 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Aware Speculative Decoding Toward Improved LLM Reasoning
Dec 29, 2025Speculative decoding (SD) accelerates large language model (LLM) reasoning by using a small draft model to generate candidate tokens, which the target LLM either accepts directly or regenerates upon rejection. However, excessive alignment between the draft and target models constrains SD to the performance of the target LLM. To address this limitation, we propose Entropy-Aware Speculative Decoding (EASD), a training-free enhancement. Building on standard SD, EASD incorporates a dynamic entropy-based penalty. At each decoding step, we employ the entropy of the sampling distribution to quantify model uncertainty. When both models exhibit high entropy with substantial overlap among their top-N predictions, the corresponding token is rejected and re-sampled by the target LLM. This penalty prevents low-confidence errors from propagating. By incorporating draft-model verification, EASD enables the possibility of surpassing the target model's inherent performance. Experiments across multiple reasoning benchmarks demonstrate that EASD consistently outperforms existing SD methods and, in most cases, surpasses the target LLM itself. We further prove that the efficiency of EASD is comparable to that of SD. The code can be found in the Supplementary Materials.
Benchmarking and Rethinking Knowledge Editing for Large Language Models
May 24, 2025Knowledge editing aims to update the embedded knowledge within Large Language Models (LLMs). However, existing approaches, whether through parameter modification or external memory integration, often suffer from inconsistent evaluation objectives and experimental setups. To address this gap, we conduct a comprehensive benchmarking study. In addition to fact-level datasets, we introduce more complex event-based datasets and general-purpose datasets drawn from other tasks. Our evaluation covers both instruction-tuned and reasoning-oriented LLMs, under a realistic autoregressive inference setting rather than teacher-forced decoding. Beyond single-edit assessments, we also evaluate multi-edit scenarios to better reflect practical demands. We employ four evaluation dimensions, including portability, and compare all recent methods against a simple and straightforward baseline named Selective Contextual Reasoning (SCR). Empirical results reveal that parameter-based editing methods perform poorly under realistic conditions. In contrast, SCR consistently outperforms them across all settings. This study offers new insights into the limitations of current knowledge editing methods and highlights the potential of context-based reasoning as a more robust alternative.
Knowledge Updating? No More Model Editing! Just Selective Contextual Reasoning
Mar 07, 2025As real-world knowledge evolves, the information embedded within large language models (LLMs) can become outdated, inadequate, or erroneous. Model editing has emerged as a prominent approach for updating LLMs' knowledge with minimal computational costs and parameter changes. This approach typically identifies and adjusts specific model parameters associated with newly acquired knowledge. However, existing methods often underestimate the adverse effects that parameter modifications can have on broadly distributed knowledge. More critically, post-edit LLMs frequently struggle with multi-hop reasoning and continuous knowledge updates. Although various studies have discussed these shortcomings, there is a lack of comprehensive evaluation. In this paper, we provide an evaluation of ten model editing methods along four dimensions: reliability, generalization, locality, and portability. Results confirm that all ten popular model editing methods show significant shortcomings across multiple dimensions, suggesting model editing is less promising. We then propose a straightforward method called Selective Contextual Reasoning (SCR), for knowledge updating. SCR does not modify model parameters but harnesses LLM's inherent contextual reasoning capabilities utilizing the updated knowledge pieces. Under SCR, an LLM first assesses whether an incoming query falls within the scope of an external knowledge base. If it does, the relevant external knowledge texts are contextualized to enhance reasoning; otherwise, the query is answered directly. We evaluate SCR against the ten model editing methods on two counterfactual datasets with three backbone LLMs. Empirical results confirm the effectiveness and efficiency of contextual reasoning for knowledge updating.
Interweaving Memories of a Siamese Large Language Model
Dec 23, 2024Parameter-efficient fine-tuning (PEFT) methods optimize large language models (LLMs) by modifying or introducing a small number of parameters to enhance alignment with downstream tasks. However, they can result in catastrophic forgetting, where LLMs prioritize new knowledge at the expense of comprehensive world knowledge. A promising approach to mitigate this issue is to recall prior memories based on the original knowledge. To this end, we propose a model-agnostic PEFT framework, IMSM, which Interweaves Memories of a Siamese Large Language Model. Specifically, our siamese LLM is equipped with an existing PEFT method. Given an incoming query, it generates two distinct memories based on the pre-trained and fine-tuned parameters. IMSM then incorporates an interweaving mechanism that regulates the contributions of both original and enhanced memories when generating the next token. This framework is theoretically applicable to all open-source LLMs and existing PEFT methods. We conduct extensive experiments across various benchmark datasets, evaluating the performance of popular open-source LLMs using the proposed IMSM, in comparison to both classical and leading PEFT methods. Our findings indicate that IMSM maintains comparable time and space efficiency to backbone PEFT methods while significantly improving performance and effectively mitigating catastrophic forgetting.
Not All Videos Become Outdated: Short-Video Recommendation by Learning to Deconfound Release Interval Bias
Aug 30, 2024Short-video recommender systems often exhibit a biased preference to recently released videos. However, not all videos become outdated; certain classic videos can still attract user's attention. Such bias along temporal dimension can be further aggravated by the matching model between users and videos, because the model learns from preexisting interactions. From real data, we observe that different videos have varying sensitivities to recency in attracting users' attention. Our analysis, based on a causal graph modeling short-video recommendation, suggests that the release interval serves as a confounder, establishing a backdoor path between users and videos. To address this confounding effect, we propose a model-agnostic causal architecture called Learning to Deconfound the Release Interval Bias (LDRI). LDRI enables jointly learning of the matching model and the video recency sensitivity perceptron. In the inference stage, we apply a backdoor adjustment, effectively blocking the backdoor path by intervening on each video. Extensive experiments on two benchmarks demonstrate that LDRI consistently outperforms backbone models and exhibits superior performance against state-of-the-art models. Additional comprehensive analyses confirm the deconfounding capability of LDRI.
Tree-Based Hard Attention with Self-Motivation for Large Language Models
Feb 14, 2024



