 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsSo3D: Inertial Navigation System and 3D Sonar SLAM for turbid environment inspection
Jan 09, 2026This paper presents InsSo3D, an accurate and efficient method for large-scale 3D Simultaneous Localisation and Mapping (SLAM) using a 3D Sonar and an Inertial Navigation System (INS). Unlike traditional sonar, which produces 2D images containing range and azimuth information but lacks elevation information, 3D Sonar produces a 3D point cloud, which therefore does not suffer from elevation ambiguity. We introduce a robust and modern SLAM framework adapted to the 3D Sonar data using INS as prior, detecting loop closure and performing pose graph optimisation. We evaluated InsSo3D performance inside a test tank with access to ground truth data and in an outdoor flooded quarry. Comparisons to reference trajectories and maps obtained from an underwater motion tracking system and visual Structure From Motion (SFM) demonstrate that InsSo3D efficiently corrects odometry drift. The average trajectory error is below 21cm during a 50-minute-long mission, producing a map of 10m by 20m with a 9cm average reconstruction error, enabling safe inspection of natural or artificial underwater structures even in murky water conditions.
VISO: Robust Underwater Visual-Inertial-Sonar SLAM with Photometric Rendering for Dense 3D Reconstruction
Jan 03, 2026Visual challenges in underwater environments significantly hinder the accuracy of vision-based localisation and the high-fidelity dense reconstruction. In this paper, we propose VISO, a robust underwater SLAM system that fuses a stereo camera, an inertial measurement unit (IMU), and a 3D sonar to achieve accurate 6-DoF localisation and enable efficient dense 3D reconstruction with high photometric fidelity. We introduce a coarse-to-fine online calibration approach for extrinsic parameters estimation between the 3D sonar and the camera. Additionally, a photometric rendering strategy is proposed for the 3D sonar point cloud to enrich the sonar map with visual information. Extensive experiments in a laboratory tank and an open lake demonstrate that VISO surpasses current state-of-the-art underwater and visual-based SLAM algorithms in terms of localisation robustness and accuracy, while also exhibiting real-time dense 3D reconstruction performance comparable to the offline dense mapping method.
RUSSO: Robust Underwater SLAM with Sonar Optimization against Visual Degradation
Mar 03, 2025



Visual degradation in underwater environments poses unique and significant challenges, which distinguishes underwater SLAM from popular vision-based SLAM on the ground. In this paper, we propose RUSSO, a robust underwater SLAM system which fuses stereo camera, inertial measurement unit (IMU), and imaging sonar to achieve robust and accurate localization in challenging underwater environments for 6 degrees of freedom (DoF) estimation. During visual degradation, the system is reduced to a sonar-inertial system estimating 3-DoF poses. The sonar pose estimation serves as a strong prior for IMU propagation, thereby enhancing the reliability of pose estimation with IMU propagation. Additionally, we propose a SLAM initialization method that leverages the imaging sonar to counteract the lack of visual features during the initialization stage of SLAM. We extensively validate RUSSO through experiments in simulator, pool, and sea scenarios. The results demonstrate that RUSSO achieves better robustness and localization accuracy compared to the state-of-the-art visual-inertial SLAM systems, especially in visually challenging scenarios. To the best of our knowledge, this is the first time fusing stereo camera, IMU, and imaging sonar to realize robust underwater SLAM against visual degradation.
Parameter-Efficient Fine-Tuning in Large Models: A Survey of Methodologies
Oct 24, 2024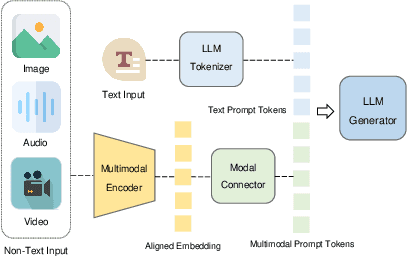
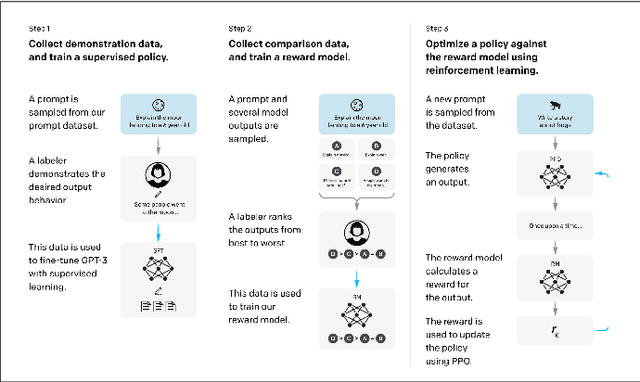
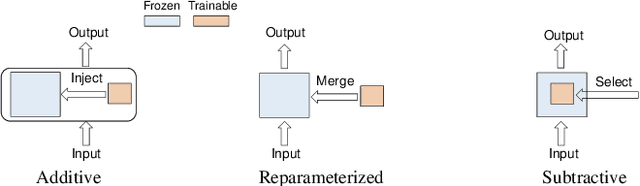
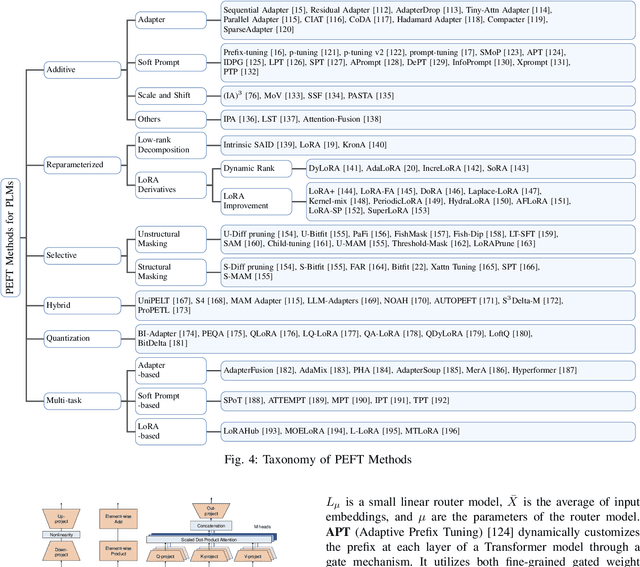
The large models, as predicted by scaling raw forecasts, have made groundbreaking progress in many fields, particularly in natural language generation tasks, where they have approached or even surpassed human levels. However, the unprecedented scale of their parameters brings significant computational and storage costs. These large models require substantial computational resources and GPU memory to operate. When adapting large models to specific downstream tasks, their massive parameter scale poses a significant challenge in fine-tuning on hardware platforms with limited computational power and GPU memory. To address this issue, Parameter-Efficient Fine-Tuning (PEFT) offers a practical solution by efficiently adjusting the parameters of large pre-trained models to suit various downstream tasks. Specifically, PEFT adjusts the parameters of pre-trained large models to adapt to specific tasks or domains, minimizing the introduction of additional parameters and the computational resources required. This review mainly introduces the preliminary knowledge of PEFT, the core ideas and principles of various PEFT algorithms, the applications of PEFT, and potential future research directions. By reading this review, we believe that interested parties can quickly grasp the PEFT methodology, thereby accelerating its development and innovation.