 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTFM: A Scalable and Alignment-free Foundation Model for Industrial Recommendation in Meituan
Feb 13, 2026Industrial recommendation systems typically involve multiple scenarios, yet existing cross-domain (CDR) and multi-scenario (MSR) methods often require prohibitive resources and strict input alignment, limiting their extensibility. We propose MTFM (Meituan Foundation Model for Recommendation), a transformer-based framework that addresses these challenges. Instead of pre-aligning inputs, MTFM transforms cross-domain data into heterogeneous tokens, capturing multi-scenario knowledge in an alignment-free manner. To enhance efficiency, we first introduce a multi-scenario user-level sample aggregation that significantly enhances training throughput by reducing the total number of instances. We further integrate Grouped-Query Attention and a customized Hybrid Target Attention to minimize memory usage and computational complexity. Furthermore, we implement various system-level optimizations, such as kernel fusion and the elimination of CPU-GPU blocking, to further enhance both training and inference throughput. Offline and online experiments validate the effectiveness of MTFM, demonstrating that significant performance gains are achieved by scaling both model capacity and multi-scenario training data.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Benchmarking and Rethinking Knowledge Editing for Large Language Models
May 24, 2025Knowledge editing aims to update the embedded knowledge within Large Language Models (LLMs). However, existing approaches, whether through parameter modification or external memory integration, often suffer from inconsistent evaluation objectives and experimental setups. To address this gap, we conduct a comprehensive benchmarking study. In addition to fact-level datasets, we introduce more complex event-based datasets and general-purpose datasets drawn from other tasks. Our evaluation covers both instruction-tuned and reasoning-oriented LLMs, under a realistic autoregressive inference setting rather than teacher-forced decoding. Beyond single-edit assessments, we also evaluate multi-edit scenarios to better reflect practical demands. We employ four evaluation dimensions, including portability, and compare all recent methods against a simple and straightforward baseline named Selective Contextual Reasoning (SCR). Empirical results reveal that parameter-based editing methods perform poorly under realistic conditions. In contrast, SCR consistently outperforms them across all settings. This study offers new insights into the limitations of current knowledge editing methods and highlights the potential of context-based reasoning as a more robust alternative.
MAGI-1: Autoregressive Video Generation at Scale
May 19, 2025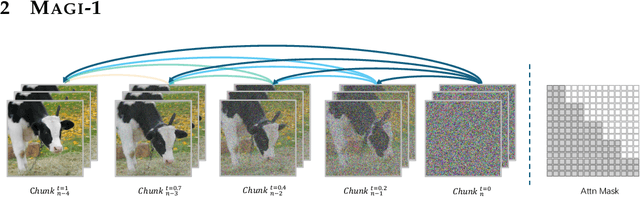
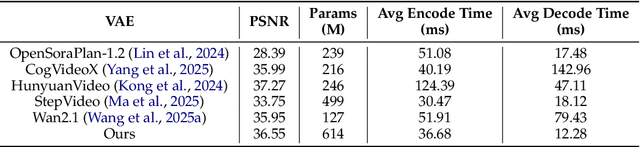
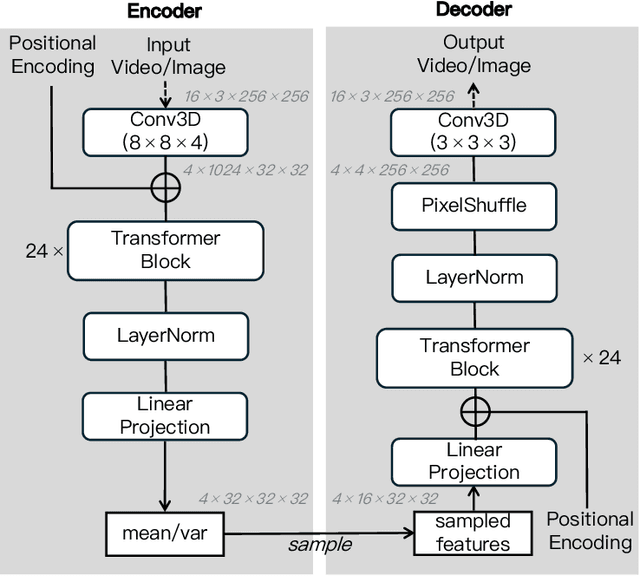
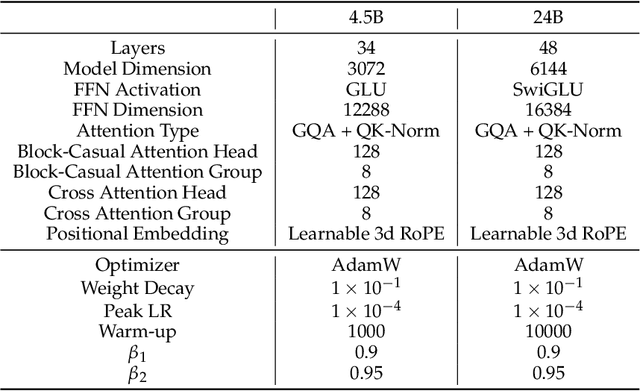
We present MAGI-1, a world model that generates videos by autoregressively predicting a sequence of video chunks, defined as fixed-length segments of consecutive frames. Trained to denoise per-chunk noise that increases monotonically over time, MAGI-1 enables causal temporal modeling and naturally supports streaming generation. It achieves strong performance on image-to-video (I2V) tasks conditioned on text instructions, providing high temporal consistency and scalability, which are made possible by several algorithmic innovations and a dedicated infrastructure stack. MAGI-1 facilitates controllable generation via chunk-wise prompting and supports real-time, memory-efficient deployment by maintaining constant peak inference cost, regardless of video length. The largest variant of MAGI-1 comprises 24 billion parameters and supports context lengths of up to 4 million tokens, demonstrating the scalability and robustness of our approach. The code and models are available at https://github.com/SandAI-org/MAGI-1 and https://github.com/SandAI-org/MagiAttention. The product can be accessed at https://sand.ai.
