 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVIR: Adaptive Visual In-Document Retrieval for Efficient Multi-Page Document Question Answering
Jan 17, 2026Multi-page Document Visual Question Answering (MP-DocVQA) remains challenging because long documents not only strain computational resources but also reduce the effectiveness of the attention mechanism in large vision-language models (LVLMs). We tackle these issues with an Adaptive Visual In-document Retrieval (AVIR) framework. A lightweight retrieval model first scores each page for question relevance. Pages are then clustered according to the score distribution to adaptively select relevant content. The clustered pages are screened again by Top-K to keep the context compact. However, for short documents, clustering reliability decreases, so we use a relevance probability threshold to select pages. The selected pages alone are fed to a frozen LVLM for answer generation, eliminating the need for model fine-tuning. The proposed AVIR framework reduces the average page count required for question answering by 70%, while achieving an ANLS of 84.58% on the MP-DocVQA dataset-surpassing previous methods with significantly lower computational cost. The effectiveness of the proposed AVIR is also verified on the SlideVQA and DUDE benchmarks. The code is available at https://github.com/Li-yachuan/AVIR.
Evaluating LLM Adaptation to Sociodemographic Factors: User Profile vs. Dialogue History
May 27, 2025
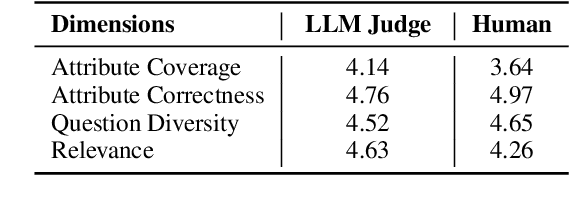
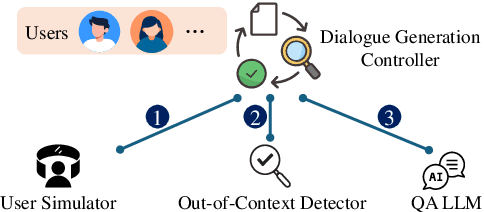

Effective engagement by large language models (LLMs) requires adapting responses to users' sociodemographic characteristics, such as age, occupation, and education level. While many real-world applications leverage dialogue history for contextualization, existing evaluations of LLMs' behavioral adaptation often focus on single-turn prompts. In this paper, we propose a framework to evaluate LLM adaptation when attributes are introduced either (1) explicitly via user profiles in the prompt or (2) implicitly through multi-turn dialogue history. We assess the consistency of model behavior across these modalities. Using a multi-agent pipeline, we construct a synthetic dataset pairing dialogue histories with distinct user profiles and employ questions from the Value Survey Module (VSM 2013) (Hofstede and Hofstede, 2016) to probe value expression. Our findings indicate that most models adjust their expressed values in response to demographic changes, particularly in age and education level, but consistency varies. Models with stronger reasoning capabilities demonstrate greater alignment, indicating the importance of reasoning in robust sociodemographic adaptation.
EDMB: Edge Detector with Mamba
Jan 08, 2025Transformer-based models have made significant progress in edge detection, but their high computational cost is prohibitive. Recently, vision Mamba have shown excellent ability in efficiently capturing long-range dependencies. Drawing inspiration from this, we propose a novel edge detector with Mamba, termed EDMB, to efficiently generate high-quality multi-granularity edges. In EDMB, Mamba is combined with a global-local architecture, therefore it can focus on both global information and fine-grained cues. The fine-grained cues play a crucial role in edge detection, but are usually ignored by ordinary Mamba. We design a novel decoder to construct learnable Gaussian distributions by fusing global features and fine-grained features. And the multi-grained edges are generated by sampling from the distributions. In order to make multi-granularity edges applicable to single-label data, we introduce Evidence Lower Bound loss to supervise the learning of the distributions. On the multi-label dataset BSDS500, our proposed EDMB achieves competitive single-granularity ODS 0.837 and multi-granularity ODS 0.851 without multi-scale test or extra PASCAL-VOC data. Remarkably, EDMB can be extended to single-label datasets such as NYUDv2 and BIPED. The source code is available at https://github.com/Li-yachuan/EDMB.