While large language models (LLMs) excel at understanding and generating plain text, they are not specifically tailored to handle hierarchical text structures. Extracting the task-desired property from their natural language responses typically necessitates additional processing steps. In fact, selectively comprehending the hierarchical structure of large-scale text is pivotal to understanding its substance. Aligning LLMs more closely with the classification or regression values of specific task through prompting also remains challenging. To this end, we propose a novel framework called Tree-Based Hard Attention with Self-Motivation for Large Language Models (TEAROOM). TEAROOM incorporates a tree-based hard attention mechanism for LLMs to process hierarchically structured text inputs. By leveraging prompting, it enables a frozen LLM to selectively focus on relevant leaves in relation to the root, generating a tailored symbolic representation of their relationship. Moreover, TEAROOM comprises a self-motivation strategy for another LLM equipped with a trainable adapter and a linear layer. The selected symbolic outcomes are integrated into another prompt, along with the predictive value of the task. We iteratively feed output values back into the prompt, enabling the trainable LLM to progressively approximate the golden truth. TEAROOM outperforms existing state-of-the-art methods in experimental evaluations across three benchmark datasets, showing its effectiveness in estimating task-specific properties. Through comprehensive experiments and analysis, we have validated the ability of TEAROOM to gradually approach the underlying golden truth through multiple inferences.
Disentangling the Potential Impacts of Papers into Diffusion, Conformity, and Contribution Values
Nov 15, 2023



The potential impact of an academic paper is determined by various factors, including its popularity and contribution. Existing models usually estimate original citation counts based on static graphs and fail to differentiate values from nuanced perspectives. In this study, we propose a novel graph neural network to Disentangle the Potential impacts of Papers into Diffusion, Conformity, and Contribution values (called DPPDCC). Given a target paper, DPPDCC encodes temporal and structural features within the constructed dynamic heterogeneous graph. Particularly, to capture the knowledge flow, we emphasize the importance of comparative and co-cited/citing information between papers and aggregate snapshots evolutionarily. To unravel popularity, we contrast augmented graphs to extract the essence of diffusion and predict the accumulated citation binning to model conformity. We further apply orthogonal constraints to encourage distinct modeling of each perspective and preserve the inherent value of contribution. To evaluate models' generalization for papers published at various times, we reformulate the problem by partitioning data based on specific time points to mirror real-world conditions. Extensive experimental results on three datasets demonstrate that DPPDCC significantly outperforms baselines for previously, freshly, and immediately published papers. Further analyses confirm its robust capabilities. We will make our datasets and codes publicly available.
H2CGL: Modeling Dynamics of Citation Network for Impact Prediction
Apr 16, 2023The potential impact of a paper is often quantified by how many citations it will receive. However, most commonly used models may underestimate the influence of newly published papers over time, and fail to encapsulate this dynamics of citation network into the graph. In this study, we construct hierarchical and heterogeneous graphs for target papers with an annual perspective. The constructed graphs can record the annual dynamics of target papers' scientific context information. Then, a novel graph neural network, Hierarchical and Heterogeneous Contrastive Graph Learning Model (H2CGL), is proposed to incorporate heterogeneity and dynamics of the citation network. H2CGL separately aggregates the heterogeneous information for each year and prioritizes the highly-cited papers and relationships among references, citations, and the target paper. It then employs a weighted GIN to capture dynamics between heterogeneous subgraphs over years. Moreover, it leverages contrastive learning to make the graph representations more sensitive to potential citations. Particularly, co-cited or co-citing papers of the target paper with large citation gap are taken as hard negative samples, while randomly dropping low-cited papers could generate positive samples. Extensive experimental results on two scholarly datasets demonstrate that the proposed H2CGL significantly outperforms a series of baseline approaches for both previously and freshly published papers. Additional analyses highlight the significance of the proposed modules. Our codes and settings have been released on Github (https://github.com/ECNU-Text-Computing/H2CGL)
A Role-Selected Sharing Network for Joint Machine-Human Chatting Handoff and Service Satisfaction Analysis
Sep 17, 2021

