 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRebalanced Vision-Language Retrieval Considering Structure-Aware Distillation
Dec 14, 2024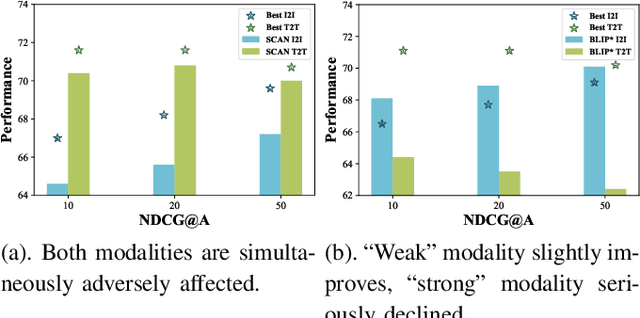
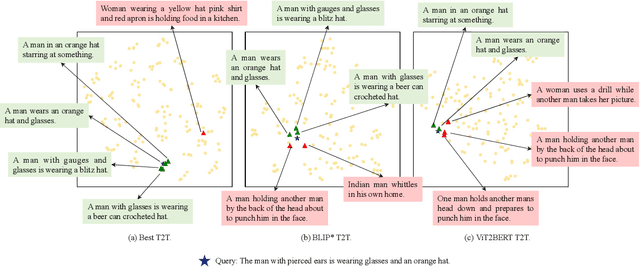
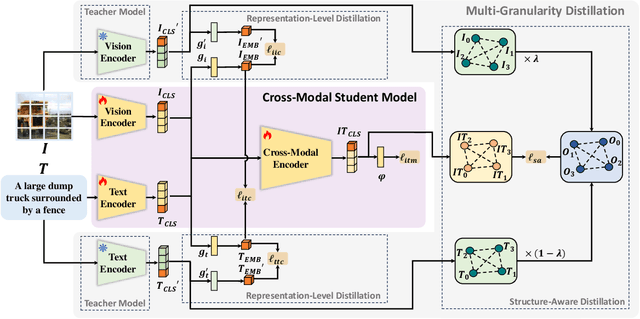
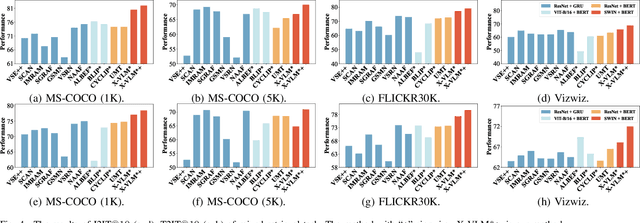
Vision-language retrieval aims to search for similar instances in one modality based on queries from another modality. The primary objective is to learn cross-modal matching representations in a latent common space. Actually, the assumption underlying cross-modal matching is modal balance, where each modality contains sufficient information to represent the others. However, noise interference and modality insufficiency often lead to modal imbalance, making it a common phenomenon in practice. The impact of imbalance on retrieval performance remains an open question. In this paper, we first demonstrate that ultimate cross-modal matching is generally sub-optimal for cross-modal retrieval when imbalanced modalities exist. The structure of instances in the common space is inherently influenced when facing imbalanced modalities, posing a challenge to cross-modal similarity measurement. To address this issue, we emphasize the importance of meaningful structure-preserved matching. Accordingly, we propose a simple yet effective method to rebalance cross-modal matching by learning structure-preserved matching representations. Specifically, we design a novel multi-granularity cross-modal matching that incorporates structure-aware distillation alongside the cross-modal matching loss. While the cross-modal matching loss constraints instance-level matching, the structure-aware distillation further regularizes the geometric consistency between learned matching representations and intra-modal representations through the developed relational matching. Extensive experiments on different datasets affirm the superior cross-modal retrieval performance of our approach, simultaneously enhancing single-modal retrieval capabilities compared to the baseline models.
