 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecNextEval: A Reference Implementation for Temporal Next-Batch Recommendation Evaluation
Apr 15, 2026A good number of toolkits have been developed in Recommender Systems (RecSys) research to promote fair evaluation and reproducibility. However, recent critical examinations of RecSys evaluation protocols have raised concerns regarding the validity of existing evaluation pipelines. In this demonstration, we present RecNextEval, a reference implementation of an evaluation framework specifically designed for next-batch recommendation. RecNextEval utilizes a time-window data split to ensure models are evaluated along a global timeline, effectively minimizing data leakage. Our implementation highlights the inherent complexities of RecSys evaluation and encourages a shift toward model development that more accurately simulates production environments. The RecNextEval library and its accompanying GUI interface are open-source and publicly accessible.
MARS: Enabling Autoregressive Models Multi-Token Generation
Apr 08, 2026Autoregressive (AR) language models generate text one token at a time, even when consecutive tokens are highly predictable given earlier context. We introduce MARS (Mask AutoRegreSsion), a lightweight fine-tuning method that teaches an instruction-tuned AR model to predict multiple tokens per forward pass. MARS adds no architectural modifications, no extra parameters, and produces a single model that can still be called exactly like the original AR model with no performance degradation. Unlike speculative decoding, which maintains a separate draft model alongside the target, or multi-head approaches such as Medusa, which attach additional prediction heads, MARS requires only continued training on existing instruction data. When generating one token per forward pass, MARS matches or exceeds the AR baseline on six standard benchmarks. When allowed to accept multiple tokens per step, it maintains baseline-level accuracy while achieving 1.5-1.7x throughput. We further develop a block-level KV caching strategy for batch inference, achieving up to 1.71x wall-clock speedup over AR with KV cache on Qwen2.5-7B. Finally, MARS supports real-time speed adjustment via confidence thresholding: under high request load, the serving system can increase throughput on the fly without swapping models or restarting, providing a practical latency-quality knob for deployment.
EMemBench: Interactive Benchmarking of Episodic Memory for VLM Agents
Jan 23, 2026We introduce EMemBench, a programmatic benchmark for evaluating long-term memory of agents through interactive games. Rather than using a fixed set of questions, EMemBench generates questions from each agent's own trajectory, covering both text and visual game environments. Each template computes verifiable ground truth from underlying game signals, with controlled answerability and balanced coverage over memory skills: single/multi-hop recall, induction, temporal, spatial, logical, and adversarial. We evaluate memory agents with strong LMs/VLMs as backbones, using in-context prompting as baselines. Across 15 text games and multiple visual seeds, results are far from saturated: induction and spatial reasoning are persistent bottlenecks, especially in visual setting. Persistent memory yields clear gains for open backbones on text games, but improvements are less consistent for VLM agents, suggesting that visually grounded episodic memory remains an open challenge. A human study further confirms the difficulty of EMemBench.
Demystifying the Slash Pattern in Attention: The Role of RoPE
Jan 13, 2026Large Language Models (LLMs) often exhibit slash attention patterns, where attention scores concentrate along the $Δ$-th sub-diagonal for some offset $Δ$. These patterns play a key role in passing information across tokens. But why do they emerge? In this paper, we demystify the emergence of these Slash-Dominant Heads (SDHs) from both empirical and theoretical perspectives. First, by analyzing open-source LLMs, we find that SDHs are intrinsic to models and generalize to out-of-distribution prompts. To explain the intrinsic emergence, we analyze the queries, keys, and Rotary Position Embedding (RoPE), which jointly determine attention scores. Our empirical analysis reveals two characteristic conditions of SDHs: (1) Queries and keys are almost rank-one, and (2) RoPE is dominated by medium- and high-frequency components. Under these conditions, queries and keys are nearly identical across tokens, and interactions between medium- and high-frequency components of RoPE give rise to SDHs. Beyond empirical evidence, we theoretically show that these conditions are sufficient to ensure the emergence of SDHs by formalizing them as our modeling assumptions. Particularly, we analyze the training dynamics of a shallow Transformer equipped with RoPE under these conditions, and prove that models trained via gradient descent exhibit SDHs. The SDHs generalize to out-of-distribution prompts.
