 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Oriented Object Detection Transformer in Remote Sensing Images
Mar 16, 2026Recent real-time detection transformers have gained popularity due to their simplicity and efficiency. However, these detectors do not explicitly model object rotation, especially in remote sensing imagery where objects appear at arbitrary angles, leading to challenges in angle representation, matching cost, and training stability. In this paper, we propose a real-time oriented object detection transformer, the first real-time end-to-end oriented object detector to the best of our knowledge, that addresses the above issues. Specifically, angle distribution refinement is proposed to reformulate angle regression as an iterative refinement of probability distributions, thereby capturing the uncertainty of object rotation and providing a more fine-grained angle representation. Then, we incorporate a Chamfer distance cost into bipartite matching, measuring box distance via vertex sets, enabling more accurate geometric alignment and eliminating ambiguous matches. Moreover, we propose oriented contrastive denoising to stabilize training and analyze four noise modes. We observe that a ground truth can be assigned to different index queries across different decoder layers, and analyze this issue using the proposed instability metric. We design a series of model variants and experiments to validate the proposed method. Notably, our O2-DFINE-L, O2-RTDETR-R50 and O2-DEIM-R50 achieve 77.73%/78.45%/80.15% AP50 on DOTA1.0 and 132/119/119 FPS on the 2080ti GPU. Code is available at https://github.com/wokaikaixinxin/ai4rs.
* IEEE Transactions on Geoscience and Remote Sensing, 2026, doi 10.1109/TGRS.2026.3671683
DeepVARwT: Deep Learning for a VAR Model with Trend
Oct 11, 2022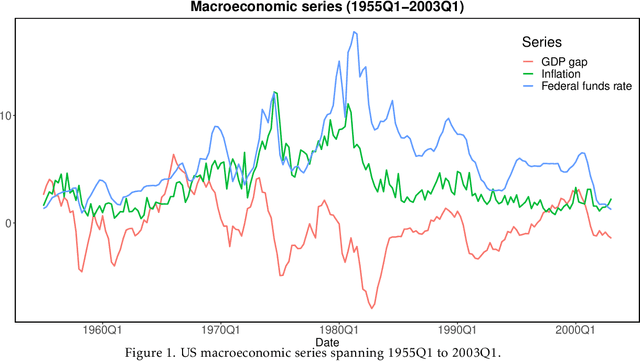
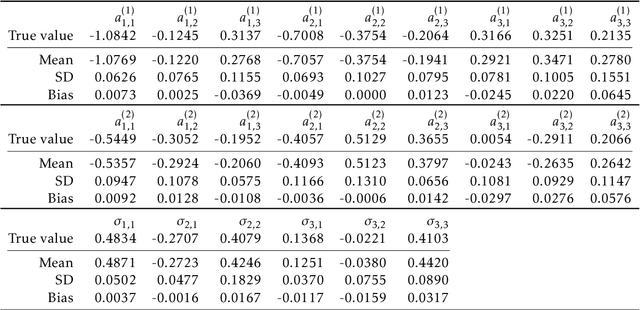
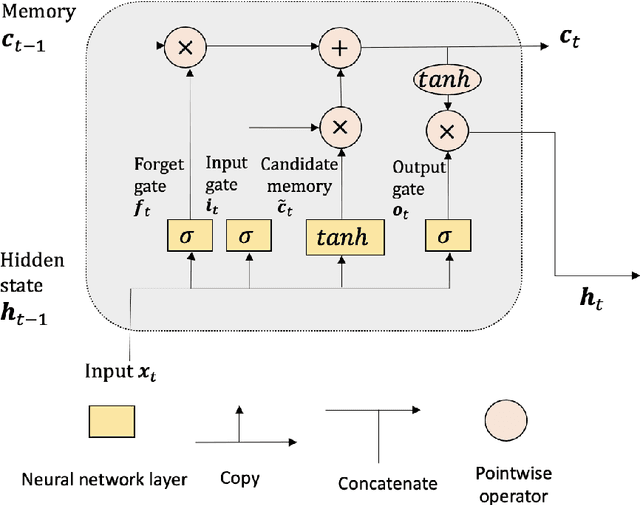

The vector autoregressive (VAR) model has been used to describe the dependence within and across multiple time series. This is a model for stationary time series which can be extended to allow the presence of a deterministic trend in each series. Detrending the data either parametrically or nonparametrically before fitting the VAR model gives rise to more errors in the latter part. In this study, we propose a new approach called DeepVARwT that employs deep learning methodology for maximum likelihood estimation of the trend and the dependence structure at the same time. A Long Short-Term Memory (LSTM) network is used for this purpose. To ensure the stability of the model, we enforce the causality condition on the autoregressive coefficients using the transformation of Ansley & Kohn (1986). We provide a simulation study and an application to real data. In the simulation study, we use realistic trend functions generated from real data and compare the estimates with true function/parameter values. In the real data application, we compare the prediction performance of this model with state-of-the-art models in the literature.
