 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Draft and Verify: A Self-Verifying Framework for Vision-Language-Action Model
Mar 18, 2026Vision-Language-Action (VLA) models have recently demonstrated strong performance across embodied tasks. Modern VLAs commonly employ diffusion action experts to efficiently generate high-precision continuous action chunks, while auto-regressive generation can be slower and less accurate at low-level control. Yet auto-regressive paradigms still provide complementary priors that can improve robustness and generalization in out-of-distribution environments. To leverage both paradigms, we propose Action-Draft-and-Verify (ADV): diffusion action expert drafts multiple candidate action chunks, and the VLM selects one by scoring all candidates in a single forward pass with a perplexity-style metric. Under matched backbones, training data, and action-chunk length, ADV improves success rate by +4.3 points in simulation and +19.7 points in real-world over diffusion-based baseline, with a single-pass VLM reranking overhead.
ReLAM: Learning Anticipation Model for Rewarding Visual Robotic Manipulation
Sep 26, 2025Reward design remains a critical bottleneck in visual reinforcement learning (RL) for robotic manipulation. In simulated environments, rewards are conventionally designed based on the distance to a target position. However, such precise positional information is often unavailable in real-world visual settings due to sensory and perceptual limitations. In this study, we propose a method that implicitly infers spatial distances through keypoints extracted from images. Building on this, we introduce Reward Learning with Anticipation Model (ReLAM), a novel framework that automatically generates dense, structured rewards from action-free video demonstrations. ReLAM first learns an anticipation model that serves as a planner and proposes intermediate keypoint-based subgoals on the optimal path to the final goal, creating a structured learning curriculum directly aligned with the task's geometric objectives. Based on the anticipated subgoals, a continuous reward signal is provided to train a low-level, goal-conditioned policy under the hierarchical reinforcement learning (HRL) framework with provable sub-optimality bound. Extensive experiments on complex, long-horizon manipulation tasks show that ReLAM significantly accelerates learning and achieves superior performance compared to state-of-the-art methods.
Aligning Sentence Simplification with ESL Learner's Proficiency for Language Acquisition
Feb 17, 2025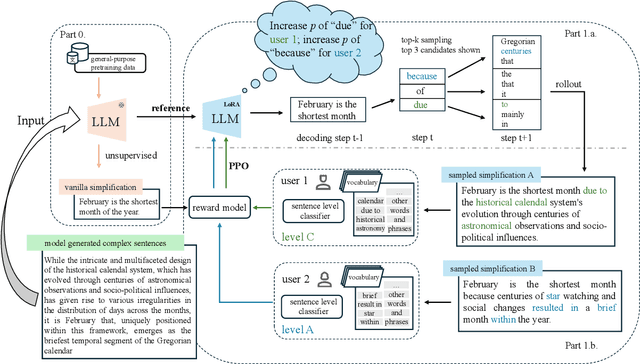
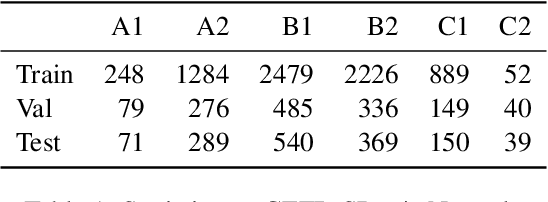
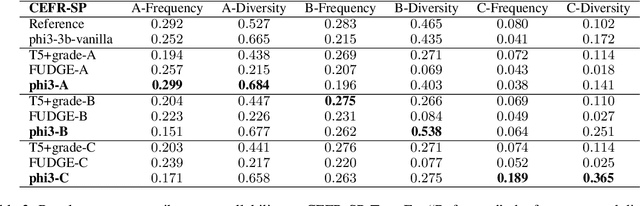
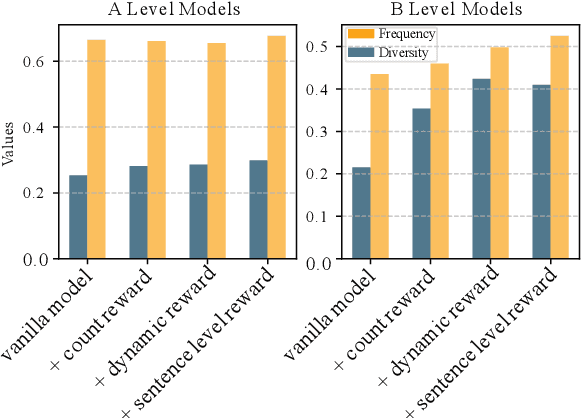
Text simplification is crucial for improving accessibility and comprehension for English as a Second Language (ESL) learners. This study goes a step further and aims to facilitate ESL learners' language acquisition by simplification. Specifically, we propose simplifying complex sentences to appropriate levels for learners while also increasing vocabulary coverage of the target level in the simplifications. We achieve this without a parallel corpus by conducting reinforcement learning on a large language model. Our method employs token-level and sentence-level rewards, and iteratively trains the model on its self-generated outputs to guide the model to search for simplification hypotheses that satisfy the target attributes. Experiment results on CEFR-SP and TurkCorpus datasets show that the proposed method can effectively increase the frequency and diversity of vocabulary of the target level by more than $20\%$ compared to baseline models, while maintaining high simplification quality.
