 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Longer to Explore Deeper: Learn to Explore In-Context via Length-Incentivized Reinforcement Learning
Feb 12, 2026Achieving effective test-time scaling requires models to engage in In-Context Exploration -- the intrinsic ability to generate, verify, and refine multiple reasoning hypotheses within a single continuous context. Grounded in State Coverage theory, our analysis identifies a critical bottleneck to enabling this capability: while broader state coverage requires longer reasoning trajectories, the probability of sampling such sequences decays exponentially during autoregressive generation, a phenomenon we term the ``Shallow Exploration Trap''. To bridge this gap, we propose Length-Incentivized Exploration(\method). This simple yet effective recipe explicitly encourages models to explore more via a length-based reward coupled with a redundancy penalty, thereby maximizing state coverage in two-step manner. Comprehensive experiments across different models (Qwen3, Llama) demonstrate that \method effectively incentivize in-context exploration. As a result, our method achieves an average improvement of 4.4\% on in-domain tasks and a 2.7\% gain on out-of-domain benchmarks.
P1-VL: Bridging Visual Perception and Scientific Reasoning in Physics Olympiads
Feb 10, 2026The transition from symbolic manipulation to science-grade reasoning represents a pivotal frontier for Large Language Models (LLMs), with physics serving as the critical test anchor for binding abstract logic to physical reality. Physics demands that a model maintain physical consistency with the laws governing the universe, a task that fundamentally requires multimodal perception to ground abstract logic in reality. At the Olympiad level, diagrams are often constitutive rather than illustrative, containing essential constraints, such as boundary conditions and spatial symmetries, that are absent from the text. To bridge this visual-logical gap, we introduce P1-VL, a family of open-source vision-language models engineered for advanced scientific reasoning. Our method harmonizes Curriculum Reinforcement Learning, which employs progressive difficulty expansion to stabilize post-training, with Agentic Augmentation, enabling iterative self-verification at inference. Evaluated on HiPhO, a rigorous benchmark of 13 exams from 2024-2025, our flagship P1-VL-235B-A22B becomes the first open-source Vision-Language Model (VLM) to secure 12 gold medals and achieves the state-of-the-art performance in the open-source models. Our agent-augmented system achieves the No.2 overall rank globally, trailing only Gemini-3-Pro. Beyond physics, P1-VL demonstrates remarkable scientific reasoning capacity and generalizability, establishing significant leads over base models in STEM benchmarks. By open-sourcing P1-VL, we provide a foundational step toward general-purpose physical intelligence to better align visual perceptions with abstract physical laws for machine scientific discovery.
Rethinking Expert Trajectory Utilization in LLM Post-training
Dec 12, 2025While effective post-training integrates Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), the optimal mechanism for utilizing expert trajectories remains unresolved. We propose the Plasticity-Ceiling Framework to theoretically ground this landscape, decomposing performance into foundational SFT performance and the subsequent RL plasticity. Through extensive benchmarking, we establish the Sequential SFT-then-RL pipeline as the superior standard, overcoming the stability deficits of synchronized approaches. Furthermore, we derive precise scaling guidelines: (1) Transitioning to RL at the SFT Stable or Mild Overfitting Sub-phase maximizes the final ceiling by securing foundational SFT performance without compromising RL plasticity; (2) Refuting ``Less is More'' in the context of SFT-then-RL scaling, we demonstrate that Data Scale determines the primary post-training potential, while Trajectory Difficulty acts as a performance multiplier; and (3) Identifying that the Minimum SFT Validation Loss serves as a robust indicator for selecting the expert trajectories that maximize the final performance ceiling. Our findings provide actionable guidelines for maximizing the value extracted from expert trajectories.
P1: Mastering Physics Olympiads with Reinforcement Learning
Nov 17, 2025Recent progress in large language models (LLMs) has moved the frontier from puzzle-solving to science-grade reasoning-the kind needed to tackle problems whose answers must stand against nature, not merely fit a rubric. Physics is the sharpest test of this shift, which binds symbols to reality in a fundamental way, serving as the cornerstone of most modern technologies. In this work, we manage to advance physics research by developing large language models with exceptional physics reasoning capabilities, especially excel at solving Olympiad-level physics problems. We introduce P1, a family of open-source physics reasoning models trained entirely through reinforcement learning (RL). Among them, P1-235B-A22B is the first open-source model with Gold-medal performance at the latest International Physics Olympiad (IPhO 2025), and wins 12 gold medals out of 13 international/regional physics competitions in 2024/2025. P1-30B-A3B also surpasses almost all other open-source models on IPhO 2025, getting a silver medal. Further equipped with an agentic framework PhysicsMinions, P1-235B-A22B+PhysicsMinions achieves overall No.1 on IPhO 2025, and obtains the highest average score over the 13 physics competitions. Besides physics, P1 models also present great performance on other reasoning tasks like math and coding, showing the great generalibility of P1 series.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Benchmarking and Rethinking Knowledge Editing for Large Language Models
May 24, 2025Knowledge editing aims to update the embedded knowledge within Large Language Models (LLMs). However, existing approaches, whether through parameter modification or external memory integration, often suffer from inconsistent evaluation objectives and experimental setups. To address this gap, we conduct a comprehensive benchmarking study. In addition to fact-level datasets, we introduce more complex event-based datasets and general-purpose datasets drawn from other tasks. Our evaluation covers both instruction-tuned and reasoning-oriented LLMs, under a realistic autoregressive inference setting rather than teacher-forced decoding. Beyond single-edit assessments, we also evaluate multi-edit scenarios to better reflect practical demands. We employ four evaluation dimensions, including portability, and compare all recent methods against a simple and straightforward baseline named Selective Contextual Reasoning (SCR). Empirical results reveal that parameter-based editing methods perform poorly under realistic conditions. In contrast, SCR consistently outperforms them across all settings. This study offers new insights into the limitations of current knowledge editing methods and highlights the potential of context-based reasoning as a more robust alternative.
