 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDMB: Edge Detector with Mamba
Jan 08, 2025Transformer-based models have made significant progress in edge detection, but their high computational cost is prohibitive. Recently, vision Mamba have shown excellent ability in efficiently capturing long-range dependencies. Drawing inspiration from this, we propose a novel edge detector with Mamba, termed EDMB, to efficiently generate high-quality multi-granularity edges. In EDMB, Mamba is combined with a global-local architecture, therefore it can focus on both global information and fine-grained cues. The fine-grained cues play a crucial role in edge detection, but are usually ignored by ordinary Mamba. We design a novel decoder to construct learnable Gaussian distributions by fusing global features and fine-grained features. And the multi-grained edges are generated by sampling from the distributions. In order to make multi-granularity edges applicable to single-label data, we introduce Evidence Lower Bound loss to supervise the learning of the distributions. On the multi-label dataset BSDS500, our proposed EDMB achieves competitive single-granularity ODS 0.837 and multi-granularity ODS 0.851 without multi-scale test or extra PASCAL-VOC data. Remarkably, EDMB can be extended to single-label datasets such as NYUDv2 and BIPED. The source code is available at https://github.com/Li-yachuan/EDMB.
Investigation of the Impact of Economic and Social Factors on Energy Demand through Natural Language Processing
Jun 09, 2024The relationship between energy demand and variables such as economic activity and weather is well established. However, this paper aims to explore the connection between energy demand and other social aspects, which receive little attention. Through the use of natural language processing on a large news corpus, we shed light on this important link. This study was carried out in five regions of the UK and Ireland and considers multiple horizons from 1 to 30 days. It also considers economic variables such as GDP, unemployment and inflation. We found that: 1) News about military conflicts, transportation, the global pandemic, regional economics, and the international energy market are related to electricity demand. 2) Economic indicators are more important in the East Midlands and Northern Ireland, while social indicators are more useful in the West Midlands and the South West of England. 3) The use of these indices improved forecasting performance by up to 9%.
MapTrack: Tracking in the Map
Feb 20, 2024
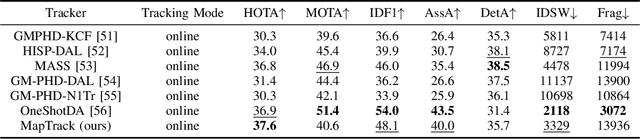


Multi-Object Tracking (MOT) aims to maintain stable and uninterrupted trajectories for each target. Most state-of-the-art approaches first detect objects in each frame and then implement data association between new detections and existing tracks using motion models and appearance similarities. Despite achieving satisfactory results, occlusion and crowds can easily lead to missing and distorted detections, followed by missing and false associations. In this paper, we first revisit the classic tracker DeepSORT, enhancing its robustness over crowds and occlusion significantly by placing greater trust in predictions when detections are unavailable or of low quality in crowded and occluded scenes. Specifically, we propose a new framework comprising of three lightweight and plug-and-play algorithms: the probability map, the prediction map, and the covariance adaptive Kalman filter. The probability map identifies whether undetected objects have genuinely disappeared from view (e.g., out of the image or entered a building) or are only temporarily undetected due to occlusion or other reasons. Trajectories of undetected targets that are still within the probability map are extended by state estimations directly. The prediction map determines whether an object is in a crowd, and we prioritize state estimations over observations when severe deformation of observations occurs, accomplished through the covariance adaptive Kalman filter. The proposed method, named MapTrack, achieves state-of-the-art results on popular multi-object tracking benchmarks such as MOT17 and MOT20. Despite its superior performance, our method remains simple, online, and real-time. The code will be open-sourced later.