Picky LLMs and Unreliable RMs: An Empirical Study on Safety Alignment after Instruction Tuning
Feb 03, 2025Large language models (LLMs) have emerged as powerful tools for addressing a wide range of general inquiries and tasks. Despite this, fine-tuning aligned LLMs on smaller, domain-specific datasets, critical to adapting them to specialized tasks, can inadvertently degrade their safety alignment, even when the datasets are benign. This phenomenon makes models more susceptible to providing inappropriate responses. In this study, we systematically examine the factors contributing to safety alignment degradation in benign fine-tuning scenarios. Our analysis identifies three critical factors affecting aligned LLMs: answer structure, identity calibration, and role-play. Additionally, we evaluate the reliability of state-of-the-art reward models (RMs), which are often used to guide alignment processes. Our findings reveal that these RMs frequently fail to accurately reflect human preferences regarding safety, underscoring their limitations in practical applications. By uncovering these challenges, our work highlights the complexities of maintaining safety alignment during fine-tuning and offers guidance to help developers balance utility and safety in LLMs. Datasets and fine-tuning code used in our experiments can be found in https://github.com/GuanlinLee/llm_instruction_tuning.
EDMB: Edge Detector with Mamba
Jan 08, 2025Transformer-based models have made significant progress in edge detection, but their high computational cost is prohibitive. Recently, vision Mamba have shown excellent ability in efficiently capturing long-range dependencies. Drawing inspiration from this, we propose a novel edge detector with Mamba, termed EDMB, to efficiently generate high-quality multi-granularity edges. In EDMB, Mamba is combined with a global-local architecture, therefore it can focus on both global information and fine-grained cues. The fine-grained cues play a crucial role in edge detection, but are usually ignored by ordinary Mamba. We design a novel decoder to construct learnable Gaussian distributions by fusing global features and fine-grained features. And the multi-grained edges are generated by sampling from the distributions. In order to make multi-granularity edges applicable to single-label data, we introduce Evidence Lower Bound loss to supervise the learning of the distributions. On the multi-label dataset BSDS500, our proposed EDMB achieves competitive single-granularity ODS 0.837 and multi-granularity ODS 0.851 without multi-scale test or extra PASCAL-VOC data. Remarkably, EDMB can be extended to single-label datasets such as NYUDv2 and BIPED. The source code is available at https://github.com/Li-yachuan/EDMB.
Semi-LLIE: Semi-supervised Contrastive Learning with Mamba-based Low-light Image Enhancement
Sep 25, 2024
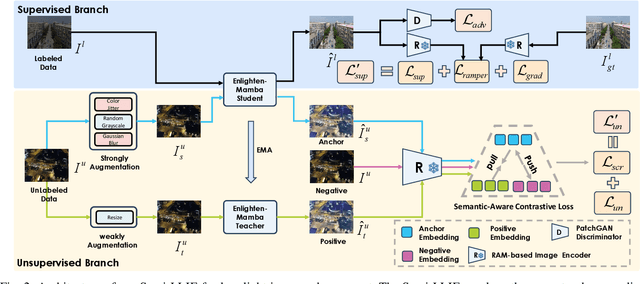
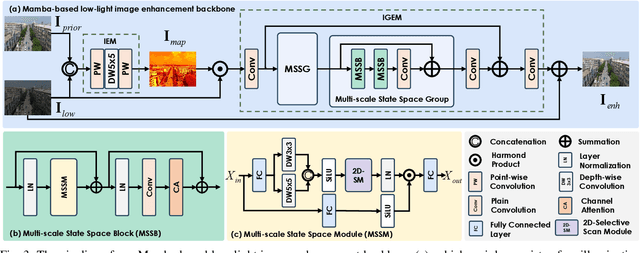

Despite the impressive advancements made in recent low-light image enhancement techniques, the scarcity of paired data has emerged as a significant obstacle to further advancements. This work proposes a mean-teacher-based semi-supervised low-light enhancement (Semi-LLIE) framework that integrates the unpaired data into model training. The mean-teacher technique is a prominent semi-supervised learning method, successfully adopted for addressing high-level and low-level vision tasks. However, two primary issues hinder the naive mean-teacher method from attaining optimal performance in low-light image enhancement. Firstly, pixel-wise consistency loss is insufficient for transferring realistic illumination distribution from the teacher to the student model, which results in color cast in the enhanced images. Secondly, cutting-edge image enhancement approaches fail to effectively cooperate with the mean-teacher framework to restore detailed information in dark areas due to their tendency to overlook modeling structured information within local regions. To mitigate the above issues, we first introduce a semantic-aware contrastive loss to faithfully transfer the illumination distribution, contributing to enhancing images with natural colors. Then, we design a Mamba-based low-light image enhancement backbone to effectively enhance Mamba's local region pixel relationship representation ability with a multi-scale feature learning scheme, facilitating the generation of images with rich textural details. Further, we propose novel perceptive loss based on the large-scale vision-language Recognize Anything Model (RAM) to help generate enhanced images with richer textual details. The experimental results indicate that our Semi-LLIE surpasses existing methods in both quantitative and qualitative metrics.