Keys to Robust Edits: from Theoretical Insights to Practical Advances
Oct 12, 2024Large language models (LLMs) have revolutionized knowledge storage and retrieval, but face challenges with conflicting and outdated information. Knowledge editing techniques have been proposed to address these issues, yet they struggle with robustness tests involving long contexts, paraphrased subjects, and continuous edits. This work investigates the cause of these failures in locate-and-edit methods, offering theoretical insights into their key-value modeling and deriving mathematical bounds for robust and specific edits, leading to a novel 'group discussion' conceptual model for locate-and-edit methods. Empirical analysis reveals that keys used by current methods fail to meet robustness and specificity requirements. To address this, we propose a Robust Edit Pathway (REP) that disentangles editing keys from LLMs' inner representations. Evaluations on LLaMA2-7B and Mistral-7B using the CounterFact dataset show that REP significantly improves robustness across various metrics, both in-domain and out-of-domain, with minimal trade-offs in success rate and locality. Our findings advance the development of reliable and flexible knowledge updating in LLMs.
ELICIT: LLM Augmentation via External In-Context Capability
Oct 12, 2024


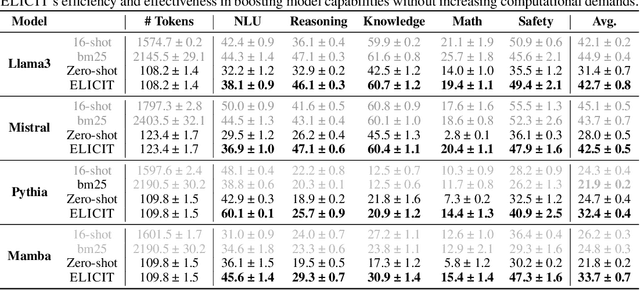
Enhancing the adaptive capabilities of large language models is a critical pursuit in both research and application. Traditional fine-tuning methods require substantial data and computational resources, especially for enhancing specific capabilities, while in-context learning is limited by the need for appropriate demonstrations and efficient token usage. Inspired by the expression of in-context learned capabilities through task vectors and the concept of modularization, we propose \alg, a framework consisting of two modules designed to effectively store and reuse task vectors to elicit the diverse capabilities of models without additional training or inference tokens. Our comprehensive experiments and analysis demonstrate that our pipeline is highly transferable across different input formats, tasks, and model architectures. ELICIT serves as a plug-and-play performance booster to enable adaptive elicitation of model capabilities. By externally storing and reusing vectors that represent in-context learned capabilities, \alg not only demonstrates the potential to operate modular capabilities but also significantly enhances the performance, versatility, adaptability, and scalability of large language models. Our code will be publicly available at https://github.com/LINs-lab/ELICIT.
Potential and Challenges of Model Editing for Social Debiasing
Feb 21, 2024Large language models (LLMs) trained on vast corpora suffer from inevitable stereotype biases. Mitigating these biases with fine-tuning could be both costly and data-hungry. Model editing methods, which focus on modifying LLMs in a post-hoc manner, are of great potential to address debiasing. However, it lacks a comprehensive study that facilitates both internal and external model editing methods, supports various bias types, as well as understands the pros and cons of applying editing methods to stereotypical debiasing. To mitigate this gap, we carefully formulate social debiasing into an editing problem and benchmark seven existing model editing algorithms on stereotypical debiasing, i.e., debias editing. Our findings in three scenarios reveal both the potential and challenges of debias editing: (1) Existing model editing methods can effectively preserve knowledge and mitigate biases, while the generalization of debias effect from edited sentences to semantically equivalent sentences is limited.(2) Sequential editing highlights the robustness of SERAC (Mitchell et al. 2022b), while internal editing methods degenerate with the number of edits. (3) Model editing algorithms achieve generalization towards unseen biases both within the same type and from different types. In light of these findings, we further propose two simple but effective methods to improve debias editing, and experimentally show the effectiveness of the proposed methods.