Electricity Demand Forecasting through Natural Language Processing with Long Short-Term Memory Networks
Sep 13, 2023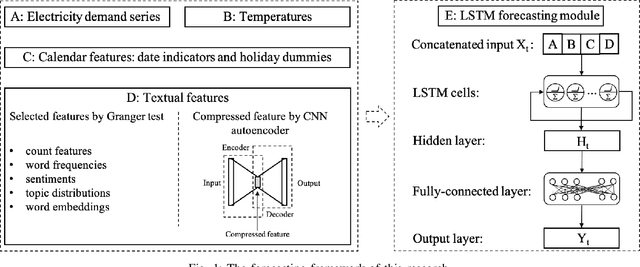
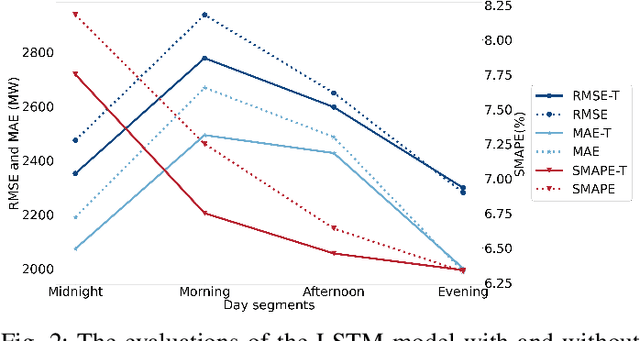
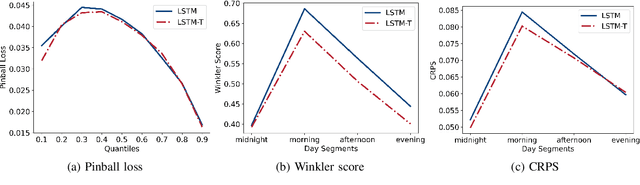
Electricity demand forecasting is a well established research field. Usually this task is performed considering historical loads, weather forecasts, calendar information and known major events. Recently attention has been given on the possible use of new sources of information from textual news in order to improve the performance of these predictions. This paper proposes a Long and Short-Term Memory (LSTM) network incorporating textual news features that successfully predicts the deterministic and probabilistic tasks of the UK national electricity demand. The study finds that public sentiment and word vector representations related to transport and geopolitics have time-continuity effects on electricity demand. The experimental results show that the LSTM with textual features improves by more than 3% compared to the pure LSTM benchmark and by close to 10% over the official benchmark. Furthermore, the proposed model effectively reduces forecasting uncertainty by narrowing the confidence interval and bringing the forecast distribution closer to the truth.
Compact Twice Fusion Network for Edge Detection
Jul 11, 2023The significance of multi-scale features has been gradually recognized by the edge detection community. However, the fusion of multi-scale features increases the complexity of the model, which is not friendly to practical application. In this work, we propose a Compact Twice Fusion Network (CTFN) to fully integrate multi-scale features while maintaining the compactness of the model. CTFN includes two lightweight multi-scale feature fusion modules: a Semantic Enhancement Module (SEM) that can utilize the semantic information contained in coarse-scale features to guide the learning of fine-scale features, and a Pseudo Pixel-level Weighting (PPW) module that aggregate the complementary merits of multi-scale features by assigning weights to all features. Notwithstanding all this, the interference of texture noise makes the correct classification of some pixels still a challenge. For these hard samples, we propose a novel loss function, coined Dynamic Focal Loss, which reshapes the standard cross-entropy loss and dynamically adjusts the weights to correct the distribution of hard samples. We evaluate our method on three datasets, i.e., BSDS500, NYUDv2, and BIPEDv2. Compared with state-of-the-art methods, CTFN achieves competitive accuracy with less parameters and computational cost. Apart from the backbone, CTFN requires only 0.1M additional parameters, which reduces its computation cost to just 60% of other state-of-the-art methods. The codes are available at https://github.com/Li-yachuan/CTFN-pytorch-master.
A Quantitative Exploration of Natural Language Processing Applications for Electricity Demand Analysis
Jan 18, 2023The relationship between electricity demand and weather has been established for a long time and is one of the cornerstones in load prediction for operation and planning, along with behavioral and social aspects such as calendars or significant events. This paper explores how and why the social information contained in the news can be used better to understand aggregate population behaviour in terms of energy demand. The work is done through experiments analysing the impact of predicting features extracted from national news on day-ahead electric demand prediction. The results are compared to a benchmark model trained exclusively on the calendar and meteorological information. Experimental results showed that the best-performing model reduced the official standard errors around 4%, 11%, and 10% in terms of RMSE, MAE, and SMAPE. The best-performing methods are: word frequency identified COVID-19-related keywords; topic distribution that identified news on the pandemic and internal politics; global word embeddings that identified news about international conflicts. This study brings a new perspective to traditional electricity demand analysis and confirms the feasibility of improving its predictions with unstructured information contained in texts, with potential consequences in sociology and economics.