ART: Automatic Red-teaming for Text-to-Image Models to Protect Benign Users
May 24, 2024
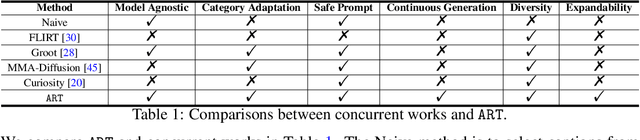
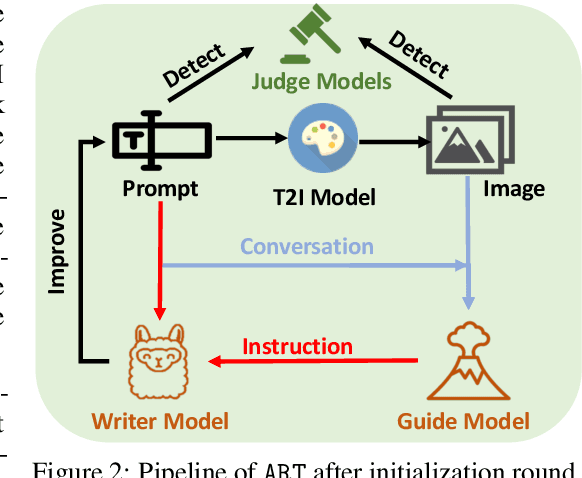

Large-scale pre-trained generative models are taking the world by storm, due to their abilities in generating creative content. Meanwhile, safeguards for these generative models are developed, to protect users' rights and safety, most of which are designed for large language models. Existing methods primarily focus on jailbreak and adversarial attacks, which mainly evaluate the model's safety under malicious prompts. Recent work found that manually crafted safe prompts can unintentionally trigger unsafe generations. To further systematically evaluate the safety risks of text-to-image models, we propose a novel Automatic Red-Teaming framework, ART. Our method leverages both vision language model and large language model to establish a connection between unsafe generations and their prompts, thereby more efficiently identifying the model's vulnerabilities. With our comprehensive experiments, we reveal the toxicity of the popular open-source text-to-image models. The experiments also validate the effectiveness, adaptability, and great diversity of ART. Additionally, we introduce three large-scale red-teaming datasets for studying the safety risks associated with text-to-image models. Datasets and models can be found in https://github.com/GuanlinLee/ART.