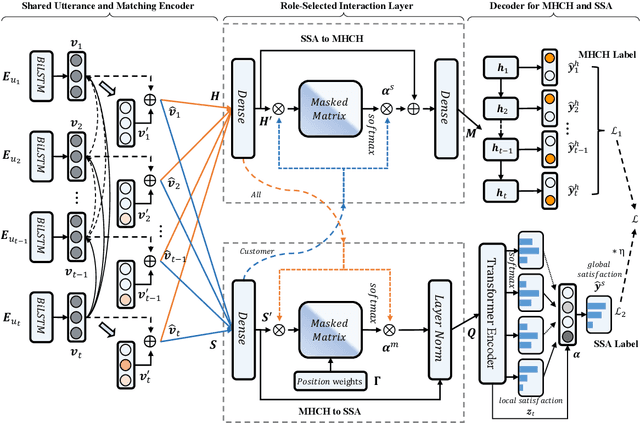

Chatbot is increasingly thriving in different domains, however, because of unexpected discourse complexity and training data sparseness, its potential distrust hatches vital apprehension. Recently, Machine-Human Chatting Handoff (MHCH), predicting chatbot failure and enabling human-algorithm collaboration to enhance chatbot quality, has attracted increasing attention from industry and academia. In this study, we propose a novel model, Role-Selected Sharing Network (RSSN), which integrates both dialogue satisfaction estimation and handoff prediction in one multi-task learning framework. Unlike prior efforts in dialog mining, by utilizing local user satisfaction as a bridge, global satisfaction detector and handoff predictor can effectively exchange critical information. Specifically, we decouple the relation and interaction between the two tasks by the role information after the shared encoder. Extensive experiments on two public datasets demonstrate the effectiveness of our model.
Time to Transfer: Predicting and Evaluating Machine-Human Chatting Handoff
Dec 14, 2020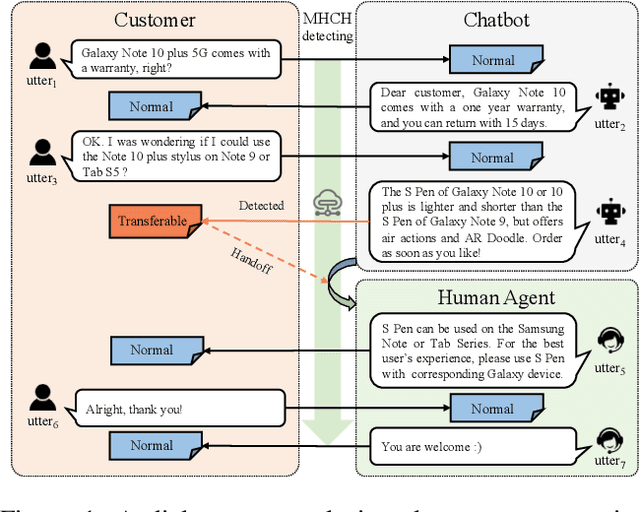
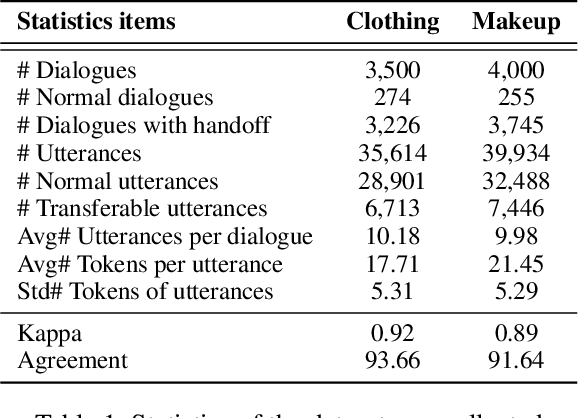

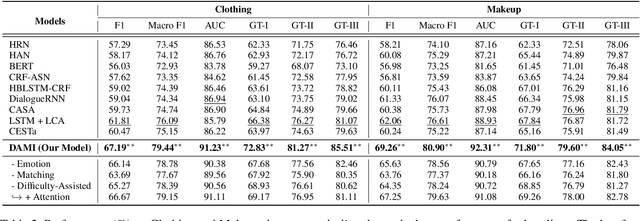
Is chatbot able to completely replace the human agent? The short answer could be - "it depends...". For some challenging cases, e.g., dialogue's topical spectrum spreads beyond the training corpus coverage, the chatbot may malfunction and return unsatisfied utterances. This problem can be addressed by introducing the Machine-Human Chatting Handoff (MHCH), which enables human-algorithm collaboration. To detect the normal/transferable utterances, we propose a Difficulty-Assisted Matching Inference (DAMI) network, utilizing difficulty-assisted encoding to enhance the representations of utterances. Moreover, a matching inference mechanism is introduced to capture the contextual matching features. A new evaluation metric, Golden Transfer within Tolerance (GT-T), is proposed to assess the performance by considering the tolerance property of the MHCH. To provide insights into the task and validate the proposed model, we collect two new datasets. Extensive experimental results are presented and contrasted against a series of baseline models to demonstrate the efficacy of our model on MHCH.