned on our images, outperform the original models trained on real images by up to 7.03% in RMSE and 19.3% in SqRel on the KITTI test set for zero-shot transfer.
SparseGS: Real-Time 360° Sparse View Synthesis using Gaussian Splatting
Nov 30, 2023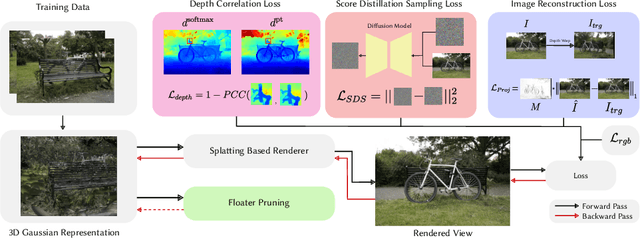

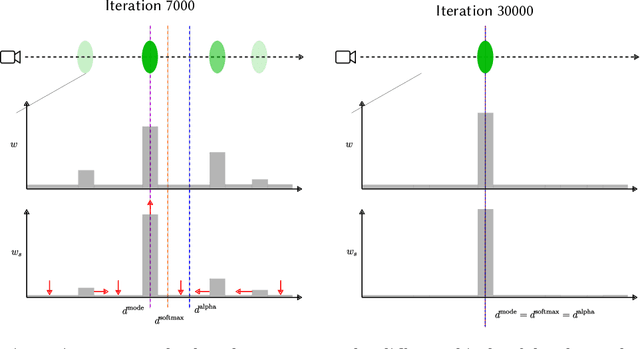

The problem of novel view synthesis has grown significantly in popularity recently with the introduction of Neural Radiance Fields (NeRFs) and other implicit scene representation methods. A recent advance, 3D Gaussian Splatting (3DGS), leverages an explicit representation to achieve real-time rendering with high-quality results. However, 3DGS still requires an abundance of training views to generate a coherent scene representation. In few shot settings, similar to NeRF, 3DGS tends to overfit to training views, causing background collapse and excessive floaters, especially as the number of training views are reduced. We propose a method to enable training coherent 3DGS-based radiance fields of 360 scenes from sparse training views. We find that using naive depth priors is not sufficient and integrate depth priors with generative and explicit constraints to reduce background collapse, remove floaters, and enhance consistency from unseen viewpoints. Experiments show that our method outperforms base 3DGS by up to 30.5% and NeRF-based methods by up to 15.6% in LPIPS on the MipNeRF-360 dataset with substantially less training and inference cost.