TableLLM: Enabling Tabular Data Manipulation by LLMs in Real Office Usage Scenarios
Apr 01, 2024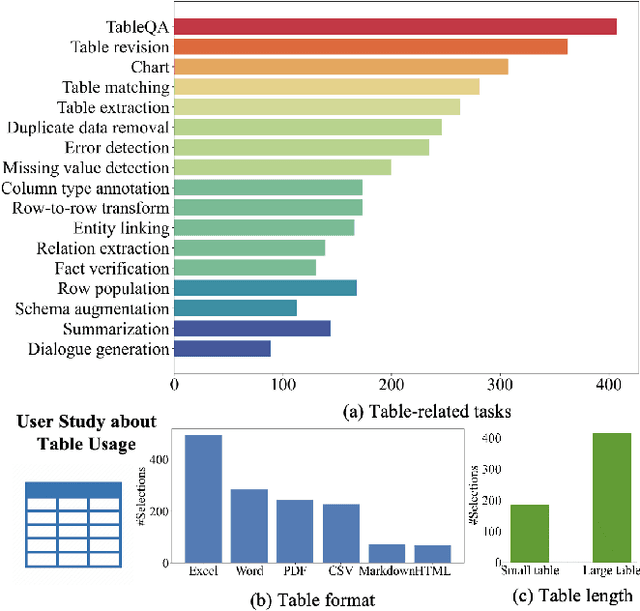

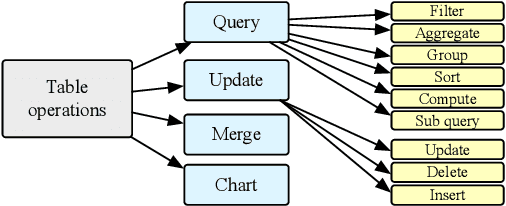
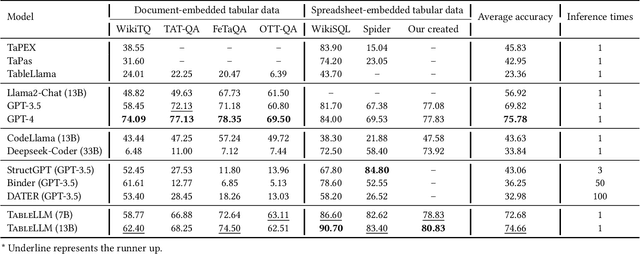
We introduce TableLLM, a robust large language model (LLM) with 13 billion parameters, purpose-built for proficiently handling tabular data manipulation tasks, whether they are embedded within documents or spreadsheets, catering to real-world office scenarios. We propose a distant supervision method for training, which comprises a reasoning process extension strategy, aiding in training LLMs to understand reasoning patterns more effectively as well as a cross-way validation strategy, ensuring the quality of the automatically generated data. To evaluate the performance of TableLLM, we have crafted a benchmark tailored to address both document and spreadsheet formats as well as constructed a well-organized evaluation pipeline capable of handling both scenarios. Thorough evaluations underscore the advantages of TableLLM when compared to various existing general-purpose and tabular data-focused LLMs. We have publicly released the model checkpoint, source code, benchmarks, and a web application for user interaction.Our codes and data are publicly available at https://github.com/TableLLM/TableLLM.
PRIME: Protect Your Videos From Malicious Editing
Feb 02, 2024
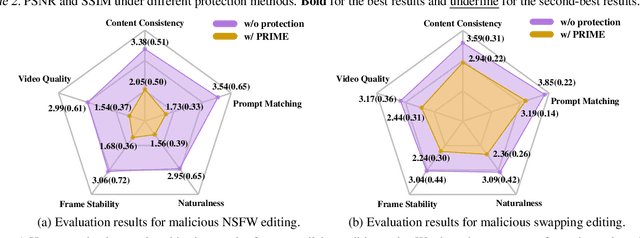


With the development of generative models, the quality of generated content keeps increasing. Recently, open-source models have made it surprisingly easy to manipulate and edit photos and videos, with just a few simple prompts. While these cutting-edge technologies have gained popularity, they have also given rise to concerns regarding the privacy and portrait rights of individuals. Malicious users can exploit these tools for deceptive or illegal purposes. Although some previous works focus on protecting photos against generative models, we find there are still gaps between protecting videos and images in the aspects of efficiency and effectiveness. Therefore, we introduce our protection method, PRIME, to significantly reduce the time cost and improve the protection performance. Moreover, to evaluate our proposed protection method, we consider both objective metrics and human subjective metrics. Our evaluation results indicate that PRIME only costs 8.3% GPU hours of the cost of the previous state-of-the-art method and achieves better protection results on both human evaluation and objective metrics. Code can be found in https://github.com/GuanlinLee/prime.
Singular Regularization with Information Bottleneck Improves Model's Adversarial Robustness
Dec 04, 2023Adversarial examples are one of the most severe threats to deep learning models. Numerous works have been proposed to study and defend adversarial examples. However, these works lack analysis of adversarial information or perturbation, which cannot reveal the mystery of adversarial examples and lose proper interpretation. In this paper, we aim to fill this gap by studying adversarial information as unstructured noise, which does not have a clear pattern. Specifically, we provide some empirical studies with singular value decomposition, by decomposing images into several matrices, to analyze adversarial information for different attacks. Based on the analysis, we propose a new module to regularize adversarial information and combine information bottleneck theory, which is proposed to theoretically restrict intermediate representations. Therefore, our method is interpretable. Moreover, the fashion of our design is a novel principle that is general and unified. Equipped with our new module, we evaluate two popular model structures on two mainstream datasets with various adversarial attacks. The results indicate that the improvement in robust accuracy is significant. On the other hand, we prove that our method is efficient with only a few additional parameters and able to be explained under regional faithfulness analysis.