fETSmcs: Feature-based ETS model component selection
Jun 26, 2022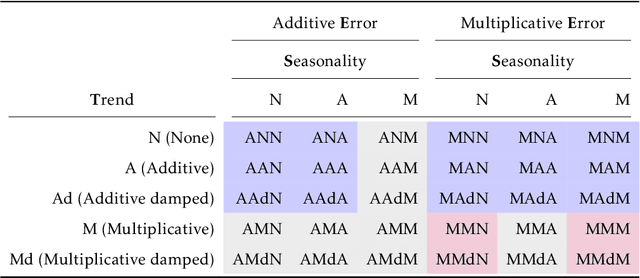
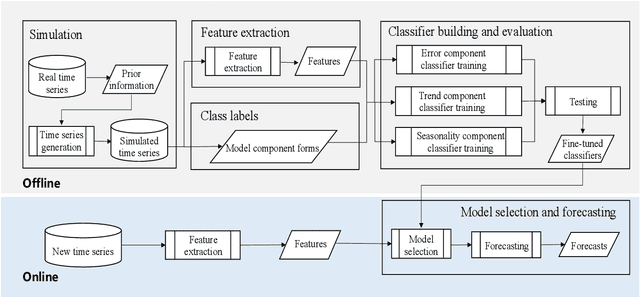

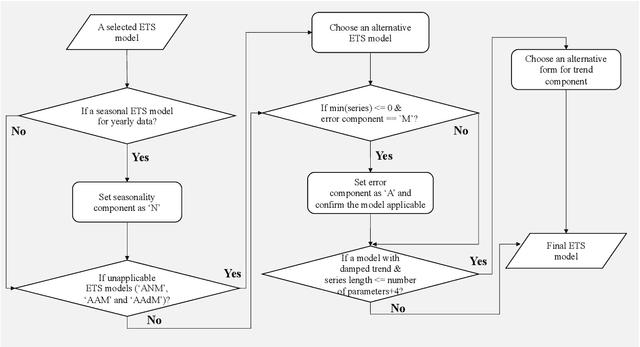
The well-developed ETS (ExponenTial Smoothing or Error, Trend, Seasonality) method incorporating a family of exponential smoothing models in state space representation has been widely used for automatic forecasting. The existing ETS method uses information criteria for model selection by choosing an optimal model with the smallest information criterion among all models fitted to a given time series. The ETS method under such a model selection scheme suffers from computational complexity when applied to large-scale time series data. To tackle this issue, we propose an efficient approach for ETS model selection by training classifiers on simulated data to predict appropriate model component forms for a given time series. We provide a simulation study to show the model selection ability of the proposed approach on simulated data. We evaluate our approach on the widely used forecasting competition data set M4, in terms of both point forecasts and prediction intervals. To demonstrate the practical value of our method, we showcase the performance improvements from our approach on a monthly hospital data set.