On the Role of Discreteness in Diffusion LLMs
Dec 27, 2025Diffusion models offer appealing properties for language generation, such as parallel decoding and iterative refinement, but the discrete and highly structured nature of text challenges the direct application of diffusion principles. In this paper, we revisit diffusion language modeling from the view of diffusion process and language modeling, and outline five properties that separate diffusion mechanics from language-specific requirements. We first categorize existing approaches into continuous diffusion in embedding space and discrete diffusion over tokens. We then show that each satisfies only part of the five essential properties and therefore reflects a structural trade-off. Through analyses of recent large diffusion language models, we identify two central issues: (i) uniform corruption does not respect how information is distributed across positions, and (ii) token-wise marginal training cannot capture multi-token dependencies during parallel decoding. These observations motivate diffusion processes that align more closely with the structure of text, and encourage future work toward more coherent diffusion language models.
Event Extraction in Large Language Model
Dec 22, 2025Large language models (LLMs) and multimodal LLMs are changing event extraction (EE): prompting and generation can often produce structured outputs in zero shot or few shot settings. Yet LLM based pipelines face deployment gaps, including hallucinations under weak constraints, fragile temporal and causal linking over long contexts and across documents, and limited long horizon knowledge management within a bounded context window. We argue that EE should be viewed as a system component that provides a cognitive scaffold for LLM centered solutions. Event schemas and slot constraints create interfaces for grounding and verification; event centric structures act as controlled intermediate representations for stepwise reasoning; event links support relation aware retrieval with graph based RAG; and event stores offer updatable episodic and agent memory beyond the context window. This survey covers EE in text and multimodal settings, organizing tasks and taxonomy, tracing method evolution from rule based and neural models to instruction driven and generative frameworks, and summarizing formulations, decoding strategies, architectures, representations, datasets, and evaluation. We also review cross lingual, low resource, and domain specific settings, and highlight open challenges and future directions for reliable event centric systems. Finally, we outline open challenges and future directions that are central to the LLM era, aiming to evolve EE from static extraction into a structurally reliable, agent ready perception and memory layer for open world systems.
OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender
Oct 30, 2025In recommendation systems, scaling up feature-interaction modules (e.g., Wukong, RankMixer) or user-behavior sequence modules (e.g., LONGER) has achieved notable success. However, these efforts typically proceed on separate tracks, which not only hinders bidirectional information exchange but also prevents unified optimization and scaling. In this paper, we propose OneTrans, a unified Transformer backbone that simultaneously performs user-behavior sequence modeling and feature interaction. OneTrans employs a unified tokenizer to convert both sequential and non-sequential attributes into a single token sequence. The stacked OneTrans blocks share parameters across similar sequential tokens while assigning token-specific parameters to non-sequential tokens. Through causal attention and cross-request KV caching, OneTrans enables precomputation and caching of intermediate representations, significantly reducing computational costs during both training and inference. Experimental results on industrial-scale datasets demonstrate that OneTrans scales efficiently with increasing parameters, consistently outperforms strong baselines, and yields a 5.68% lift in per-user GMV in online A/B tests.
Does Multimodality Improve Recommender Systems as Expected? A Critical Analysis and Future Directions
Aug 07, 2025
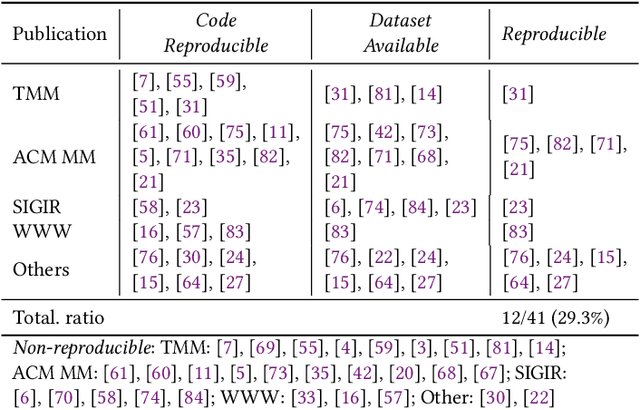
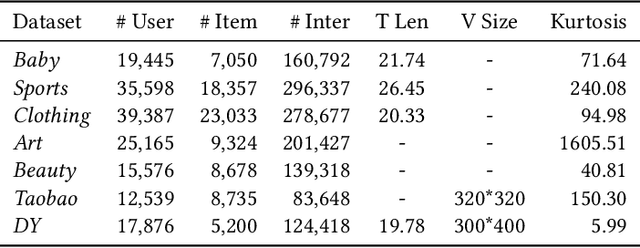
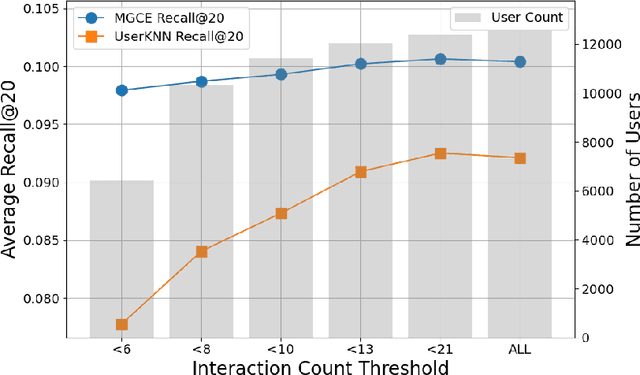
