 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Stage Field Extraction of Financial Documents with OCR and Compact Vision-Language Models
Oct 27, 2025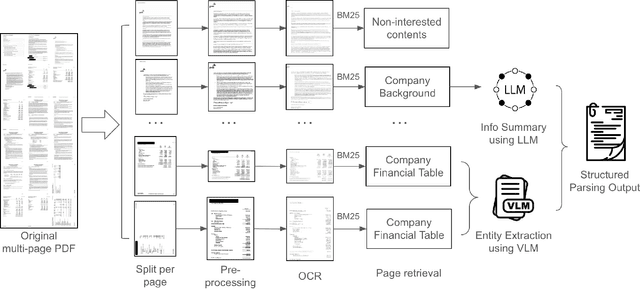
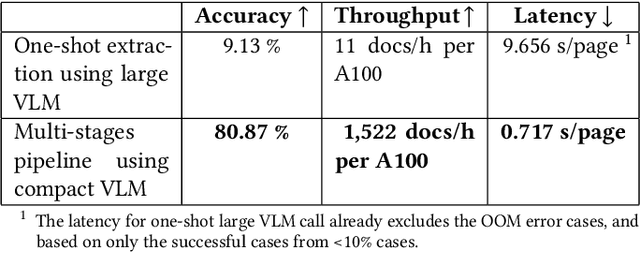


Financial documents are essential sources of information for regulators, auditors, and financial institutions, particularly for assessing the wealth and compliance of Small and Medium-sized Businesses. However, SMB documents are often difficult to parse. They are rarely born digital and instead are distributed as scanned images that are none machine readable. The scans themselves are low in resolution, affected by skew or rotation, and often contain noisy backgrounds. These documents also tend to be heterogeneous, mixing narratives, tables, figures, and multilingual content within the same report. Such characteristics pose major challenges for automated information extraction, especially when relying on end to end large Vision Language Models, which are computationally expensive, sensitive to noise, and slow when applied to files with hundreds of pages. We propose a multistage pipeline that leverages traditional image processing models and OCR extraction, together with compact VLMs for structured field extraction of large-scale financial documents. Our approach begins with image pre-processing, including segmentation, orientation detection, and size normalization. Multilingual OCR is then applied to recover page-level text. Upon analyzing the text information, pages are retrieved for coherent sections. Finally, compact VLMs are operated within these narrowed-down scopes to extract structured financial indicators. Our approach is evaluated using an internal corpus of multi-lingual, scanned financial documents. The results demonstrate that compact VLMs, together with a multistage pipeline, achieves 8.8 times higher field level accuracy relative to directly feeding the whole document into large VLMs, only at 0.7 percent of the GPU cost and 92.6 percent less end-to-end service latency.
Evaluating LLM Adaptation to Sociodemographic Factors: User Profile vs. Dialogue History
May 27, 2025
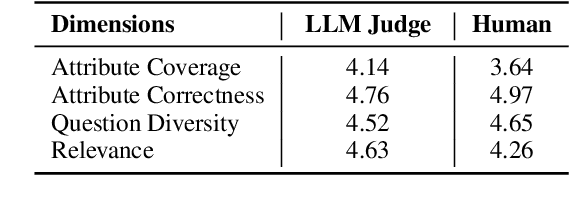

Effective engagement by large language models (LLMs) requires adapting responses to users' sociodemographic characteristics, such as age, occupation, and education level. While many real-world applications leverage dialogue history for contextualization, existing evaluations of LLMs' behavioral adaptation often focus on single-turn prompts. In this paper, we propose a framework to evaluate LLM adaptation when attributes are introduced either (1) explicitly via user profiles in the prompt or (2) implicitly through multi-turn dialogue history. We assess the consistency of model behavior across these modalities. Using a multi-agent pipeline, we construct a synthetic dataset pairing dialogue histories with distinct user profiles and employ questions from the Value Survey Module (VSM 2013) (Hofstede and Hofstede, 2016) to probe value expression. Our findings indicate that most models adjust their expressed values in response to demographic changes, particularly in age and education level, but consistency varies. Models with stronger reasoning capabilities demonstrate greater alignment, indicating the importance of reasoning in robust sociodemographic adaptation.
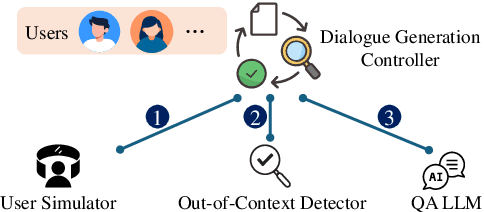
RAGulator: Lightweight Out-of-Context Detectors for Grounded Text Generation
Nov 06, 2024Real-time detection of out-of-context LLM outputs is crucial for enterprises looking to safely adopt RAG applications. In this work, we train lightweight models to discriminate LLM-generated text that is semantically out-of-context from retrieved text documents. We preprocess a combination of summarisation and semantic textual similarity datasets to construct training data using minimal resources. We find that DeBERTa is not only the best-performing model under this pipeline, but it is also fast and does not require additional text preprocessing or feature engineering. While emerging work demonstrates that generative LLMs can also be fine-tuned and used in complex data pipelines to achieve state-of-the-art performance, we note that speed and resource limits are important considerations for on-premise deployment.