Knowledge Updating? No More Model Editing! Just Selective Contextual Reasoning
Mar 07, 2025As real-world knowledge evolves, the information embedded within large language models (LLMs) can become outdated, inadequate, or erroneous. Model editing has emerged as a prominent approach for updating LLMs' knowledge with minimal computational costs and parameter changes. This approach typically identifies and adjusts specific model parameters associated with newly acquired knowledge. However, existing methods often underestimate the adverse effects that parameter modifications can have on broadly distributed knowledge. More critically, post-edit LLMs frequently struggle with multi-hop reasoning and continuous knowledge updates. Although various studies have discussed these shortcomings, there is a lack of comprehensive evaluation. In this paper, we provide an evaluation of ten model editing methods along four dimensions: reliability, generalization, locality, and portability. Results confirm that all ten popular model editing methods show significant shortcomings across multiple dimensions, suggesting model editing is less promising. We then propose a straightforward method called Selective Contextual Reasoning (SCR), for knowledge updating. SCR does not modify model parameters but harnesses LLM's inherent contextual reasoning capabilities utilizing the updated knowledge pieces. Under SCR, an LLM first assesses whether an incoming query falls within the scope of an external knowledge base. If it does, the relevant external knowledge texts are contextualized to enhance reasoning; otherwise, the query is answered directly. We evaluate SCR against the ten model editing methods on two counterfactual datasets with three backbone LLMs. Empirical results confirm the effectiveness and efficiency of contextual reasoning for knowledge updating.
Efficient Long Sequential Low-rank Adaptive Attention for Click-through rate Prediction
Mar 04, 2025In the context of burgeoning user historical behavior data, Accurate click-through rate(CTR) prediction requires effective modeling of lengthy user behavior sequences. As the volume of such data keeps swelling, the focus of research has shifted towards developing effective long-term behavior modeling methods to capture latent user interests. Nevertheless, the complexity introduced by large scale data brings about computational hurdles. There is a pressing need to strike a balance between achieving high model performance and meeting the strict response time requirements of online services. While existing retrieval-based methods (e.g., similarity filtering or attention approximation) achieve practical runtime efficiency, they inherently compromise information fidelity through aggressive sequence truncation or attention sparsification. This paper presents a novel attention mechanism. It overcomes the shortcomings of existing methods while ensuring computational efficiency. This mechanism learn compressed representation of sequence with length $L$ via low-rank projection matrices (rank $r \ll L$), reducing attention complexity from $O(L)$ to $O(r)$. It also integrates a uniquely designed loss function to preserve nonlinearity of attention. In the inference stage, the mechanism adopts matrix absorption and prestorage strategies. These strategies enable it to effectively satisfy online constraints. Comprehensive offline and online experiments demonstrate that the proposed method outperforms current state-of-the-art solutions.
Interweaving Memories of a Siamese Large Language Model
Dec 23, 2024Parameter-efficient fine-tuning (PEFT) methods optimize large language models (LLMs) by modifying or introducing a small number of parameters to enhance alignment with downstream tasks. However, they can result in catastrophic forgetting, where LLMs prioritize new knowledge at the expense of comprehensive world knowledge. A promising approach to mitigate this issue is to recall prior memories based on the original knowledge. To this end, we propose a model-agnostic PEFT framework, IMSM, which Interweaves Memories of a Siamese Large Language Model. Specifically, our siamese LLM is equipped with an existing PEFT method. Given an incoming query, it generates two distinct memories based on the pre-trained and fine-tuned parameters. IMSM then incorporates an interweaving mechanism that regulates the contributions of both original and enhanced memories when generating the next token. This framework is theoretically applicable to all open-source LLMs and existing PEFT methods. We conduct extensive experiments across various benchmark datasets, evaluating the performance of popular open-source LLMs using the proposed IMSM, in comparison to both classical and leading PEFT methods. Our findings indicate that IMSM maintains comparable time and space efficiency to backbone PEFT methods while significantly improving performance and effectively mitigating catastrophic forgetting.