Exploring the social influence of Kaggle virtual community on the M5 competition
Feb 28, 2021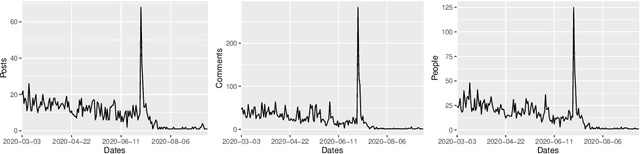
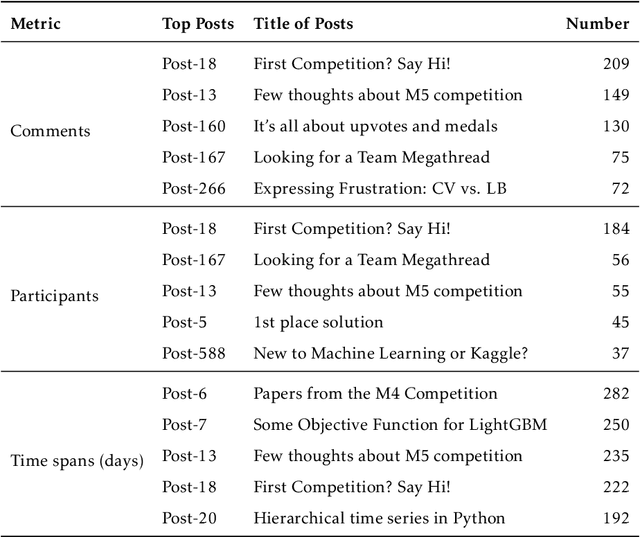
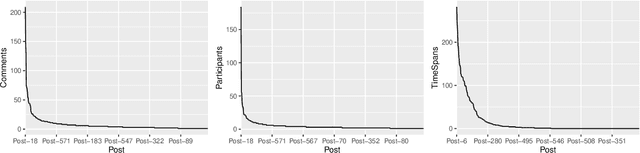

One of the most significant differences of M5 over previous forecasting competitions is that it was held on Kaggle, an online community of data scientists and machine learning practitioners. On the Kaggle platform, people can form virtual communities such as online notebooks and discussions to discuss their models, choice of features, loss functions, etc. This paper aims to study the social influence of virtual communities on the competition. We first study the content of the M5 virtual community by topic modeling and trend analysis. Further, we perform social media analysis to identify the potential relationship network of the virtual community. We find some key roles in the network and study their roles in spreading the LightGBM related information within the network. Overall, this study provides in-depth insights into the dynamic mechanism of the virtual community influence on the participants and has potential implications for future online competitions.
