 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseGS: Real-Time 360° Sparse View Synthesis using Gaussian Splatting
Paper and Code
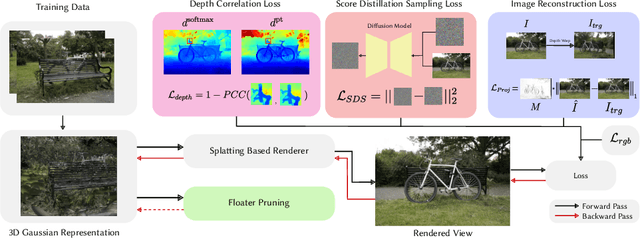

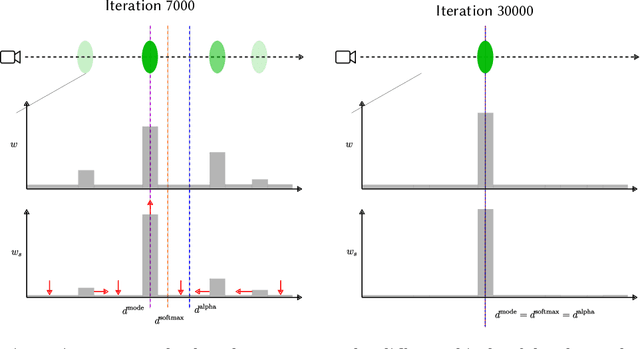

The problem of novel view synthesis has grown significantly in popularity recently with the introduction of Neural Radiance Fields (NeRFs) and other implicit scene representation methods. A recent advance, 3D Gaussian Splatting (3DGS), leverages an explicit representation to achieve real-time rendering with high-quality results. However, 3DGS still requires an abundance of training views to generate a coherent scene representation. In few shot settings, similar to NeRF, 3DGS tends to overfit to training views, causing background collapse and excessive floaters, especially as the number of training views are reduced. We propose a method to enable training coherent 3DGS-based radiance fields of 360 scenes from sparse training views. We find that using naive depth priors is not sufficient and integrate depth priors with generative and explicit constraints to reduce background collapse, remove floaters, and enhance consistency from unseen viewpoints. Experiments show that our method outperforms base 3DGS by up to 30.5% and NeRF-based methods by up to 15.6% in LPIPS on the MipNeRF-360 dataset with substantially less training and inference cost.