A Unified Temporal Knowledge Graph Reasoning Model Towards Interpolation and Extrapolation
May 28, 2024



Temporal knowledge graph (TKG) reasoning has two settings: interpolation reasoning and extrapolation reasoning. Both of them draw plenty of research interest and have great significance. Methods of the former de-emphasize the temporal correlations among facts sequences, while methods of the latter require strict chronological order of knowledge and ignore inferring clues provided by missing facts of the past. These limit the practicability of TKG applications as almost all of the existing TKG reasoning methods are designed specifically to address either one setting. To this end, this paper proposes an original Temporal PAth-based Reasoning (TPAR) model for both the interpolation and extrapolation reasoning. TPAR performs a neural-driven symbolic reasoning fashion that is robust to ambiguous and noisy temporal data and with fine interpretability as well. Comprehensive experiments show that TPAR outperforms SOTA methods on the link prediction task for both the interpolation and the extrapolation settings. A novel pipeline experimental setting is designed to evaluate the performances of SOTA combinations and the proposed TPAR towards interpolation and extrapolation reasoning. More diverse experiments are conducted to show the robustness and interpretability of TPAR.
The Solution for the ICCV 2023 1st Scientific Figure Captioning Challenge
Mar 26, 2024



In this paper, we propose a solution for improving the quality of captions generated for figures in papers. We adopt the approach of summarizing the textual content in the paper to generate image captions. Throughout our study, we encounter discrepancies in the OCR information provided in the official dataset. To rectify this, we employ the PaddleOCR toolkit to extract OCR information from all images. Moreover, we observe that certain textual content in the official paper pertains to images that are not relevant for captioning, thereby introducing noise during caption generation. To mitigate this issue, we leverage LLaMA to extract image-specific information by querying the textual content based on image mentions, effectively filtering out extraneous information. Additionally, we recognize a discrepancy between the primary use of maximum likelihood estimation during text generation and the evaluation metrics such as ROUGE employed to assess the quality of generated captions. To bridge this gap, we integrate the BRIO model framework, enabling a more coherent alignment between the generation and evaluation processes. Our approach ranked first in the final test with a score of 4.49.
Robust Semi-Supervised Learning for Self-learning Open-World Classes
Jan 15, 2024
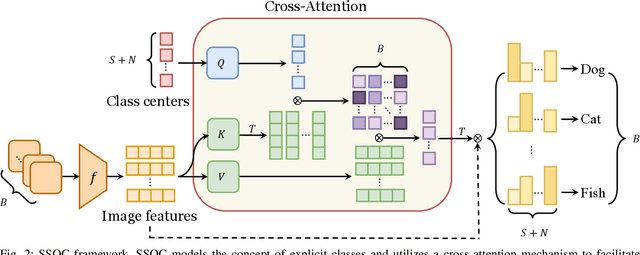
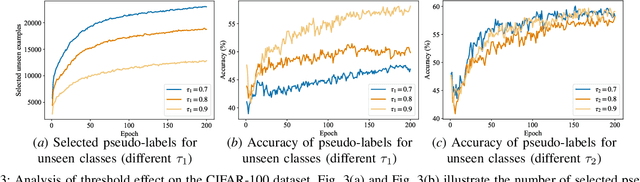
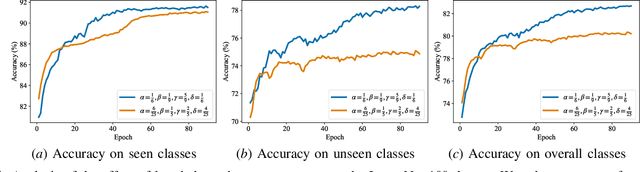
Existing semi-supervised learning (SSL) methods assume that labeled and unlabeled data share the same class space. However, in real-world applications, unlabeled data always contain classes not present in the labeled set, which may cause classification performance degradation of known classes. Therefore, open-world SSL approaches are researched to handle the presence of multiple unknown classes in the unlabeled data, which aims to accurately classify known classes while fine-grained distinguishing different unknown classes. To address this challenge, in this paper, we propose an open-world SSL method for Self-learning Open-world Classes (SSOC), which can explicitly self-learn multiple unknown classes. Specifically, SSOC first defines class center tokens for both known and unknown classes and autonomously learns token representations according to all samples with the cross-attention mechanism. To effectively discover novel classes, SSOC further designs a pairwise similarity loss in addition to the entropy loss, which can wisely exploit the information available in unlabeled data from instances' predictions and relationships. Extensive experiments demonstrate that SSOC outperforms the state-of-the-art baselines on multiple popular classification benchmarks. Specifically, on the ImageNet-100 dataset with a novel ratio of 90%, SSOC achieves a remarkable 22% improvement.