Multimodal recommendation systems are increasingly popular for their potential to improve performance by integrating diverse data types. However, the actual benefits of this integration remain unclear, raising questions about when and how it truly enhances recommendations. In this paper, we propose a structured evaluation framework to systematically assess multimodal recommendations across four dimensions: Comparative Efficiency, Recommendation Tasks, Recommendation Stages, and Multimodal Data Integration. We benchmark a set of reproducible multimodal models against strong traditional baselines and evaluate their performance on different platforms. Our findings show that multimodal data is particularly beneficial in sparse interaction scenarios and during the recall stage of recommendation pipelines. We also observe that the importance of each modality is task-specific, where text features are more useful in e-commerce and visual features are more effective in short-video recommendations. Additionally, we explore different integration strategies and model sizes, finding that Ensemble-Based Learning outperforms Fusion-Based Learning, and that larger models do not necessarily deliver better results. To deepen our understanding, we include case studies and review findings from other recommendation domains. Our work provides practical insights for building efficient and effective multimodal recommendation systems, emphasizing the need for thoughtful modality selection, integration strategies, and model design.
Multi-Interest Recommendation: A Survey
Jun 18, 2025Existing recommendation methods often struggle to model users' multifaceted preferences due to the diversity and volatility of user behavior, as well as the inherent uncertainty and ambiguity of item attributes in practical scenarios. Multi-interest recommendation addresses this challenge by extracting multiple interest representations from users' historical interactions, enabling fine-grained preference modeling and more accurate recommendations. It has drawn broad interest in recommendation research. However, current recommendation surveys have either specialized in frontier recommendation methods or delved into specific tasks and downstream applications. In this work, we systematically review the progress, solutions, challenges, and future directions of multi-interest recommendation by answering the following three questions: (1) Why is multi-interest modeling significantly important for recommendation? (2) What aspects are focused on by multi-interest modeling in recommendation? and (3) How can multi-interest modeling be applied, along with the technical details of the representative modules? We hope that this survey establishes a fundamental framework and delivers a preliminary overview for researchers interested in this field and committed to further exploration. The implementation of multi-interest recommendation summarized in this survey is maintained at https://github.com/WHUIR/Multi-Interest-Recommendation-A-Survey.
Towards Storage-Efficient Visual Document Retrieval: An Empirical Study on Reducing Patch-Level Embeddings
Jun 05, 2025Despite the strong performance of ColPali/ColQwen2 in Visualized Document Retrieval (VDR), it encodes each page into multiple patch-level embeddings and leads to excessive memory usage. This empirical study investigates methods to reduce patch embeddings per page at minimum performance degradation. We evaluate two token-reduction strategies: token pruning and token merging. Regarding token pruning, we surprisingly observe that a simple random strategy outperforms other sophisticated pruning methods, though still far from satisfactory. Further analysis reveals that pruning is inherently unsuitable for VDR as it requires removing certain page embeddings without query-specific information. Turning to token merging (more suitable for VDR), we search for the optimal combinations of merging strategy across three dimensions and develop Light-ColPali/ColQwen2. It maintains 98.2% of retrieval performance with only 11.8% of original memory usage, and preserves 94.6% effectiveness at 2.8% memory footprint. We expect our empirical findings and resulting Light-ColPali/ColQwen2 offer valuable insights and establish a competitive baseline for future research towards efficient VDR.