DDRN:a Data Distribution Reconstruction Network for Occluded Person Re-Identification
Oct 09, 2024



In occluded person re-identification(ReID), severe occlusions lead to a significant amount of irrelevant information that hinders the accurate identification of individuals. These irrelevant cues primarily stem from background interference and occluding interference, adversely affecting the final retrieval results. Traditional discriminative models, which rely on the specific content and positions of the images, often misclassify in cases of occlusion. To address these limitations, we propose the Data Distribution Reconstruction Network (DDRN), a generative model that leverages data distribution to filter out irrelevant details, enhancing overall feature perception ability and reducing irrelevant feature interference. Additionally, severe occlusions lead to the complexity of the feature space. To effectively handle this, we design a multi-center approach through the proposed Hierarchical SubcenterArcface (HS-Arcface) loss function, which can better approximate complex feature spaces. On the Occluded-Duke dataset, we achieved a mAP of 62.4\% (+1.1\%) and a rank-1 accuracy of 71.3\% (+0.6\%), surpassing the latest state-of-the-art methods(FRT) significantly.
Compact Twice Fusion Network for Edge Detection
Jul 11, 2023The significance of multi-scale features has been gradually recognized by the edge detection community. However, the fusion of multi-scale features increases the complexity of the model, which is not friendly to practical application. In this work, we propose a Compact Twice Fusion Network (CTFN) to fully integrate multi-scale features while maintaining the compactness of the model. CTFN includes two lightweight multi-scale feature fusion modules: a Semantic Enhancement Module (SEM) that can utilize the semantic information contained in coarse-scale features to guide the learning of fine-scale features, and a Pseudo Pixel-level Weighting (PPW) module that aggregate the complementary merits of multi-scale features by assigning weights to all features. Notwithstanding all this, the interference of texture noise makes the correct classification of some pixels still a challenge. For these hard samples, we propose a novel loss function, coined Dynamic Focal Loss, which reshapes the standard cross-entropy loss and dynamically adjusts the weights to correct the distribution of hard samples. We evaluate our method on three datasets, i.e., BSDS500, NYUDv2, and BIPEDv2. Compared with state-of-the-art methods, CTFN achieves competitive accuracy with less parameters and computational cost. Apart from the backbone, CTFN requires only 0.1M additional parameters, which reduces its computation cost to just 60% of other state-of-the-art methods. The codes are available at https://github.com/Li-yachuan/CTFN-pytorch-master.