Enhancing the Diversity of Predictions Combination by Negative Correlation Learning
Apr 06, 2021

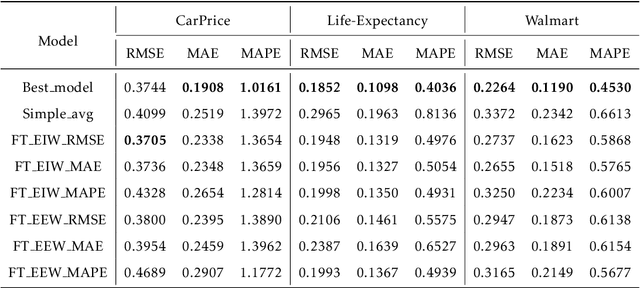
Predictions combination, as a combination model approach with adjustments in the output space, has flourished in recent years in research and competitions. Simple average is intuitive and robust, and is often used as a benchmark in predictions combination. However, some poorly performing sub-models can reduce the overall accuracy because the sub-models are not selected in advance. Even though some studies have selected the top sub-models for the combination after ranking them by mean square error, the covariance of them causes this approach to not yield much benefit. In this paper, we suggest to consider the diversity of sub-models in the predictions combination, which can be adopted to assist in selecting the most diverse model subset in the model pool using negative correlation learning. Three publicly available datasets are applied to evaluate the approach. The experimental results not only show the diversity of sub-models in the predictions combination incorporating negative correlation learning, but also produce predictions with accuracy far exceeding that of the simple average benchmark and some weighted average methods. Furthermore, by adjusting the penalty strength for negative correlation, the predictions combination also outperform the best sub-model. The value of this paper lies in its ease of use and effectiveness, allowing the predictions combination to embrace both diversity and accuracy.
Exploring the social influence of Kaggle virtual community on the M5 competition
Feb 28, 2021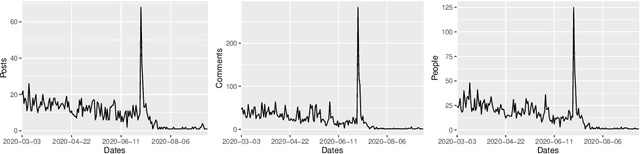
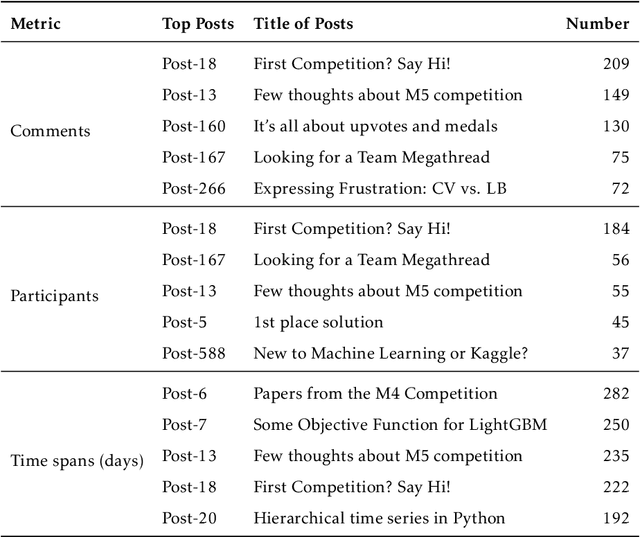
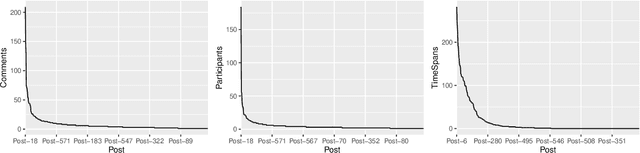

One of the most significant differences of M5 over previous forecasting competitions is that it was held on Kaggle, an online community of data scientists and machine learning practitioners. On the Kaggle platform, people can form virtual communities such as online notebooks and discussions to discuss their models, choice of features, loss functions, etc. This paper aims to study the social influence of virtual communities on the competition. We first study the content of the M5 virtual community by topic modeling and trend analysis. Further, we perform social media analysis to identify the potential relationship network of the virtual community. We find some key roles in the network and study their roles in spreading the LightGBM related information within the network. Overall, this study provides in-depth insights into the dynamic mechanism of the virtual community influence on the participants and has potential implications for future online competitions.