Research and application of time series algorithms in centralized purchasing data
Nov 01, 2019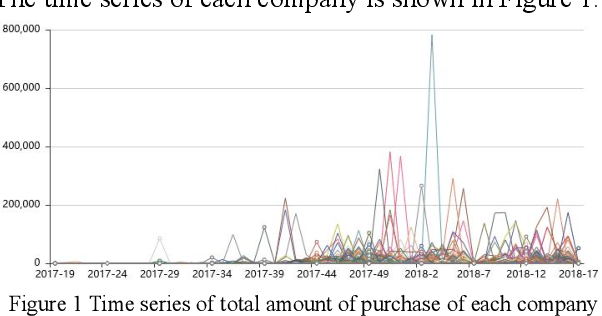
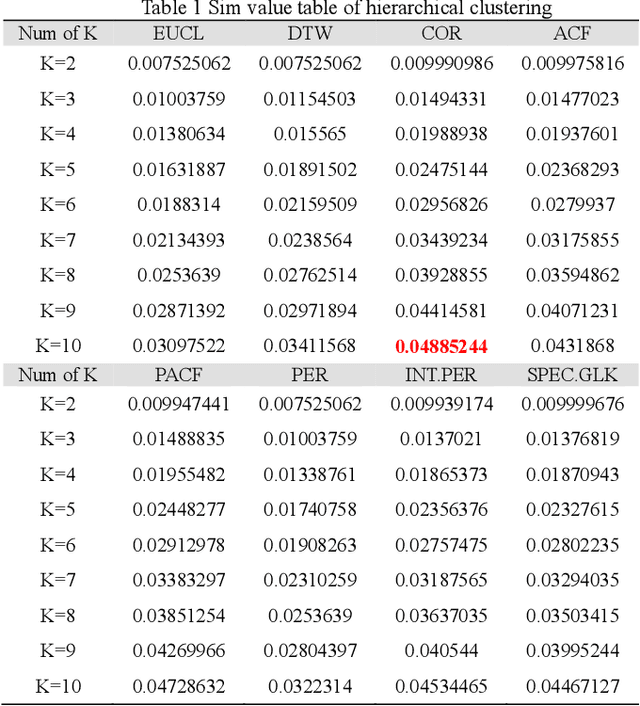
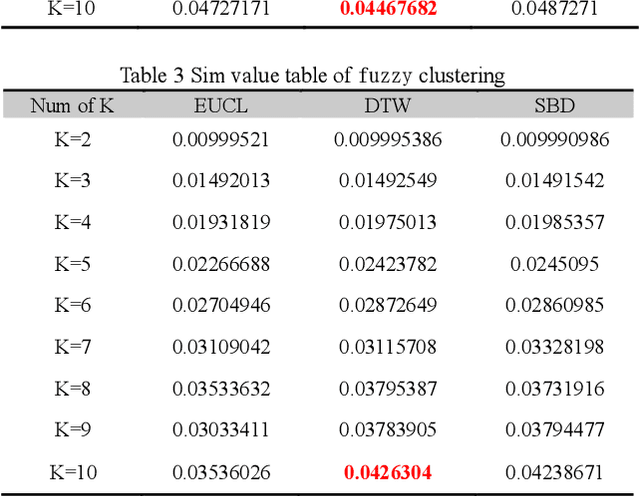
Based on the online transaction data of COSCO group's centralized procurement platform, this paper studies the clustering method of time series type data. The different methods of similarity calculation, different clustering methods with different K values are analysed, and the best clustering method suitable for centralized purchasing data is determined. The company list under the corresponding cluster is obtained. The time series motif discovery algorithm is used to model the centroid of each cluster. Through ARIMA method, we also made 12 periods of prediction for the centroid of each category. This paper constructs a matrix of "Customer Lifecycle Theory - Five Elements of Marketing ", and puts forward corresponding marketing suggestions for customers at different life cycle stages.
Forecasting with time series imaging
Apr 17, 2019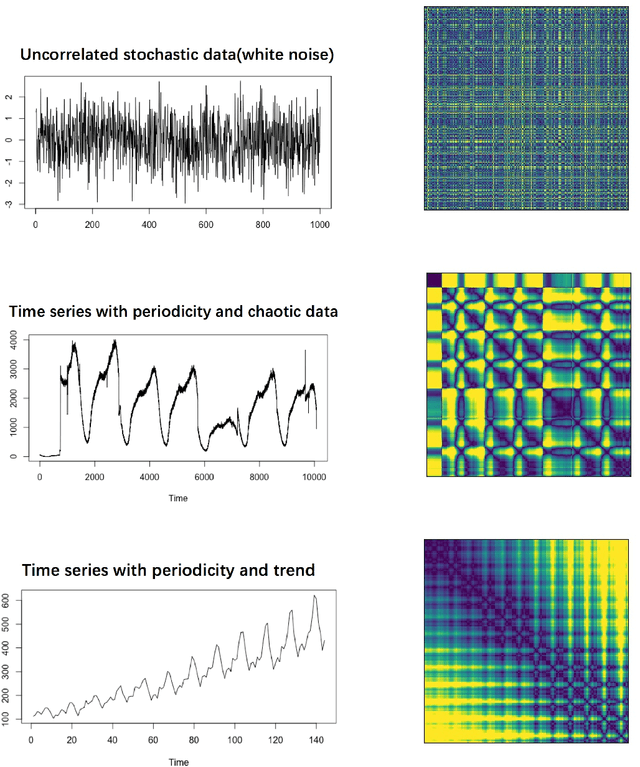
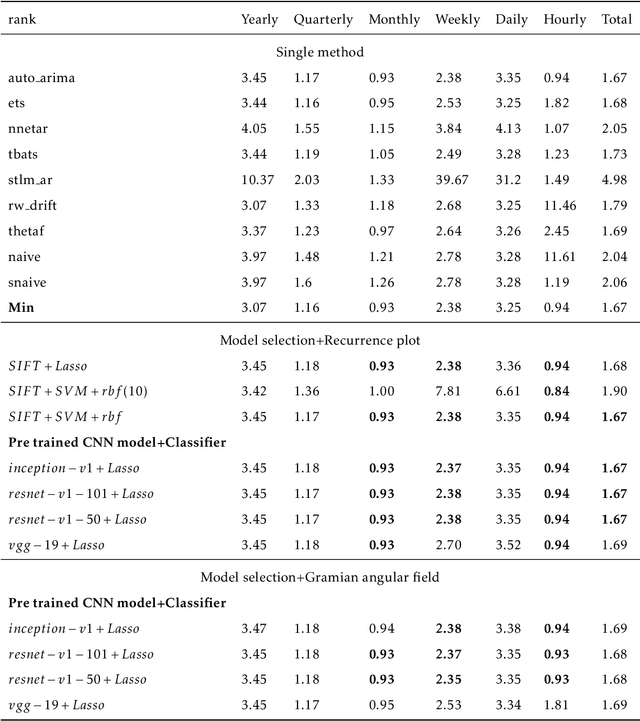
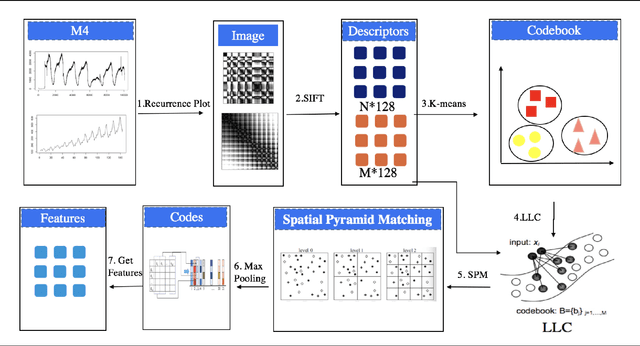