Unsupervised Representation Learning with Laplacian Pyramid Auto-encoders
May 12, 2018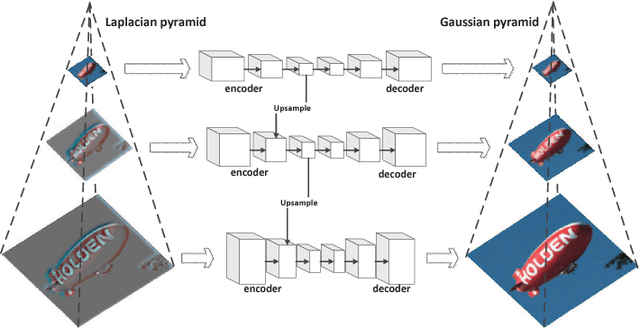
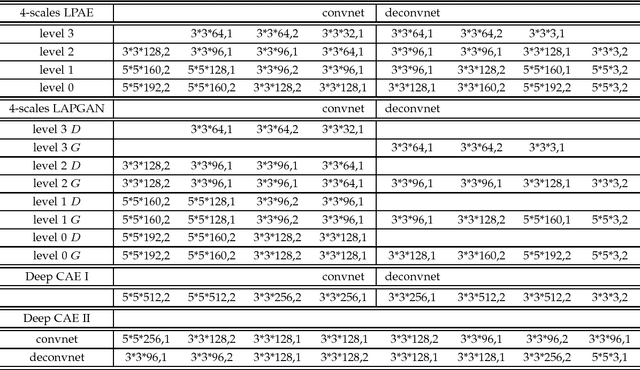
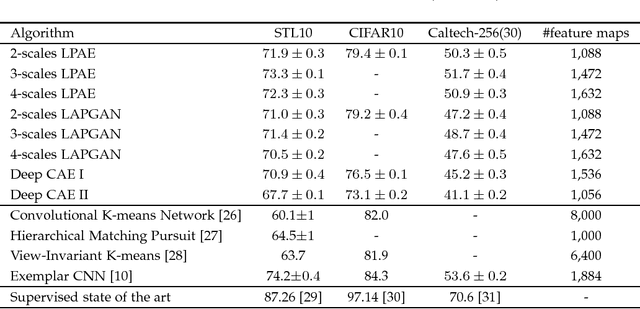

Scale-space representation has been popular in computer vision community due to its theoretical foundation. The motivation for generating a scale-space representation of a given data set originates from the basic observation that real-world objects are composed of different structures at different scales. Hence, it's reasonable to consider learning features with image pyramids generated by smoothing and down-sampling operations. In this paper we propose Laplacian pyramid auto-encoders, a straightforward modification of the deep convolutional auto-encoder architecture, for unsupervised representation learning. The method uses multiple encoding-decoding sub-networks within a Laplacian pyramid framework to reconstruct the original image and the low pass filtered images. The last layer of each encoding sub-network also connects to an encoding layer of the sub-network in the next level, which aims to reverse the process of Laplacian pyramid generation. Experimental results showed that Laplacian pyramid benefited the classification and reconstruction performance of deep auto-encoder approaches, and batch normalization is critical to get deep auto-encoders approaches to begin learning.
Unsupervised domain adaption dictionary learning for visual recognition
Jun 03, 2015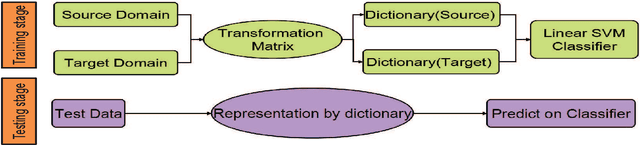
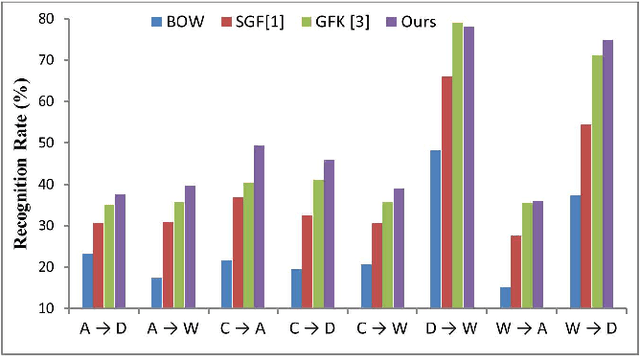
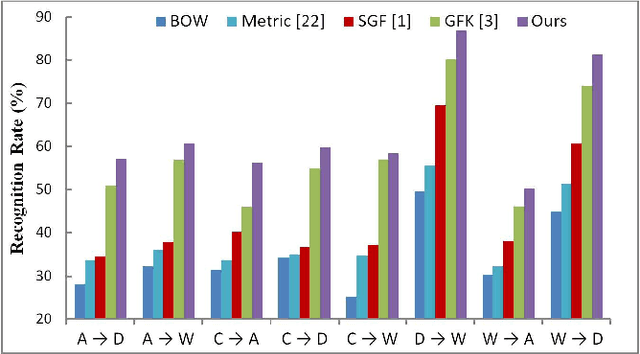
Over the last years, dictionary learning method has been extensively applied to deal with various computer vision recognition applications, and produced state-of-the-art results. However, when the data instances of a target domain have a different distribution than that of a source domain, the dictionary learning method may fail to perform well. In this paper, we address the cross-domain visual recognition problem and propose a simple but effective unsupervised domain adaption approach, where labeled data are only from source domain. In order to bring the original data in source and target domain into the same distribution, the proposed method forcing nearest coupled data between source and target domain to have identical sparse representations while jointly learning dictionaries for each domain, where the learned dictionaries can reconstruct original data in source and target domain respectively. So that sparse representations of original data can be used to perform visual recognition tasks. We demonstrate the effectiveness of our approach on standard datasets. Our method performs on par or better than competitive state-of-the-art methods.