Research and application of time series algorithms in centralized purchasing data
Nov 01, 2019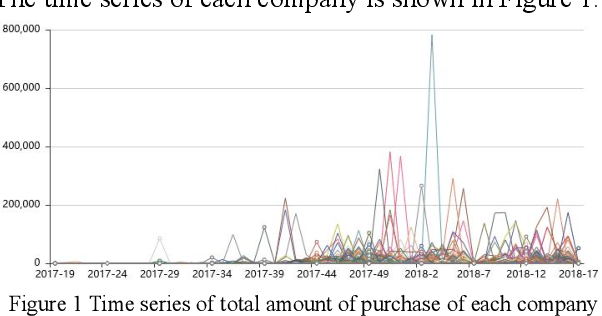
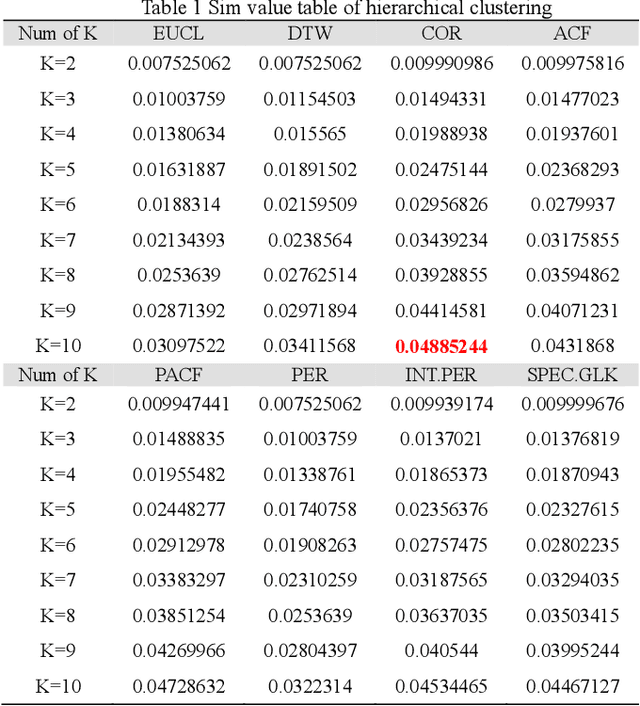
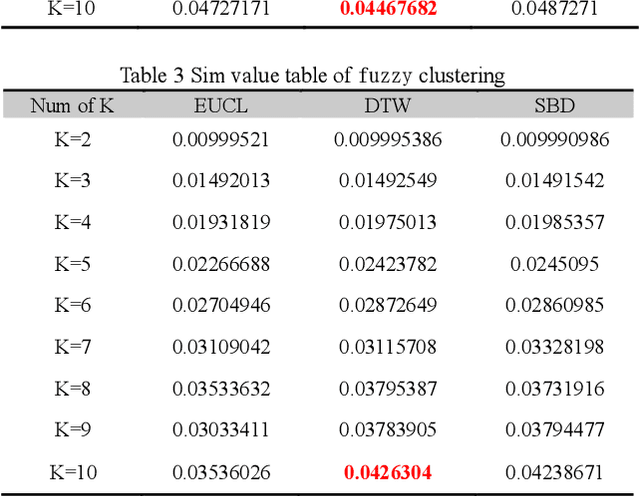
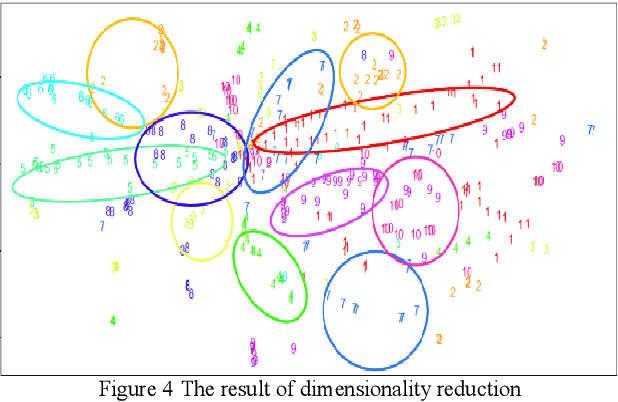
Based on the online transaction data of COSCO group's centralized procurement platform, this paper studies the clustering method of time series type data. The different methods of similarity calculation, different clustering methods with different K values are analysed, and the best clustering method suitable for centralized purchasing data is determined. The company list under the corresponding cluster is obtained. The time series motif discovery algorithm is used to model the centroid of each cluster. Through ARIMA method, we also made 12 periods of prediction for the centroid of each category. This paper constructs a matrix of "Customer Lifecycle Theory - Five Elements of Marketing ", and puts forward corresponding marketing suggestions for customers at different life cycle stages.
Loop Restricted Existential Rules and First-order Rewritability for Query Answering
Aug 02, 2018In ontology-based data access (OBDA), the classical database is enhanced with an ontology in the form of logical assertions generating new intensional knowledge. A powerful form of such logical assertions is the tuple-generating dependencies (TGDs), also called existential rules, where Horn rules are extended by allowing existential quantifiers to appear in the rule heads. In this paper we introduce a new language called loop restricted (LR) TGDs (existential rules), which are TGDs with certain restrictions on the loops embedded in the underlying rule set. We study the complexity of this new language. We show that the conjunctive query answering (CQA) under the LR TGDs is decid- able. In particular, we prove that this language satisfies the so-called bounded derivation-depth prop- erty (BDDP), which implies that the CQA is first-order rewritable, and its data complexity is in AC0 . We also prove that the combined complexity of the CQA is EXPTIME complete, while the language membership is PSPACE complete. Then we extend the LR TGDs language to the generalised loop restricted (GLR) TGDs language, and prove that this class of TGDs still remains to be first-order rewritable and properly contains most of other first-order rewritable TGDs classes discovered in the literature so far.