 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeART: Automatic Red-teaming for Text-to-Image Models to Protect Benign Users
Paper and Code

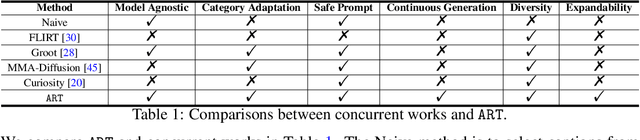
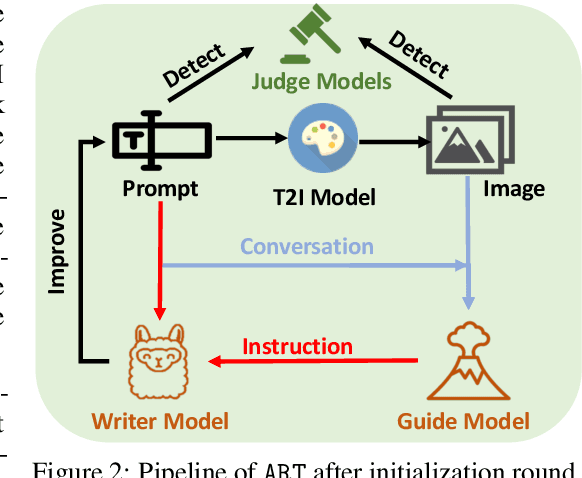

Large-scale pre-trained generative models are taking the world by storm, due to their abilities in generating creative content. Meanwhile, safeguards for these generative models are developed, to protect users' rights and safety, most of which are designed for large language models. Existing methods primarily focus on jailbreak and adversarial attacks, which mainly evaluate the model's safety under malicious prompts. Recent work found that manually crafted safe prompts can unintentionally trigger unsafe generations. To further systematically evaluate the safety risks of text-to-image models, we propose a novel Automatic Red-Teaming framework, ART. Our method leverages both vision language model and large language model to establish a connection between unsafe generations and their prompts, thereby more efficiently identifying the model's vulnerabilities. With our comprehensive experiments, we reveal the toxicity of the popular open-source text-to-image models. The experiments also validate the effectiveness, adaptability, and great diversity of ART. Additionally, we introduce three large-scale red-teaming datasets for studying the safety risks associated with text-to-image models. Datasets and models can be found in https://github.com/GuanlinLee/ART.