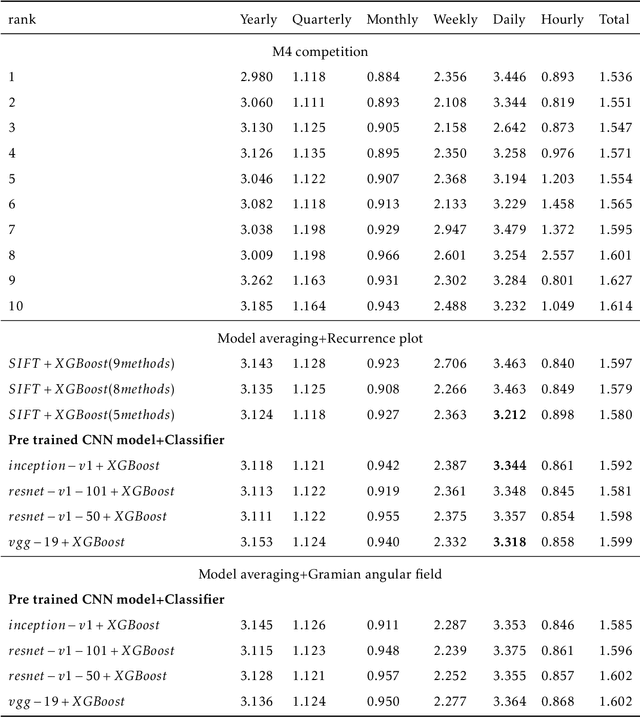
Feature-based time series representation has attracted substantial attention in a wide range of time series analysis methods. Recently, the use of time series features for forecast model selection and model averaging has been an emerging research focus in the forecasting community. Nonetheless, most of the existing approaches depend on the manual choice of an appropriate set of features. Exploiting machine learning methods to automatically extract features from time series becomes crucially important in the state-of-the-art time series analysis. In this paper, we introduce an automated approach to extract time series features based on images. Time series are first transformed into recurrence images, from which local features can be extracted using computer vision algorithms. The extracted features are used for forecast model selection and model averaging. Our experiments show that forecasting based on automatically extracted features, with less human intervention and a more comprehensive view of the raw time series data, yields comparable performances with the top best methods proposed in the largest forecasting competition M4.