Robust Semi-Supervised Learning for Self-learning Open-World Classes
Jan 15, 2024
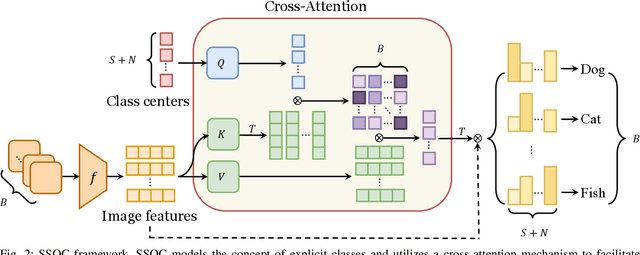
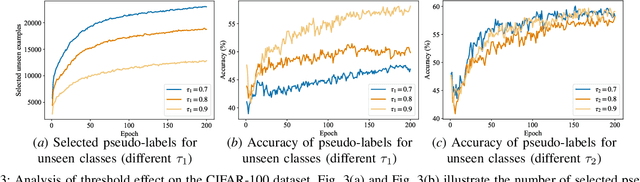
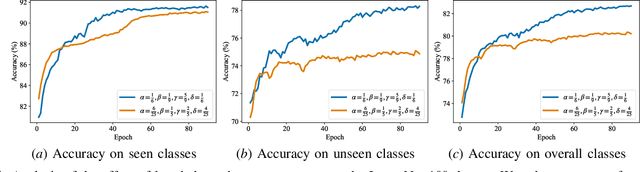
Existing semi-supervised learning (SSL) methods assume that labeled and unlabeled data share the same class space. However, in real-world applications, unlabeled data always contain classes not present in the labeled set, which may cause classification performance degradation of known classes. Therefore, open-world SSL approaches are researched to handle the presence of multiple unknown classes in the unlabeled data, which aims to accurately classify known classes while fine-grained distinguishing different unknown classes. To address this challenge, in this paper, we propose an open-world SSL method for Self-learning Open-world Classes (SSOC), which can explicitly self-learn multiple unknown classes. Specifically, SSOC first defines class center tokens for both known and unknown classes and autonomously learns token representations according to all samples with the cross-attention mechanism. To effectively discover novel classes, SSOC further designs a pairwise similarity loss in addition to the entropy loss, which can wisely exploit the information available in unlabeled data from instances' predictions and relationships. Extensive experiments demonstrate that SSOC outperforms the state-of-the-art baselines on multiple popular classification benchmarks. Specifically, on the ImageNet-100 dataset with a novel ratio of 90%, SSOC achieves a remarkable 22% improvement.
Joint Multi-frame Detection and Segmentation for Multi-cell Tracking
Jun 26, 2019
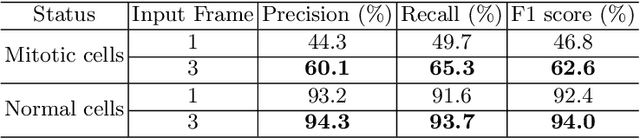

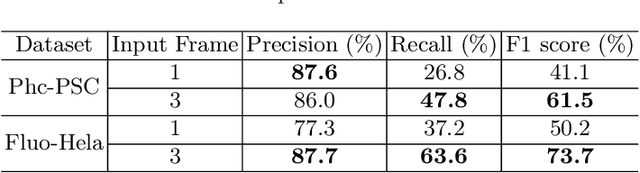
Tracking living cells in video sequence is difficult, because of cell morphology and high similarities between cells. Tracking-by-detection methods are widely used in multi-cell tracking. We perform multi-cell tracking based on the cell centroid detection, and the performance of the detector has high impact on tracking performance. In this paper, UNet is utilized to extract inter-frame and intra-frame spatio-temporal information of cells. Detection performance of cells in mitotic phase is improved by multi-frame input. Good detection results facilitate multi-cell tracking. A mitosis detection algorithm is proposed to detect cell mitosis and the cell lineage is built up. Another UNet is utilized to acquire primary segmentation. Jointly using detection and primary segmentation, cells can be fine segmented in highly dense cell population. Experiments are conducted to evaluate the effectiveness of our method, and results show its state-of-the-art performance.